 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow structured are the representations in transformer-based vision encoders? An analysis of multi-object representations in vision-language models
Jun 18, 2024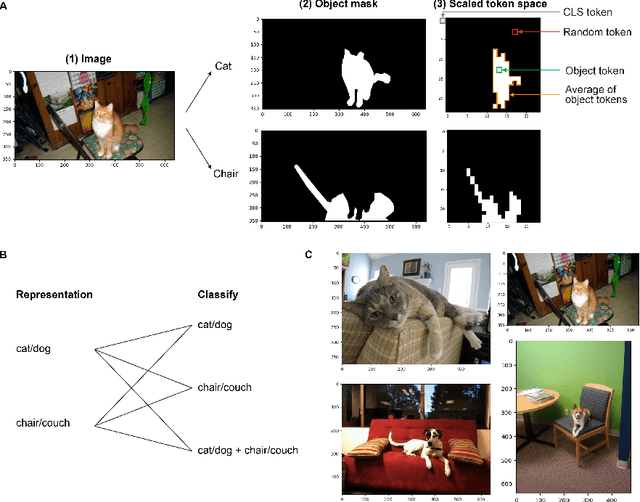
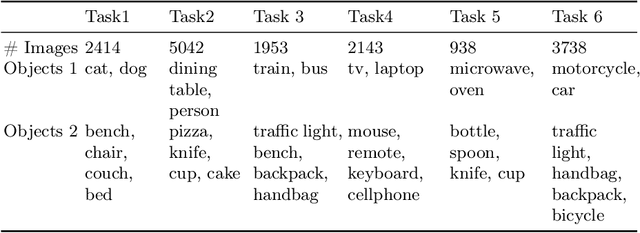
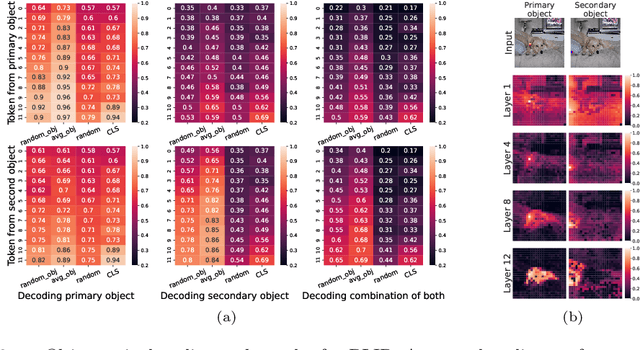
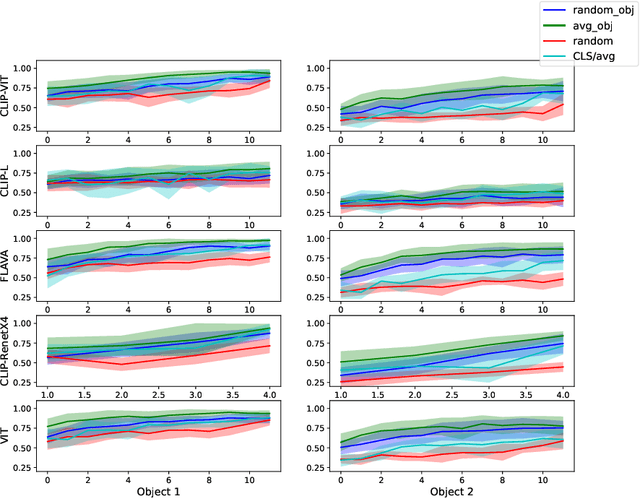
Forming and using symbol-like structured representations for reasoning has been considered essential for generalising over novel inputs. The primary tool that allows generalisation outside training data distribution is the ability to abstract away irrelevant information into a compact form relevant to the task. An extreme form of such abstract representations is symbols. Humans make use of symbols to bind information while abstracting away irrelevant parts to utilise the information consistently and meaningfully. This work estimates the state of such structured representations in vision encoders. Specifically, we evaluate image encoders in large vision-language pre-trained models to address the question of which desirable properties their representations lack by applying the criteria of symbolic structured reasoning described for LLMs to the image models. We test the representation space of image encoders like VIT, BLIP, CLIP, and FLAVA to characterise the distribution of the object representations in these models. In particular, we create decoding tasks using multi-object scenes from the COCO dataset, relating the token space to its input content for various objects in the scene. We use these tasks to characterise the network's token and layer-wise information modelling. Our analysis highlights that the CLS token, used for the downstream task, only focuses on a few objects necessary for the trained downstream task. Still, other individual objects are well-modelled separately by the tokens in the network originating from those objects. We further observed a widespread distribution of scene information. This demonstrates that information is far more entangled in tokens than optimal for representing objects similar to symbols. Given these symbolic properties, we show the network dynamics that cause failure modes of these models on basic downstream tasks in a multi-object scene.