 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Enhanced Text Classification to Explore Health based Indian Government Policy Tweets
Aug 18, 2020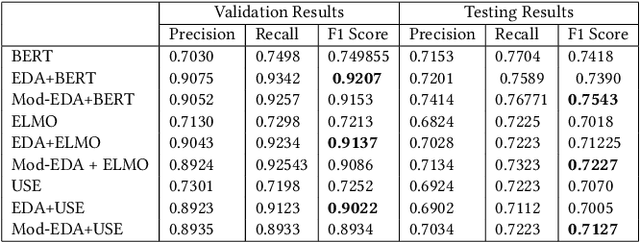
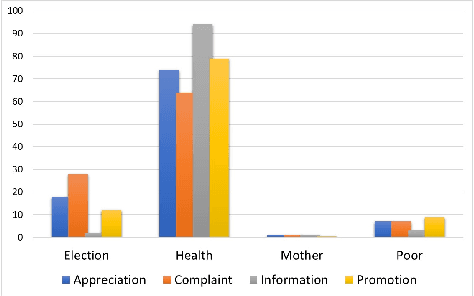
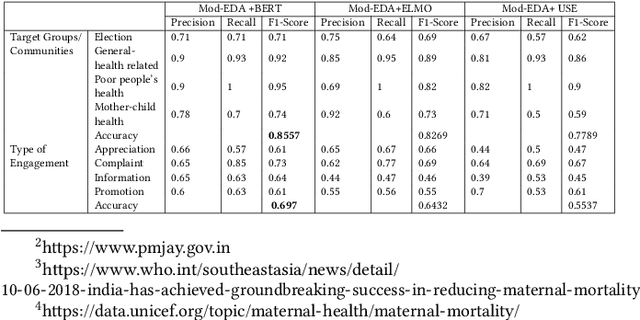
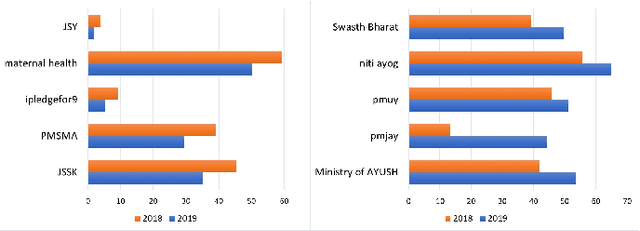
Government-sponsored policy-making and scheme generations is one of the means of protecting and promoting the social, economic, and personal development of the citizens. The evaluation of effectiveness of these schemes done by government only provide the statistical information in terms of facts and figures which do not include the in-depth knowledge of public perceptions, experiences and views on the topic. In this research work, we propose an improved text classification framework that classifies the Twitter data of different health-based government schemes. The proposed framework leverages the language representation models (LR models) BERT, ELMO, and USE. However, these LR models have less real-time applicability due to the scarcity of the ample annotated data. To handle this, we propose a novel GloVe word embeddings and class-specific sentiments based text augmentation approach (named Mod-EDA) which boosts the performance of text classification task by increasing the size of labeled data. Furthermore, the trained model is leveraged to identify the level of engagement of citizens towards these policies in different communities such as middle-income and low-income groups.