 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Mini : Adaptation Matrices Decomposition and Selective Training
Paper and Code
Nov 24, 2024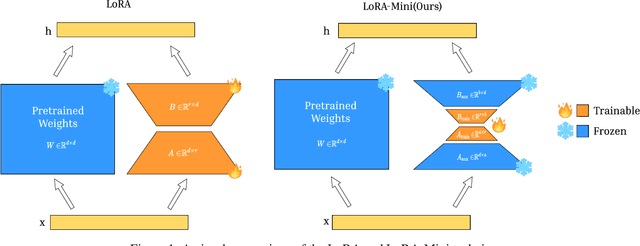
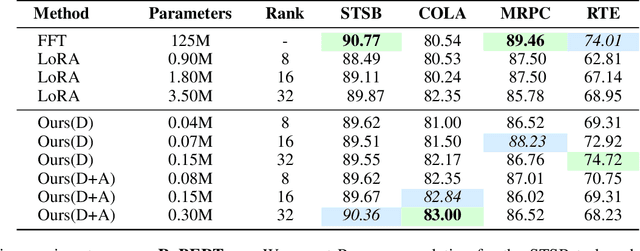

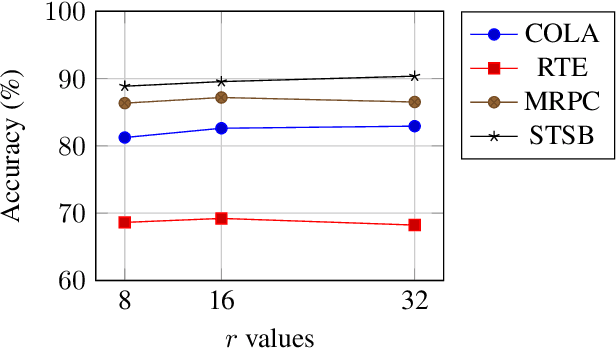
The rapid advancements in large language models (LLMs) have revolutionized natural language processing, creating an increased need for efficient, task-specific fine-tuning methods. Traditional fine-tuning of LLMs involves updating a large number of parameters, which is computationally expensive and memory-intensive. Low-Rank Adaptation (LoRA) has emerged as a promising solution, enabling parameter-efficient fine-tuning by reducing the number of trainable parameters. However, while LoRA reduces the number of trainable parameters, LoRA modules still create significant storage challenges. We propose LoRA-Mini, an optimized adaptation of LoRA that improves parameter efficiency by splitting low-rank matrices into four parts, with only the two inner matrices being trainable. This approach achieves upto a 20x reduction compared to standard LoRA in the number of trainable parameters while preserving performance levels comparable to standard LoRA, addressing both computational and storage efficiency in LLM fine-tuning.