 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo deep reinforcement learning agents model intentions?
Paper and Code
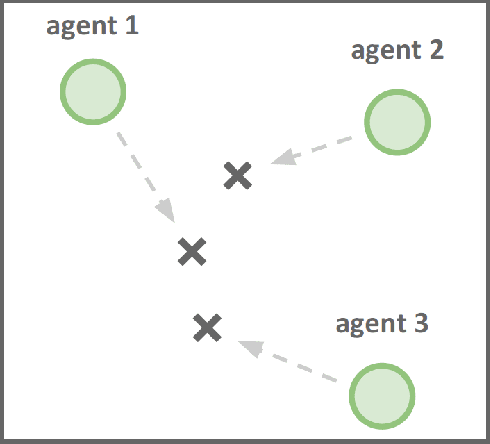
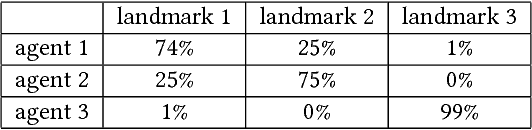
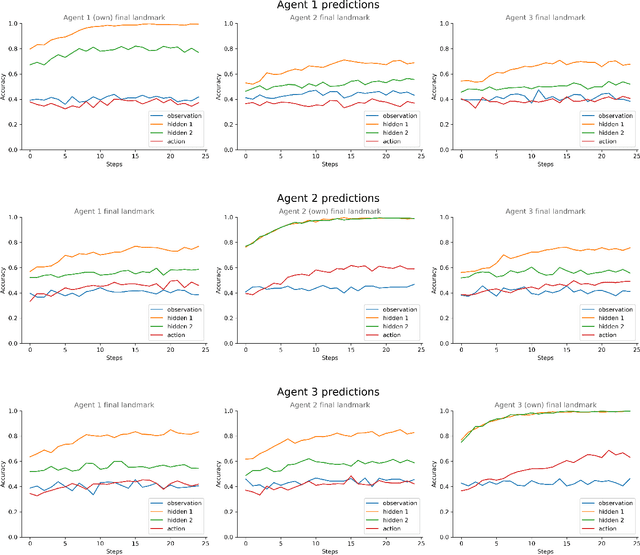
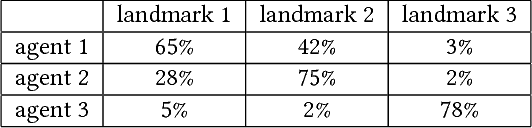
Inferring other agents' mental states such as their knowledge, beliefs and intentions is thought to be essential for effective interactions with other agents. Recently, multiagent systems trained via deep reinforcement learning have been shown to succeed in solving different tasks, but it remains unclear how each agent modeled or represented other agents in their environment. In this work we test whether deep reinforcement learning agents explicitly represent other agents' intentions (their specific aims or goals) during a task in which the agents had to coordinate the covering of different spots in a 2D environment. In particular, we tracked over time the performance of a linear decoder trained to predict the final goal of all agents from the hidden state of each agent's neural network controller. We observed that the hidden layers of agents represented explicit information about other agents' goals, i.e. the target landmark they ended up covering. We also performed a series of experiments, in which some agents were replaced by others with fixed goals, to test the level of generalization of the trained agents. We noticed that during the training phase the agents developed a differential preference for each goal, which hindered generalization. To alleviate the above problem, we propose simple changes to the MADDPG training algorithm which leads to better generalization against unseen agents. We believe that training protocols promoting more active intention reading mechanisms, e.g. by preventing simple symmetry-breaking solutions, is a promising direction towards achieving a more robust generalization in different cooperative and competitive tasks.