 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial intelligence and the internal processes of creativity
Dec 05, 2024Artificial intelligence (AI) systems capable of generating creative outputs are reshaping our understanding of creativity. This shift presents an opportunity for creativity researchers to reevaluate the key components of the creative process. In particular, the advanced capabilities of AI underscore the importance of studying the internal processes of creativity. This paper explores the neurobiological machinery that underlies these internal processes and describes the experiential component of creativity. It is concluded that although the products of artificial and human creativity can be similar, the internal processes are different. The paper also discusses how AI may negatively affect the internal processes of human creativity, such as the development of skills, the integration of knowledge, and the diversity of ideas.
How structured are the representations in transformer-based vision encoders? An analysis of multi-object representations in vision-language models
Jun 18, 2024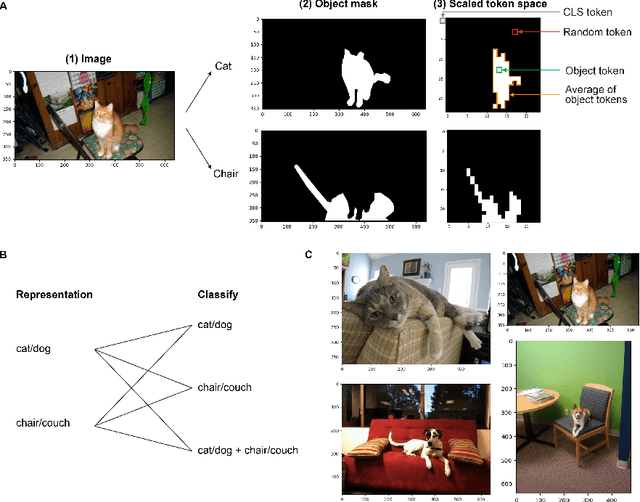
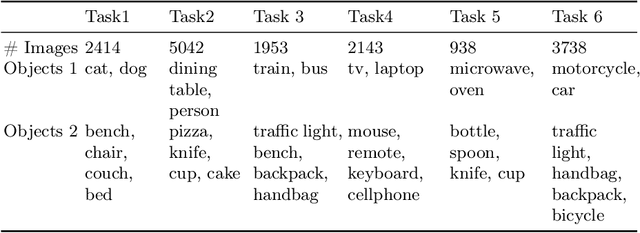
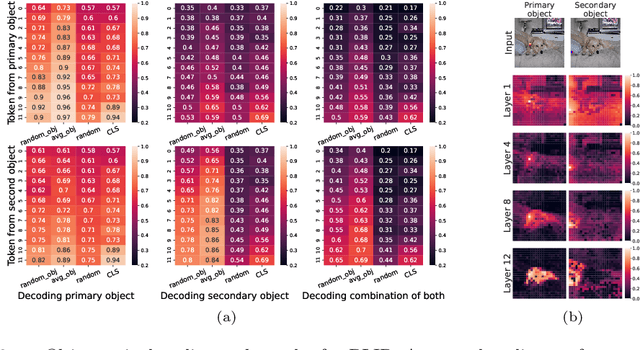
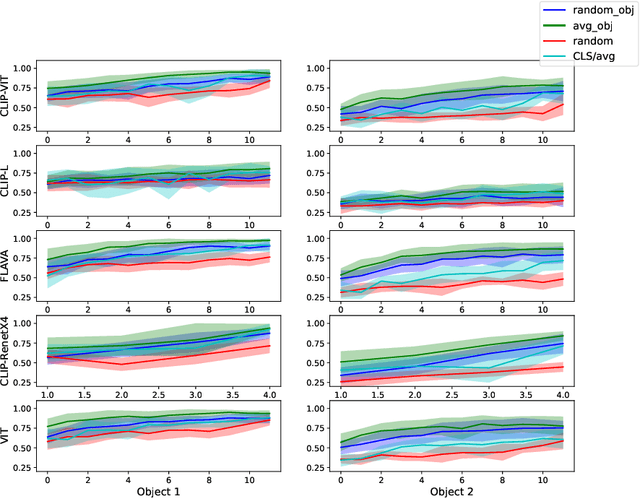
Forming and using symbol-like structured representations for reasoning has been considered essential for generalising over novel inputs. The primary tool that allows generalisation outside training data distribution is the ability to abstract away irrelevant information into a compact form relevant to the task. An extreme form of such abstract representations is symbols. Humans make use of symbols to bind information while abstracting away irrelevant parts to utilise the information consistently and meaningfully. This work estimates the state of such structured representations in vision encoders. Specifically, we evaluate image encoders in large vision-language pre-trained models to address the question of which desirable properties their representations lack by applying the criteria of symbolic structured reasoning described for LLMs to the image models. We test the representation space of image encoders like VIT, BLIP, CLIP, and FLAVA to characterise the distribution of the object representations in these models. In particular, we create decoding tasks using multi-object scenes from the COCO dataset, relating the token space to its input content for various objects in the scene. We use these tasks to characterise the network's token and layer-wise information modelling. Our analysis highlights that the CLS token, used for the downstream task, only focuses on a few objects necessary for the trained downstream task. Still, other individual objects are well-modelled separately by the tokens in the network originating from those objects. We further observed a widespread distribution of scene information. This demonstrates that information is far more entangled in tokens than optimal for representing objects similar to symbols. Given these symbolic properties, we show the network dynamics that cause failure modes of these models on basic downstream tasks in a multi-object scene.
From DDMs to DNNs: Using process data and models of decision-making to improve human-AI interactions
Sep 07, 2023Over the past decades, cognitive neuroscientists and behavioral economists have recognized the value of describing the process of decision making in detail and modeling the emergence of decisions over time. For example, the time it takes to decide can reveal more about an agent's true hidden preferences than only the decision itself. Similarly, data that track the ongoing decision process such as eye movements or neural recordings contain critical information that can be exploited, even if no decision is made. Here, we argue that artificial intelligence (AI) research would benefit from a stronger focus on insights about how decisions emerge over time and incorporate related process data to improve AI predictions in general and human-AI interactions in particular. First, we introduce a highly established computational framework that assumes decisions to emerge from the noisy accumulation of evidence, and we present related empirical work in psychology, neuroscience, and economics. Next, we discuss to what extent current approaches in multi-agent AI do or do not incorporate process data and models of decision making. Finally, we outline how a more principled inclusion of the evidence-accumulation framework into the training and use of AI can help to improve human-AI interactions in the future.
The feasibility of artificial consciousness through the lens of neuroscience
Jun 19, 2023Interactions with large language models have led to the suggestion that these models may be conscious. From the perspective of neuroscience, this position is difficult to defend. For one, the architecture of large language models is missing key features of the thalamocortical system that have been linked to conscious awareness in mammals. Secondly, the inputs to large language models lack the embodied, embedded information content characteristic of our sensory contact with the world around us. Finally, while the previous two arguments can be overcome in future AI systems, the third one might be harder to bridge in the near future. Namely, we argue that consciousness might depend on having 'skin in the game', in that the existence of the system depends on its actions, which is not true for present-day artificial intelligence.
Mind the gap: Challenges of deep learning approaches to Theory of Mind
Mar 30, 2022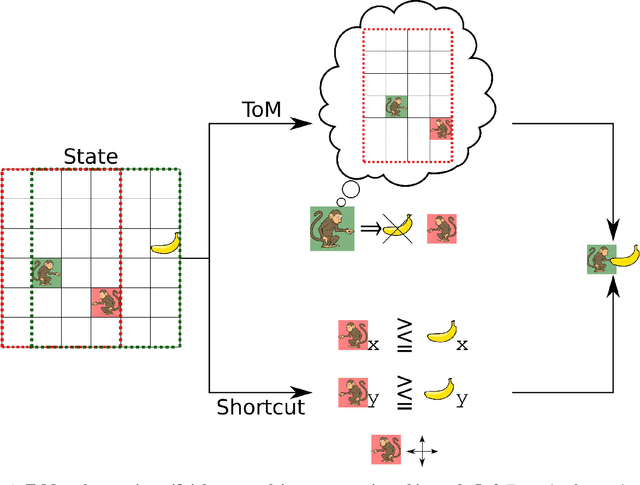
Theory of Mind is an essential ability of humans to infer the mental states of others. Here we provide a coherent summary of the potential, current progress, and problems of deep learning approaches to Theory of Mind. We highlight that many current findings can be explained through shortcuts. These shortcuts arise because the tasks used to investigate Theory of Mind in deep learning systems have been too narrow. Thus, we encourage researchers to investigate Theory of Mind in complex open-ended environments. Furthermore, to inspire future deep learning systems we provide a concise overview of prior work done in humans. We further argue that when studying Theory of Mind with deep learning, the research's main focus and contribution ought to be opening up the network's representations. We recommend researchers use tools from the field of interpretability of AI to study the relationship between different network components and aspects of Theory of Mind.
Perspective Taking in Deep Reinforcement Learning Agents
Jul 03, 2019

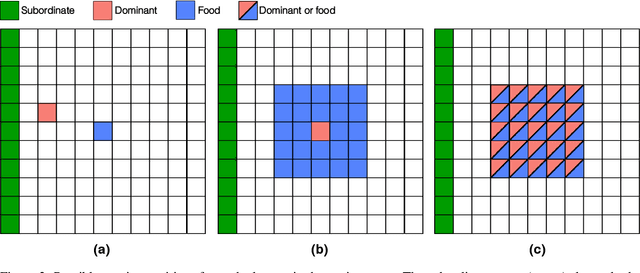

Perspective taking is the ability to take the point of view of another agent. This skill is not unique to humans as it is also displayed by other animals like chimpanzees. It is an essential ability for efficient social interactions, including cooperation, competition, and communication. In this work, we present our progress toward building artificial agents with such abilities. To this end we implemented a perspective taking task that was inspired by experiments done with chimpanzees. We show that agents controlled by artificial neural networks can learn via reinforcement learning to pass simple tests that require perspective taking capabilities. In particular, this ability is more readily learned when the agent has allocentric information about the objects in the environment. Building artificial agents with perspective taking ability will help to reverse engineer how computations underlying theory of mind might be accomplished in our brains.
APES: a Python toolbox for simulating reinforcement learning environments
Aug 31, 2018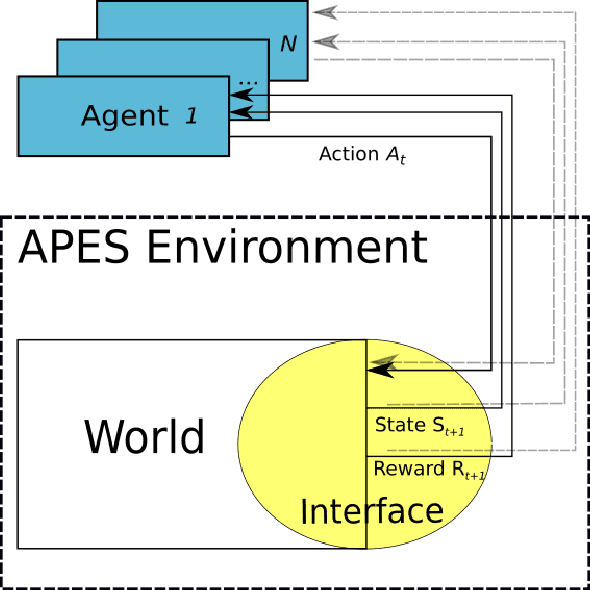



Assisted by neural networks, reinforcement learning agents have been able to solve increasingly complex tasks over the last years. The simulation environment in which the agents interact is an essential component in any reinforcement learning problem. The environment simulates the dynamics of the agents' world and hence provides feedback to their actions in terms of state observations and external rewards. To ease the design and simulation of such environments this work introduces $\texttt{APES}$, a highly customizable and open source package in Python to create 2D grid-world environments for reinforcement learning problems. $\texttt{APES}$ equips agents with algorithms to simulate any field of vision, it allows the creation and positioning of items and rewards according to user-defined rules, and supports the interaction of multiple agents.
Do deep reinforcement learning agents model intentions?
May 21, 2018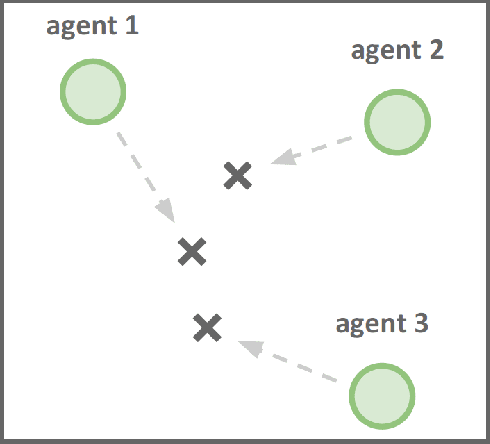
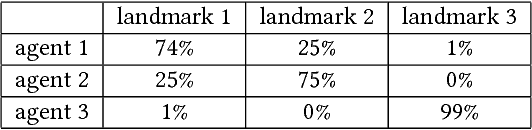
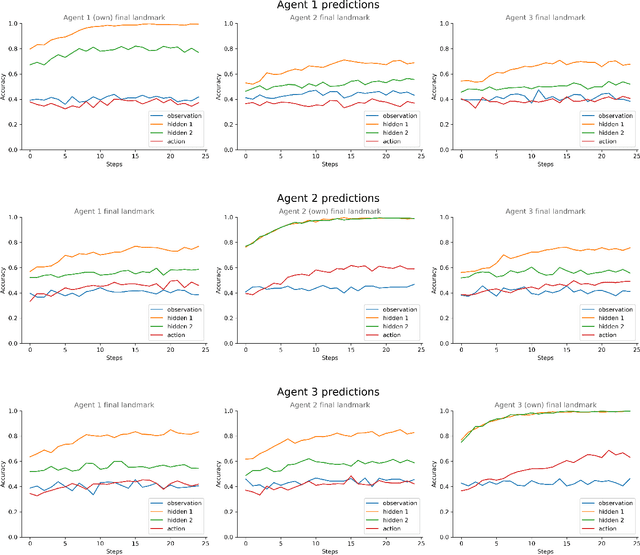
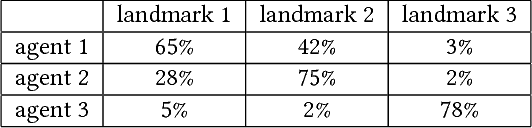
Inferring other agents' mental states such as their knowledge, beliefs and intentions is thought to be essential for effective interactions with other agents. Recently, multiagent systems trained via deep reinforcement learning have been shown to succeed in solving different tasks, but it remains unclear how each agent modeled or represented other agents in their environment. In this work we test whether deep reinforcement learning agents explicitly represent other agents' intentions (their specific aims or goals) during a task in which the agents had to coordinate the covering of different spots in a 2D environment. In particular, we tracked over time the performance of a linear decoder trained to predict the final goal of all agents from the hidden state of each agent's neural network controller. We observed that the hidden layers of agents represented explicit information about other agents' goals, i.e. the target landmark they ended up covering. We also performed a series of experiments, in which some agents were replaced by others with fixed goals, to test the level of generalization of the trained agents. We noticed that during the training phase the agents developed a differential preference for each goal, which hindered generalization. To alleviate the above problem, we propose simple changes to the MADDPG training algorithm which leads to better generalization against unseen agents. We believe that training protocols promoting more active intention reading mechanisms, e.g. by preventing simple symmetry-breaking solutions, is a promising direction towards achieving a more robust generalization in different cooperative and competitive tasks.
What deep learning can tell us about higher cognitive functions like mindreading?
Mar 28, 2018Can deep learning (DL) guide our understanding of computations happening in biological brain? We will first briefly consider how DL has contributed to the research on visual object recognition. In the main part we will assess whether DL could also help us to clarify the computations underlying higher cognitive functions such as Theory of Mind. In addition, we will compare the objectives and learning signals of brains and machines, leading us to conclude that simply scaling up the current DL algorithms will not lead to human level mindreading skills. We then provide some insights about how to fairly compare human and DL performance. In the end we find that DL can contribute to our understanding of biological computations by providing an example of an end-to-end algorithm that solves the same problems the biological agents face.
Multiagent Cooperation and Competition with Deep Reinforcement Learning
Nov 27, 2015
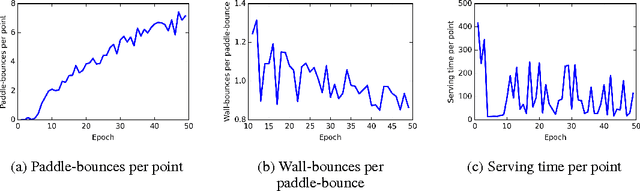


Multiagent systems appear in most social, economical, and political situations. In the present work we extend the Deep Q-Learning Network architecture proposed by Google DeepMind to multiagent environments and investigate how two agents controlled by independent Deep Q-Networks interact in the classic videogame Pong. By manipulating the classical rewarding scheme of Pong we demonstrate how competitive and collaborative behaviors emerge. Competitive agents learn to play and score efficiently. Agents trained under collaborative rewarding schemes find an optimal strategy to keep the ball in the game as long as possible. We also describe the progression from competitive to collaborative behavior. The present work demonstrates that Deep Q-Networks can become a practical tool for studying the decentralized learning of multiagent systems living in highly complex environments.