 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Robot Reinforcement Learning with Uncertainty-Guided Human Expert Sampling
Dec 16, 2022
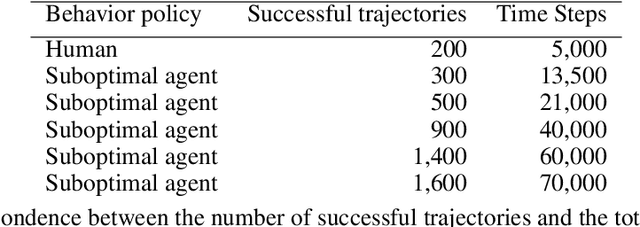
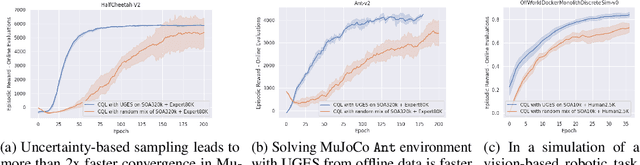

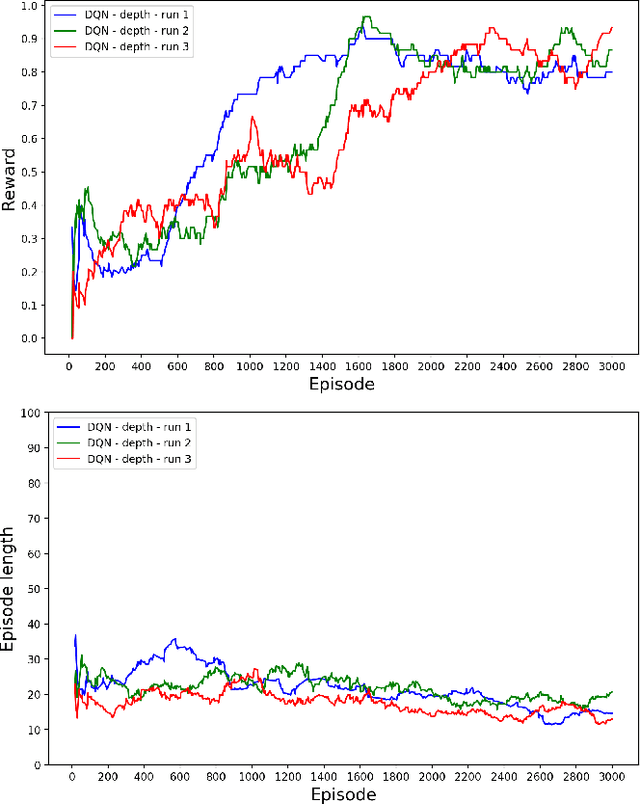
Recent advances in batch (offline) reinforcement learning have shown promising results in learning from available offline data and proved offline reinforcement learning to be an essential toolkit in learning control policies in a model-free setting. An offline reinforcement learning algorithm applied to a dataset collected by a suboptimal non-learning-based algorithm can result in a policy that outperforms the behavior agent used to collect the data. Such a scenario is frequent in robotics, where existing automation is collecting operational data. Although offline learning techniques can learn from data generated by a sub-optimal behavior agent, there is still an opportunity to improve the sample complexity of existing offline reinforcement learning algorithms by strategically introducing human demonstration data into the training process. To this end, we propose a novel approach that uses uncertainty estimation to trigger the injection of human demonstration data and guide policy training towards optimal behavior while reducing overall sample complexity. Our experiments show that this approach is more sample efficient when compared to a naive way of combining expert data with data collected from a sub-optimal agent. We augmented an existing offline reinforcement learning algorithm Conservative Q-Learning with our approach and performed experiments on data collected from MuJoCo and OffWorld Gym learning environments.
Understanding Information Processing in Human Brain by Interpreting Machine Learning Models
Oct 17, 2020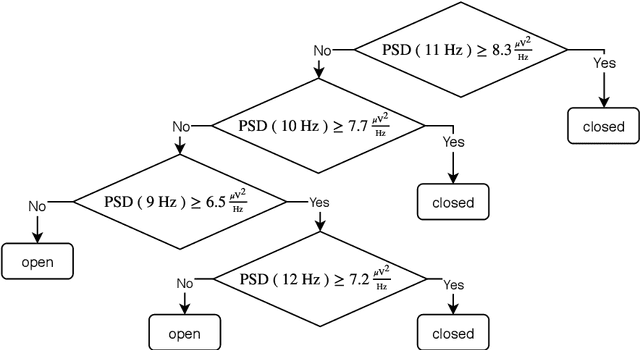

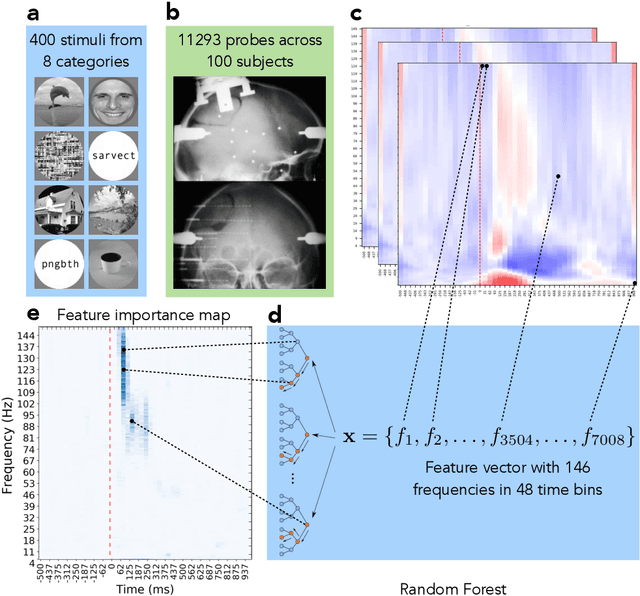

The thesis explores the role machine learning methods play in creating intuitive computational models of neural processing. Combined with interpretability techniques, machine learning could replace human modeler and shift the focus of human effort to extracting the knowledge from the ready-made models and articulating that knowledge into intuitive descroptions of reality. This perspective makes the case in favor of the larger role that exploratory and data-driven approach to computational neuroscience could play while coexisting alongside the traditional hypothesis-driven approach. We exemplify the proposed approach in the context of the knowledge representation taxonomy with three research projects that employ interpretability techniques on top of machine learning methods at three different levels of neural organization. The first study (Chapter 3) explores feature importance analysis of a random forest decoder trained on intracerebral recordings from 100 human subjects to identify spectrotemporal signatures that characterize local neural activity during the task of visual categorization. The second study (Chapter 4) employs representation similarity analysis to compare the neural responses of the areas along the ventral stream with the activations of the layers of a deep convolutional neural network. The third study (Chapter 5) proposes a method that allows test subjects to visually explore the state representation of their neural signal in real time. This is achieved by using a topology-preserving dimensionality reduction technique that allows to transform the neural data from the multidimensional representation used by the computer into a two-dimensional representation a human can grasp. The approach, the taxonomy, and the examples, present a strong case for the applicability of machine learning methods to automatic knowledge discovery in neuroscience.
OffWorld Gym: open-access physical robotics environment for real-world reinforcement learning benchmark and research
Oct 18, 2019
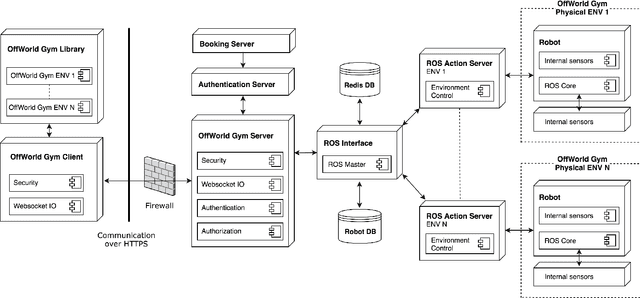
Success stories of applied machine learning can be traced back to the datasets and environments that were put forward as challenges for the community. The challenge that the community sets as a benchmark is usually the challenge that the community eventually solves. The ultimate challenge of reinforcement learning research is to train real agents to operate in the real environment, but until now there has not been a common real-world RL benchmark. In this work, we present a prototype real-world environment from OffWorld Gym -- a collection of real-world environments for reinforcement learning in robotics with free public remote access. Close integration into existing ecosystem allows the community to start using OffWorld Gym without any prior experience in robotics and takes away the burden of managing a physical robotics system, abstracting it under a familiar API. We introduce a navigation task, where a robot has to reach a visual beacon on an uneven terrain using only the camera input and provide baseline results in both the real environment and the simulated replica. To start training, visit https://gym.offworld.ai.
Direct information transfer rate optimisation for SSVEP-based BCI
Jul 19, 2019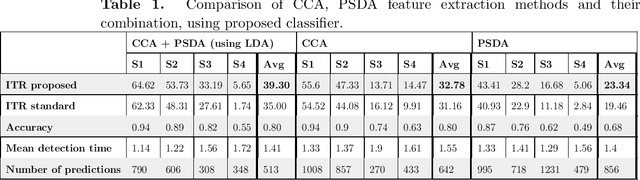


In this work, a classification method for SSVEP-based BCI is proposed. The classification method uses features extracted by traditional SSVEP-based BCI methods and finds optimal discrimination thresholds for each feature to classify the targets. Optimising the thresholds is formalised as a maximisation task of a performance measure of BCIs called information transfer rate (ITR). However, instead of the standard method of calculating ITR, which makes certain assumptions about the data, a more general formula is derived to avoid incorrect ITR calculation when the standard assumptions are not met. This allows the optimal discrimination thresholds to be automatically calculated and thus eliminates the need for manual parameter selection or performing computationally expensive grid searches. The proposed method shows good performance in classifying targets of a BCI, outperforming previously reported results on the same dataset by a factor of 2 in terms of ITR. The highest achieved ITR on the used dataset was 62 bit/min. The proposed method also provides a way to reduce false classifications, which is important in real-world applications.
Visual Hindsight Experience Replay
Jan 31, 2019
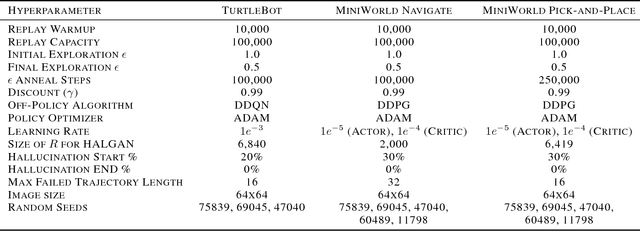
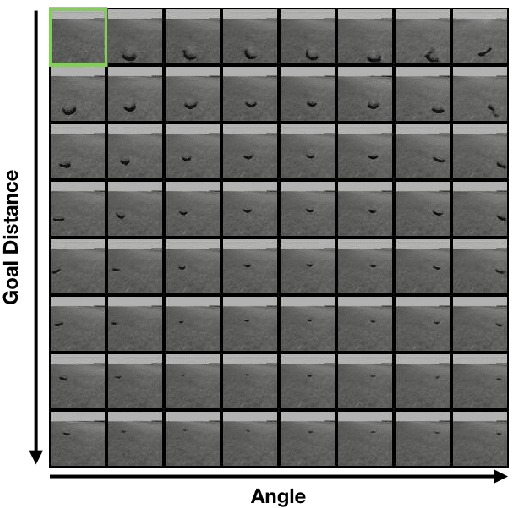

Reinforcement Learning algorithms typically require millions of environment interactions to learn successful policies in sparse reward settings. Hindsight Experience Replay (HER) was introduced as a technique to increase sample efficiency through re-imagining unsuccessful trajectories as successful ones by replacing the originally intended goals. However, this method is not applicable to visual domains where the goal configuration is unknown and must be inferred from observation. In this work, we show how unsuccessful visual trajectories can be hallucinated to be successful using a generative model trained on relatively few snapshots of the goal. As far as we are aware, this is the first work that does so with the agent policy conditioned solely on its state. We then apply this model to training reinforcement learning agents in discrete and continuous settings. We show results on a navigation and pick-and-place task in a 3D environment and on a simulated robotics application. Our method shows marked improvement over standard RL algorithms and baselines derived from prior work.
Combining Static and Dynamic Features for Multivariate Sequence Classification
Dec 20, 2017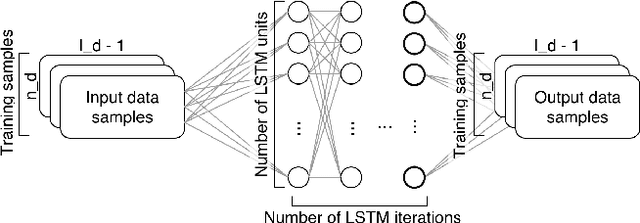
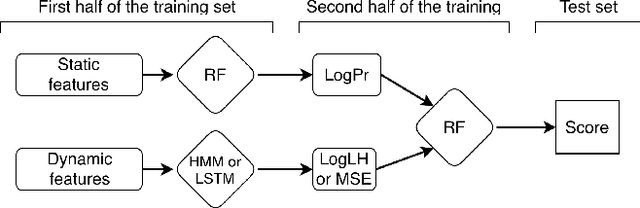
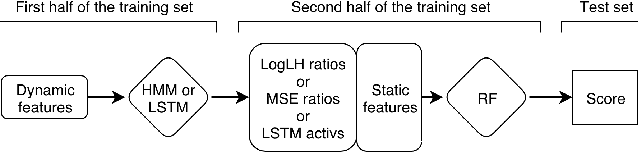
Model precision in a classification task is highly dependent on the feature space that is used to train the model. Moreover, whether the features are sequential or static will dictate which classification method can be applied as most of the machine learning algorithms are designed to deal with either one or another type of data. In real-life scenarios, however, it is often the case that both static and dynamic features are present, or can be extracted from the data. In this work, we demonstrate how generative models such as Hidden Markov Models (HMM) and Long Short-Term Memory (LSTM) artificial neural networks can be used to extract temporal information from the dynamic data. We explore how the extracted information can be combined with the static features in order to improve the classification performance. We evaluate the existing techniques and suggest a hybrid approach, which outperforms other methods on several public datasets.
Multiagent Cooperation and Competition with Deep Reinforcement Learning
Nov 27, 2015
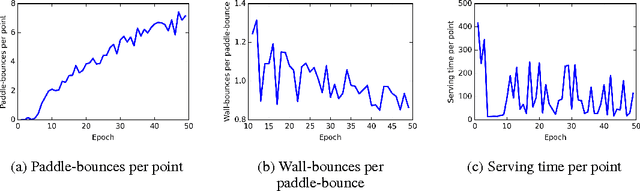


Multiagent systems appear in most social, economical, and political situations. In the present work we extend the Deep Q-Learning Network architecture proposed by Google DeepMind to multiagent environments and investigate how two agents controlled by independent Deep Q-Networks interact in the classic videogame Pong. By manipulating the classical rewarding scheme of Pong we demonstrate how competitive and collaborative behaviors emerge. Competitive agents learn to play and score efficiently. Agents trained under collaborative rewarding schemes find an optimal strategy to keep the ball in the game as long as possible. We also describe the progression from competitive to collaborative behavior. The present work demonstrates that Deep Q-Networks can become a practical tool for studying the decentralized learning of multiagent systems living in highly complex environments.