 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating the effects of speed and delays in end-to-end self-driving
Dec 06, 2023In the behavioral cloning approach to end-to-end driving, a dataset of expert driving is collected and the model learns to guess what the expert would do in different situations. Situations are summarized in observations and the outputs are low or mid-level commands (e.g. brake, throttle, and steering; or trajectories). The models learn to match observations at time T to actions recorded at T or as simultaneously as possible. However, when deploying the models to the real world (or to an asynchronous simulation), the action predicted based on observations at time T gets applied at T + $\Delta$ T. In a variety of cases, $\Delta$ T can be considerable and significantly influence performance. We first demonstrate that driving at two different speeds is effectively two different tasks. Delays partially cause this difference and linearly amplify it. Even without computational delays, actuator delays and slipping due to inertia result in the need to perform actions preemptively when driving fast. The function mapping observations to commands becomes different compared to slow driving. We experimentally show that models trained to drive fast cannot perform the seemingly easier task of driving slow and vice-versa. Good driving models may be judged to be poor due to testing them at "a safe low speed", a task they cannot perform. Secondly, we show how to counteract the effect of delays in end-to-end networks by changing the target labels. This is in contrast to the approaches attempting to minimize the delays, i.e. the cause, not the effect. To exemplify the problems and solutions in the real world, we use 1:10 scale minicars with limited computing power, using behavioral cloning for end-to-end driving. Some of the ideas discussed here may be transferable to the wider context of self-driving, to vehicles with more compute power and end-to-mid or modular approaches.
Controlling Steering with Energy-Based Models
Jan 28, 2023So-called implicit behavioral cloning with energy-based models has shown promising results in robotic manipulation tasks. We tested if the method's advantages carry on to controlling the steering of a real self-driving car with an end-to-end driving model. We performed an extensive comparison of the implicit behavioral cloning approach with explicit baseline approaches, all sharing the same neural network backbone architecture. Baseline explicit models were trained with regression (MAE) loss, classification loss (softmax and cross-entropy on a discretization), or as mixture density networks (MDN). While models using the energy-based formulation performed comparably to baseline approaches in terms of safety driver interventions, they had a higher whiteness measure, indicating higher jerk. To alleviate this, we show two methods that can be used to improve the smoothness of steering. We confirmed that energy-based models handle multimodalities slightly better than simple regression, but this did not translate to significantly better driving ability. We argue that the steering-only road-following task has too few multimodalities to benefit from energy-based models. This shows that applying implicit behavioral cloning to real-world tasks can be challenging, and further investigation is needed to bring out the theoretical advantages of energy-based models.
LiDAR-as-Camera for End-to-End Driving
Jun 30, 2022


The core task of any autonomous driving system is to transform sensory inputs into driving commands. In end-to-end driving, this is achieved via a neural network, with one or multiple cameras as the most commonly used input and low-level driving command, e.g. steering angle, as output. However, depth-sensing has been shown in simulation to make the end-to-end driving task easier. On a real car, combining depth and visual information can be challenging, due to the difficulty of obtaining good spatial and temporal alignment of the sensors. To alleviate alignment problems, Ouster LiDARs can output surround-view LiDAR-images with depth, intensity, and ambient radiation channels. These measurements originate from the same sensor, rendering them perfectly aligned in time and space. We demonstrate that such LiDAR-images are sufficient for the real-car road-following task and perform at least equally to camera-based models in the tested conditions, with the difference increasing when needing to generalize to new weather conditions. In the second direction of study, we reveal that the temporal smoothness of off-policy prediction sequences correlates equally well with actual on-policy driving ability as the commonly used mean absolute error.
A Survey of End-to-End Driving: Architectures and Training Methods
Mar 13, 2020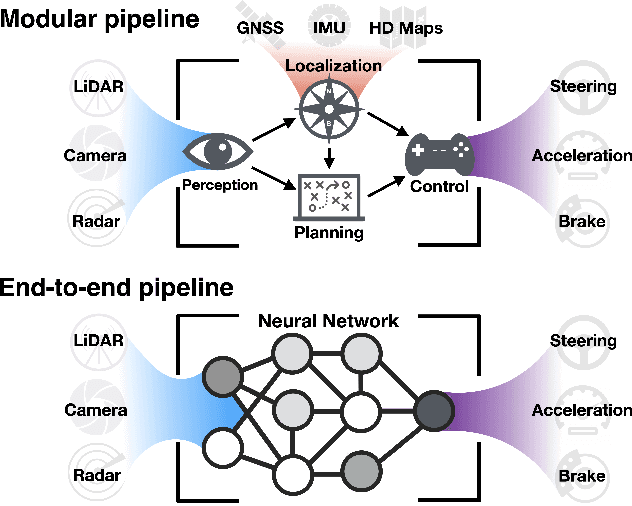
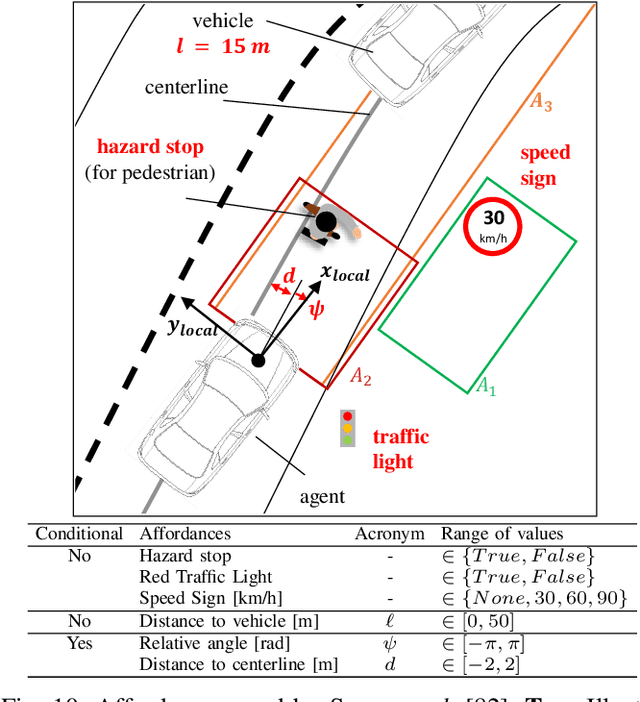


Autonomous driving is of great interest to industry and academia alike. The use of machine learning approaches for autonomous driving has long been studied, but mostly in the context of perception. In this paper we take a deeper look on the so called end-to-end approaches for autonomous driving, where the entire driving pipeline is replaced with a single neural network. We review the learning methods, input and output modalities, network architectures and evaluation schemes in end-to-end driving literature. Interpretability and safety are discussed separately, as they remain challenging for this approach. Beyond providing a comprehensive overview of existing methods, we conclude the review with an architecture that combines the most promising elements of the end-to-end autonomous driving systems.
Perspective Taking in Deep Reinforcement Learning Agents
Jul 03, 2019

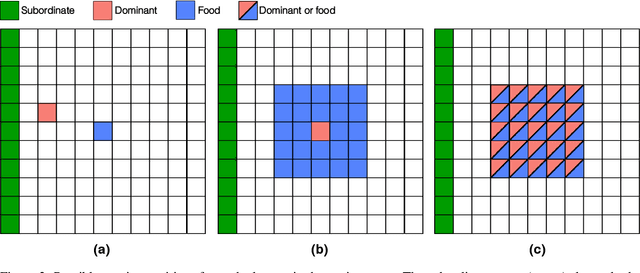

Perspective taking is the ability to take the point of view of another agent. This skill is not unique to humans as it is also displayed by other animals like chimpanzees. It is an essential ability for efficient social interactions, including cooperation, competition, and communication. In this work, we present our progress toward building artificial agents with such abilities. To this end we implemented a perspective taking task that was inspired by experiments done with chimpanzees. We show that agents controlled by artificial neural networks can learn via reinforcement learning to pass simple tests that require perspective taking capabilities. In particular, this ability is more readily learned when the agent has allocentric information about the objects in the environment. Building artificial agents with perspective taking ability will help to reverse engineer how computations underlying theory of mind might be accomplished in our brains.
APES: a Python toolbox for simulating reinforcement learning environments
Aug 31, 2018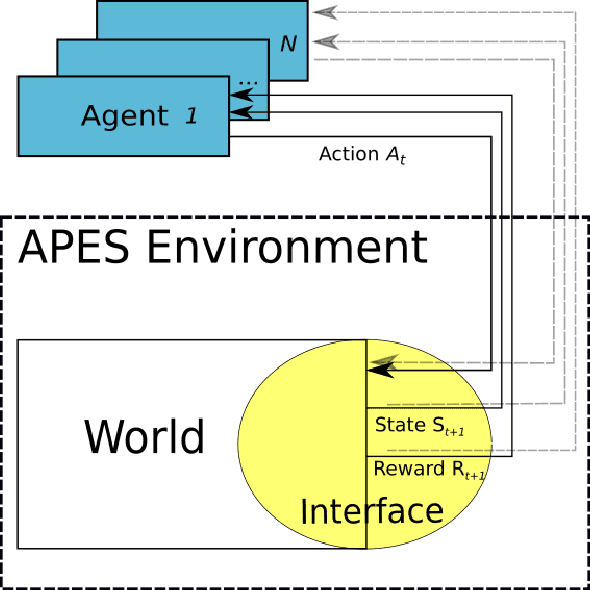



Assisted by neural networks, reinforcement learning agents have been able to solve increasingly complex tasks over the last years. The simulation environment in which the agents interact is an essential component in any reinforcement learning problem. The environment simulates the dynamics of the agents' world and hence provides feedback to their actions in terms of state observations and external rewards. To ease the design and simulation of such environments this work introduces $\texttt{APES}$, a highly customizable and open source package in Python to create 2D grid-world environments for reinforcement learning problems. $\texttt{APES}$ equips agents with algorithms to simulate any field of vision, it allows the creation and positioning of items and rewards according to user-defined rules, and supports the interaction of multiple agents.
Multiagent Cooperation and Competition with Deep Reinforcement Learning
Nov 27, 2015
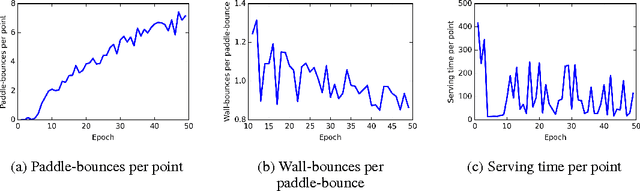


Multiagent systems appear in most social, economical, and political situations. In the present work we extend the Deep Q-Learning Network architecture proposed by Google DeepMind to multiagent environments and investigate how two agents controlled by independent Deep Q-Networks interact in the classic videogame Pong. By manipulating the classical rewarding scheme of Pong we demonstrate how competitive and collaborative behaviors emerge. Competitive agents learn to play and score efficiently. Agents trained under collaborative rewarding schemes find an optimal strategy to keep the ball in the game as long as possible. We also describe the progression from competitive to collaborative behavior. The present work demonstrates that Deep Q-Networks can become a practical tool for studying the decentralized learning of multiagent systems living in highly complex environments.