 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoker Arena: Multi-Axis Profiling of Strategic Reasoning and Memory in LLMs
Jun 11, 2026Strategic reasoning under uncertainty underpins consequential decisions in negotiation, finance, and policy, but prevailing game-play benchmarks collapse heterogeneous reasoning dimensions into a single scalar, leaving the capability structure of frontier LLMs unexamined. We introduce Poker Arena, a no-limit Texas Hold'em tournament platform that couples a three-layer memory architecture (within-hand, session, and cross-session) with a nine-axis cognitive profile decomposing strategic reasoning into interpretable dimensions such as bet-sizing calibration and positional awareness. We evaluate seven frontier models across 50 sessions of 1,000 hands and a controlled memory ablation; tournament chips and aggregate axis score order the field differently: Claude Opus 4.6 wins +$15,730 chips with 14 first-place finishes, yet ranks only fifth of seven on mean axis score, while persistent memory helps some models and hurts others. These findings show that multi-axis evaluation surfaces capability structure that scalar leaderboards systematically misrank, with cross-dimensional consistency outweighing peak performance on any single axis.
Do Vision-Language Models See or Guess? Measuring and Reducing Textual-Prior Reliance with a Phrasing-Controlled Benchmark
Jun 09, 2026Vision-language models (VLMs) are increasingly deployed where answers must follow from what is in the image, yet they often answer from textual priors, the question's phrasing together with memorized world knowledge, rather than from the image itself, which inflates benchmark scores and yields confident but ungrounded answers. Existing benchmarks rarely isolate this behavior, since each image is usually paired with a single fixed question. To measure the reliance, we build a 540-image benchmark across six reasoning categories and generate four question variants over the same images, so that phrasing rather than image content is the controlled variable. The hardest variant is written directly from the image to minimize text leakage. We benchmark eleven VLMs spanning small open-weight models to large closed-source systems: every model degrades on the hardest variant, and open models fall furthest. Our central diagnostic is a no-image ablation, which collapses the open-weight models to their text-only floor (1 to 9 percent). Three further analyses, LLM-rated difficulty, low base-to-final textual similarity, and human re-annotation, corroborate genuine image-dependence. In-context exemplars that match how a variant was built recover the most accuracy, and GRPO post-training of a small VLM yields consistent gains across all four variants that transfer to a held-out out-of-distribution set. Textual-prior reliance is measurable and partly trainable away.
Text2Arch: A Dataset for Generating Scientific Architecture Diagrams from Natural Language Descriptions
Apr 16, 2026Communicating complex system designs or scientific processes through text alone is inefficient and prone to ambiguity. A system that automatically generates scientific architecture diagrams from text with high semantic fidelity can be useful in multiple applications like enterprise architecture visualization, AI-driven software design, and educational content creation. Hence, in this paper, we focus on leveraging language models to perform semantic understanding of the input text description to generate intermediate code that can be processed to generate high-fidelity architecture diagrams. Unfortunately, no clean large-scale open-access dataset exists, implying lack of any effective open models for this task. Hence, we contribute a comprehensive dataset, \system, comprising scientific architecture images, their corresponding textual descriptions, and associated DOT code representations. Leveraging this resource, we fine-tune a suite of small language models, and also perform in-context learning using GPT-4o. Through extensive experimentation, we show that \system{} models significantly outperform existing baseline models like DiagramAgent and perform at par with in-context learning-based generations from GPT-4o. We make the code, data and models publicly available.
SIDiffAgent: Self-Improving Diffusion Agent
Feb 02, 2026Text-to-image diffusion models have revolutionized generative AI, enabling high-quality and photorealistic image synthesis. However, their practical deployment remains hindered by several limitations: sensitivity to prompt phrasing, ambiguity in semantic interpretation (e.g., ``mouse" as animal vs. a computer peripheral), artifacts such as distorted anatomy, and the need for carefully engineered input prompts. Existing methods often require additional training and offer limited controllability, restricting their adaptability in real-world applications. We introduce Self-Improving Diffusion Agent (SIDiffAgent), a training-free agentic framework that leverages the Qwen family of models (Qwen-VL, Qwen-Image, Qwen-Edit, Qwen-Embedding) to address these challenges. SIDiffAgent autonomously manages prompt engineering, detects and corrects poor generations, and performs fine-grained artifact removal, yielding more reliable and consistent outputs. It further incorporates iterative self-improvement by storing a memory of previous experiences in a database. This database of past experiences is then used to inject prompt-based guidance at each stage of the agentic pipeline. \modelour achieved an average VQA score of 0.884 on GenAIBench, significantly outperforming open-source, proprietary models and agentic methods. We will publicly release our code upon acceptance.
ViT Registers and Fractal ViT
Jan 21, 2026Drawing inspiration from recent findings including surprisingly decent performance of transformers without positional encoding (NoPE) in the domain of language models and how registers (additional throwaway tokens not tied to input) may improve the performance of large vision transformers (ViTs), we invent and test a variant of ViT called fractal ViT that breaks permutation invariance among the tokens by applying an attention mask between the regular tokens and ``summary tokens'' similar to registers, in isolation or in combination with various positional encodings. These models do not improve upon ViT with registers, highlighting the fact that these findings may be scale, domain, or application-specific.
IPO: Your Language Model is Secretly a Preference Classifier
Feb 22, 2025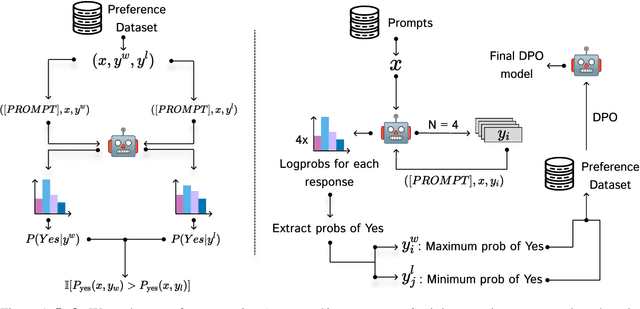
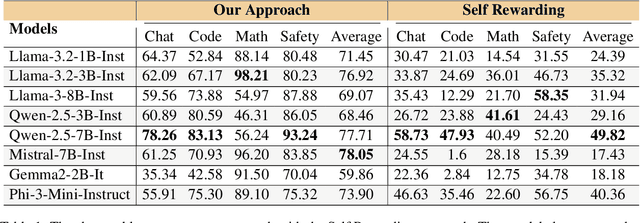

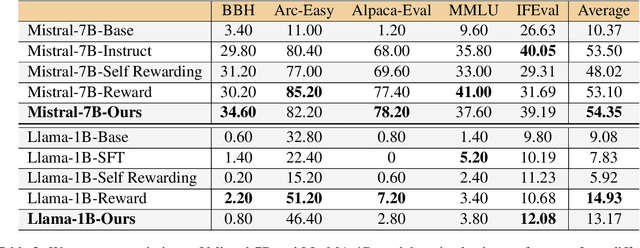
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. While it enables LLMs to achieve human-level alignment, it often incurs significant computational and financial costs due to its reliance on training external reward models or human-labeled preferences. In this work, we propose \textbf{Implicit Preference Optimization (IPO)}, an alternative approach that leverages generative LLMs as preference classifiers, thereby reducing the dependence on external human feedback or reward models to obtain preferences. We conduct a comprehensive evaluation on the preference classification ability of LLMs using RewardBench, assessing models across different sizes, architectures, and training levels to validate our hypothesis. Furthermore, we investigate the self-improvement capabilities of LLMs by generating multiple responses for a given instruction and employing the model itself as a preference classifier for Direct Preference Optimization (DPO)-based training. Our findings demonstrate that models trained through IPO achieve performance comparable to those utilizing state-of-the-art reward models for obtaining preferences.
Adaptive Urban Planning: A Hybrid Framework for Balanced City Development
Dec 19, 2024



Urban planning faces a critical challenge in balancing city-wide infrastructure needs with localized demographic preferences, particularly in rapidly developing regions. Although existing approaches typically focus on top-down optimization or bottom-up community planning, only some frameworks successfully integrate both perspectives. Our methodology employs a two-tier approach: First, a deterministic solver optimizes basic infrastructure requirements in the city region. Second, four specialized planning agents, each representing distinct sub-regions, propose demographic-specific modifications to a master planner. The master planner then evaluates and integrates these suggestions to ensure cohesive urban development. We validate our framework using a newly created dataset comprising detailed region and sub-region maps from three developing cities in India, focusing on areas undergoing rapid urbanization. The results demonstrate that this hybrid approach enables more nuanced urban development while maintaining overall city functionality.
LoRA-Mini : Adaptation Matrices Decomposition and Selective Training
Nov 24, 2024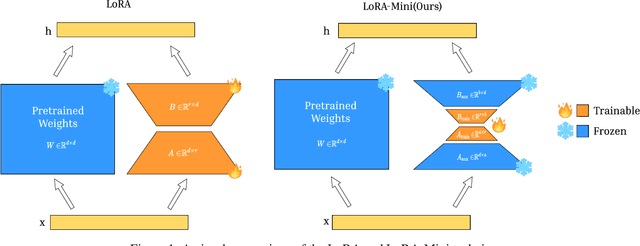
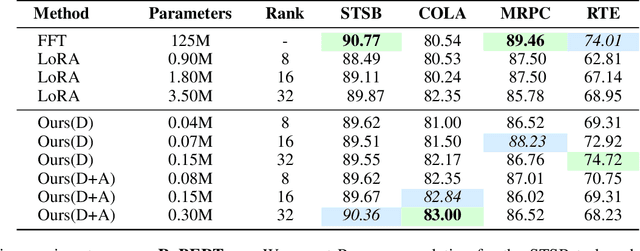

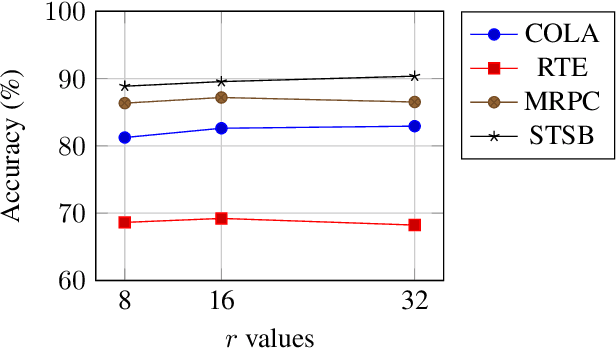
The rapid advancements in large language models (LLMs) have revolutionized natural language processing, creating an increased need for efficient, task-specific fine-tuning methods. Traditional fine-tuning of LLMs involves updating a large number of parameters, which is computationally expensive and memory-intensive. Low-Rank Adaptation (LoRA) has emerged as a promising solution, enabling parameter-efficient fine-tuning by reducing the number of trainable parameters. However, while LoRA reduces the number of trainable parameters, LoRA modules still create significant storage challenges. We propose LoRA-Mini, an optimized adaptation of LoRA that improves parameter efficiency by splitting low-rank matrices into four parts, with only the two inner matrices being trainable. This approach achieves upto a 20x reduction compared to standard LoRA in the number of trainable parameters while preserving performance levels comparable to standard LoRA, addressing both computational and storage efficiency in LLM fine-tuning.
Are VLMs Really Blind
Oct 29, 2024

Vision Language Models excel in handling a wide range of complex tasks, including Optical Character Recognition (OCR), Visual Question Answering (VQA), and advanced geometric reasoning. However, these models fail to perform well on low-level basic visual tasks which are especially easy for humans. Our goal in this work was to determine if these models are truly "blind" to geometric reasoning or if there are ways to enhance their capabilities in this area. Our work presents a novel automatic pipeline designed to extract key information from images in response to specific questions. Instead of just relying on direct VQA, we use question-derived keywords to create a caption that highlights important details in the image related to the question. This caption is then used by a language model to provide a precise answer to the question without requiring external fine-tuning.
Give me a hint: Can LLMs take a hint to solve math problems?
Oct 08, 2024



While many state-of-the-art LLMs have shown poor logical and basic mathematical reasoning, recent works try to improve their problem-solving abilities using prompting techniques. We propose giving "hints" to improve the language model's performance on advanced mathematical problems, taking inspiration from how humans approach math pedagogically. We also test the model's adversarial robustness to wrong hints. We demonstrate the effectiveness of our approach by evaluating various LLMs, presenting them with a diverse set of problems of different difficulties and topics from the MATH dataset and comparing against techniques such as one-shot, few-shot, and chain of thought prompting.