 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoInst: Automatic Instance-Based Segmentation of LiDAR 3D Scans
Mar 24, 2024



Recently, progress in acquisition equipment such as LiDAR sensors has enabled sensing increasingly spacious outdoor 3D environments. Making sense of such 3D acquisitions requires fine-grained scene understanding, such as constructing instance-based 3D scene segmentations. Commonly, a neural network is trained for this task; however, this requires access to a large, densely annotated dataset, which is widely known to be challenging to obtain. To address this issue, in this work we propose to predict instance segmentations for 3D scenes in an unsupervised way, without relying on ground-truth annotations. To this end, we construct a learning framework consisting of two components: (1) a pseudo-annotation scheme for generating initial unsupervised pseudo-labels; and (2) a self-training algorithm for instance segmentation to fit robust, accurate instances from initial noisy proposals. To enable generating 3D instance mask proposals, we construct a weighted proxy-graph by connecting 3D points with edges integrating multi-modal image- and point-based self-supervised features, and perform graph-cuts to isolate individual pseudo-instances. We then build on a state-of-the-art point-based architecture and train a 3D instance segmentation model, resulting in significant refinement of initial proposals. To scale to arbitrary complexity 3D scenes, we design our algorithm to operate on local 3D point chunks and construct a merging step to generate scene-level instance segmentations. Experiments on the challenging SemanticKITTI benchmark demonstrate the potential of our approach, where it attains 13.3% higher Average Precision and 9.1% higher F1 score compared to the best-performing baseline. The code will be made publicly available at https://github.com/artonson/autoinst.
Combined Registration and Fusion of Evidential Occupancy Grid Maps for Live Digital Twins of Traffic
Apr 07, 2023


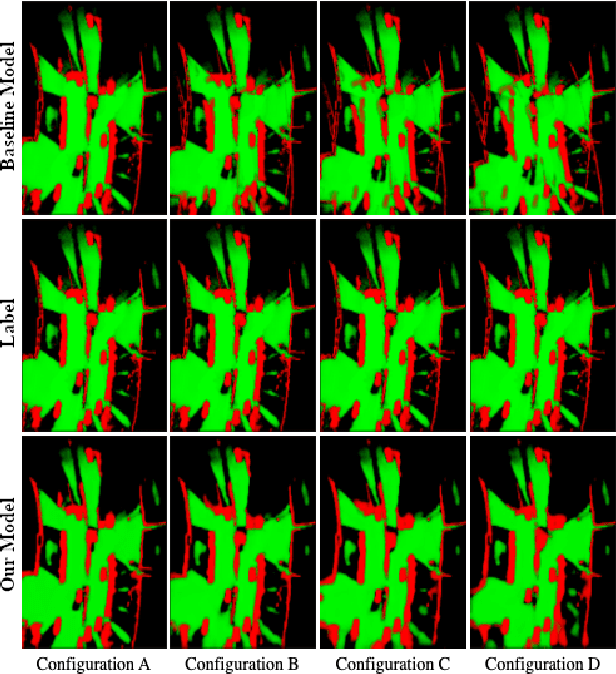
Cooperation of automated vehicles (AVs) can improve safety, efficiency and comfort in traffic. Digital twins of Cooperative Intelligent Transport Systems (C-ITS) play an important role in monitoring, managing and improving traffic. Computing a live digital twin of traffic requires as input live perception data of preferably multiple connected entities such as automated vehicles (AVs). One such type of perception data are evidential occupancy grid maps (OGMs). The computation of a digital twin involves their spatiotemporal alignment and fusion. In this work, we focus on the spatial alignment, also known as registration, and fusion of evidential occupancy grid maps of multiple automated vehicles. While there exists extensive research on the synchronization and fusion of object-based environment representations, the registration and fusion of OGMs originating from multiple connected vehicles has not been investigated much. We propose a methodology that involves training a deep neural network (DNN) to predict a fused evidential OGM from two OGMs computed by different AVs. The output includes an estimate of the first- and second-order uncertainty. We demonstrate that the DNN trained with synthetic data only outperforms a baseline approach based on coordinate transformation and combination rules also on real-world data. Experimental results on synthetic data show that our approach is able to compensate for spatial misalignments of up to 5 meters and 20 degrees.