 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPO: Your Language Model is Secretly a Preference Classifier
Paper and Code
Feb 22, 2025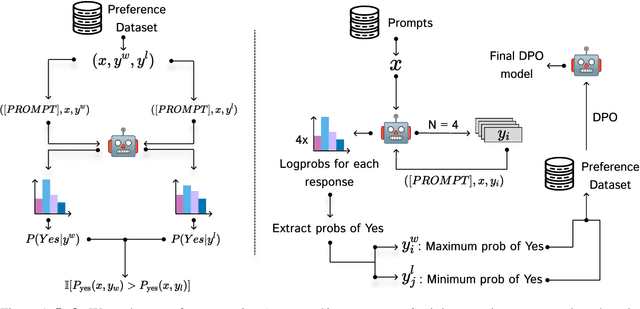
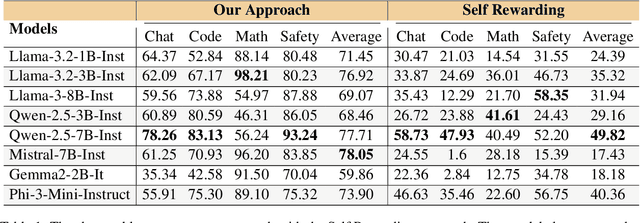

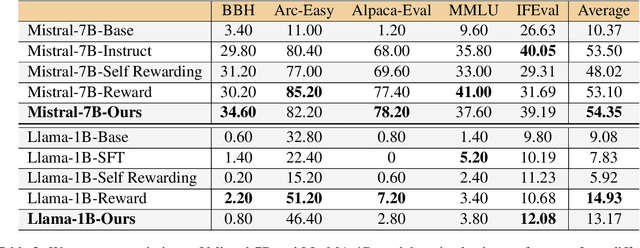
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. While it enables LLMs to achieve human-level alignment, it often incurs significant computational and financial costs due to its reliance on training external reward models or human-labeled preferences. In this work, we propose \textbf{Implicit Preference Optimization (IPO)}, an alternative approach that leverages generative LLMs as preference classifiers, thereby reducing the dependence on external human feedback or reward models to obtain preferences. We conduct a comprehensive evaluation on the preference classification ability of LLMs using RewardBench, assessing models across different sizes, architectures, and training levels to validate our hypothesis. Furthermore, we investigate the self-improvement capabilities of LLMs by generating multiple responses for a given instruction and employing the model itself as a preference classifier for Direct Preference Optimization (DPO)-based training. Our findings demonstrate that models trained through IPO achieve performance comparable to those utilizing state-of-the-art reward models for obtaining preferences.