 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableDPT: Temporal Stable Monocular Video Depth Estimation
Jan 06, 2026Applying single image Monocular Depth Estimation (MDE) models to video sequences introduces significant temporal instability and flickering artifacts. We propose a novel approach that adapts any state-of-the-art image-based (depth) estimation model for video processing by integrating a new temporal module - trainable on a single GPU in a few days. Our architecture StableDPT builds upon an off-the-shelf Vision Transformer (ViT) encoder and enhances the Dense Prediction Transformer (DPT) head. The core of our contribution lies in the temporal layers within the head, which use an efficient cross-attention mechanism to integrate information from keyframes sampled across the entire video sequence. This allows the model to capture global context and inter-frame relationships leading to more accurate and temporally stable depth predictions. Furthermore, we propose a novel inference strategy for processing videos of arbitrary length avoiding the scale misalignment and redundant computations associated with overlapping windows used in other methods. Evaluations on multiple benchmark datasets demonstrate improved temporal consistency, competitive state-of-the-art performance and on top 2x faster processing in real-world scenarios.
BetterDepth: Plug-and-Play Diffusion Refiner for Zero-Shot Monocular Depth Estimation
Jul 25, 2024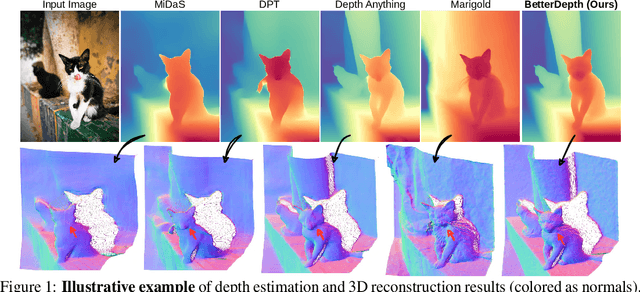

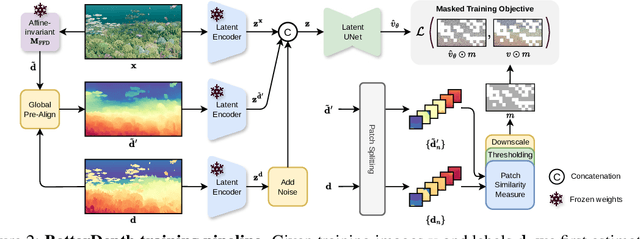
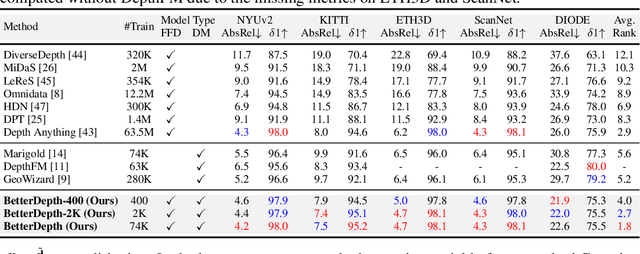
By training over large-scale datasets, zero-shot monocular depth estimation (MDE) methods show robust performance in the wild but often suffer from insufficiently precise details. Although recent diffusion-based MDE approaches exhibit appealing detail extraction ability, they still struggle in geometrically challenging scenes due to the difficulty of gaining robust geometric priors from diverse datasets. To leverage the complementary merits of both worlds, we propose BetterDepth to efficiently achieve geometrically correct affine-invariant MDE performance while capturing fine-grained details. Specifically, BetterDepth is a conditional diffusion-based refiner that takes the prediction from pre-trained MDE models as depth conditioning, in which the global depth context is well-captured, and iteratively refines details based on the input image. For the training of such a refiner, we propose global pre-alignment and local patch masking methods to ensure the faithfulness of BetterDepth to depth conditioning while learning to capture fine-grained scene details. By efficient training on small-scale synthetic datasets, BetterDepth achieves state-of-the-art zero-shot MDE performance on diverse public datasets and in-the-wild scenes. Moreover, BetterDepth can improve the performance of other MDE models in a plug-and-play manner without additional re-training.
Dilemma First Search for Effortless Optimization of NP-Hard Problems
Sep 12, 2016
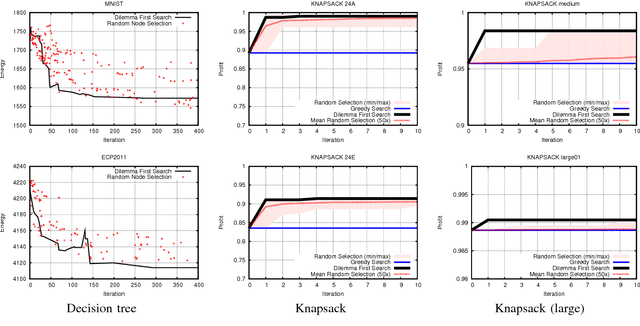

To tackle the exponentiality associated with NP-hard problems, two paradigms have been proposed. First, Branch & Bound, like Dynamic Programming, achieve efficient exact inference but requires extensive information and analysis about the problem at hand. Second, meta-heuristics are easier to implement but comparatively inefficient. As a result, a number of problems have been left unoptimized and plain greedy solutions are used. We introduce a theoretical framework and propose a powerful yet simple search method called Dilemma First Search (DFS). DFS exploits the decision heuristic needed for the greedy solution for further optimization. DFS is useful when it is hard to design efficient exact inference. We evaluate DFS on two problems: First, the Knapsack problem, for which efficient algorithms exist, serves as a toy example. Second, Decision Tree inference, where state-of-the-art algorithms rely on the greedy or randomness-based solutions. We further show that decision trees benefit from optimizations that are performed in a fraction of the iterations required by a random-based search.
Efficient Volumetric Fusion of Airborne and Street-Side Data for Urban Reconstruction
Sep 05, 2016



Airborne acquisition and on-road mobile mapping provide complementary 3D information of an urban landscape: the former acquires roof structures, ground, and vegetation at a large scale, but lacks the facade and street-side details, while the latter is incomplete for higher floors and often totally misses out on pedestrian-only areas or undriven districts. In this work, we introduce an approach that efficiently unifies a detailed street-side Structure-from-Motion (SfM) or Multi-View Stereo (MVS) point cloud and a coarser but more complete point cloud from airborne acquisition in a joint surface mesh. We propose a point cloud blending and a volumetric fusion based on ray casting across a 3D tetrahedralization (3DT), extended with data reduction techniques to handle large datasets. To the best of our knowledge, we are the first to adopt a 3DT approach for airborne/street-side data fusion. Our pipeline exploits typical characteristics of airborne and ground data, and produces a seamless, watertight mesh that is both complete and detailed. Experiments on 3D urban data from multiple sources and different data densities show the effectiveness and benefits of our approach.