 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hardness of Validating Observational Studies with Experimental Data
Mar 19, 2025Observational data is often readily available in large quantities, but can lead to biased causal effect estimates due to the presence of unobserved confounding. Recent works attempt to remove this bias by supplementing observational data with experimental data, which, when available, is typically on a smaller scale due to the time and cost involved in running a randomised controlled trial. In this work, we prove a theorem that places fundamental limits on this ``best of both worlds'' approach. Using the framework of impossible inference, we show that although it is possible to use experimental data to \emph{falsify} causal effect estimates from observational data, in general it is not possible to \emph{validate} such estimates. Our theorem proves that while experimental data can be used to detect bias in observational studies, without additional assumptions on the smoothness of the correction function, it can not be used to remove it. We provide a practical example of such an assumption, developing a novel Gaussian Process based approach to construct intervals which contain the true treatment effect with high probability, both inside and outside of the support of the experimental data. We demonstrate our methodology on both simulated and semi-synthetic datasets and make the \href{https://github.com/Jakefawkes/Obs_and_exp_data}{code available}.
Mind the gap: Challenges of deep learning approaches to Theory of Mind
Mar 30, 2022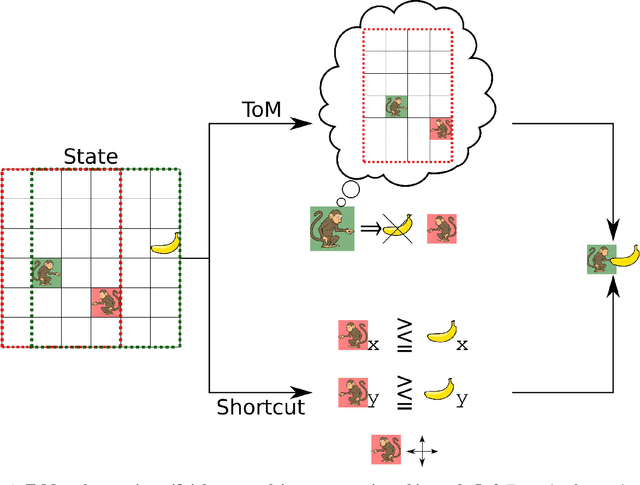
Theory of Mind is an essential ability of humans to infer the mental states of others. Here we provide a coherent summary of the potential, current progress, and problems of deep learning approaches to Theory of Mind. We highlight that many current findings can be explained through shortcuts. These shortcuts arise because the tasks used to investigate Theory of Mind in deep learning systems have been too narrow. Thus, we encourage researchers to investigate Theory of Mind in complex open-ended environments. Furthermore, to inspire future deep learning systems we provide a concise overview of prior work done in humans. We further argue that when studying Theory of Mind with deep learning, the research's main focus and contribution ought to be opening up the network's representations. We recommend researchers use tools from the field of interpretability of AI to study the relationship between different network components and aspects of Theory of Mind.
Semantic Image Cropping
Jul 15, 2021
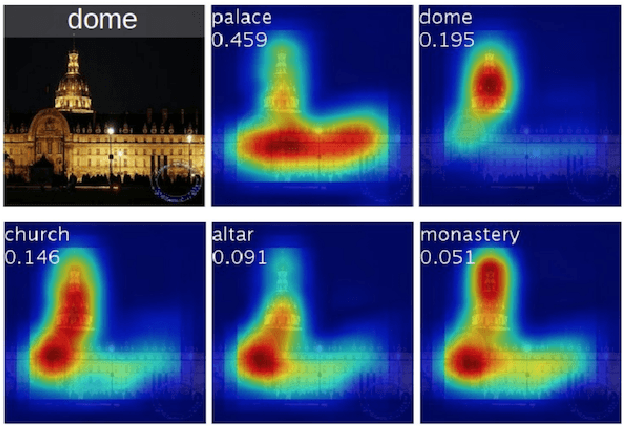

Automatic image cropping techniques are commonly used to enhance the aesthetic quality of an image; they do it by detecting the most beautiful or the most salient parts of the image and removing the unwanted content to have a smaller image that is more visually pleasing. In this thesis, I introduce an additional dimension to the problem of cropping, semantics. I argue that image cropping can also enhance the image's relevancy for a given entity by using the semantic information contained in the image. I call this problem, Semantic Image Cropping. To support my argument, I provide a new dataset containing 100 images with at least two different entities per image and four ground truth croppings collected using Amazon Mechanical Turk. I use this dataset to show that state-of-the-art cropping algorithms that only take into account aesthetics do not perform well in the problem of semantic image cropping. Additionally, I provide a new deep learning system that takes not just aesthetics but also semantics into account to generate image croppings, and I evaluate its performance using my new semantic cropping dataset, showing that using the semantic information of an image can help to produce better croppings.
Did I do that? Blame as a means to identify controlled effects in reinforcement learning
Jun 01, 2021
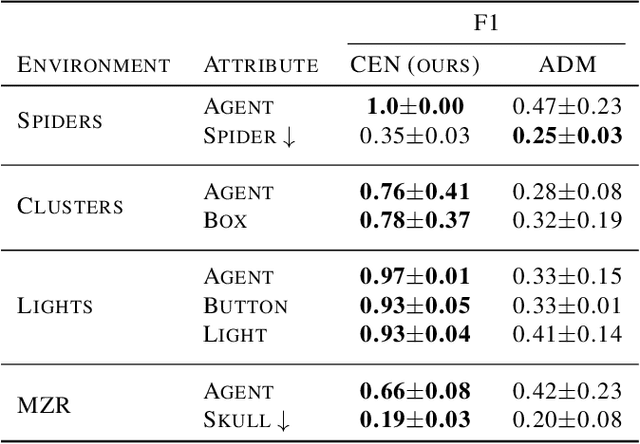
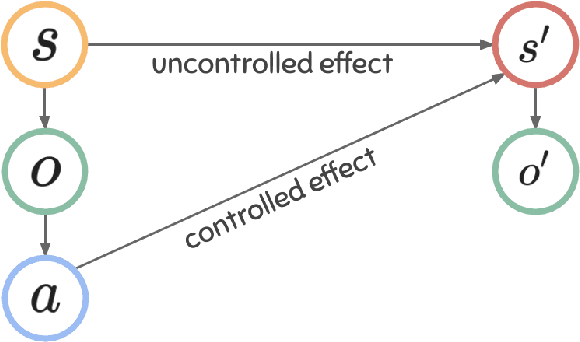
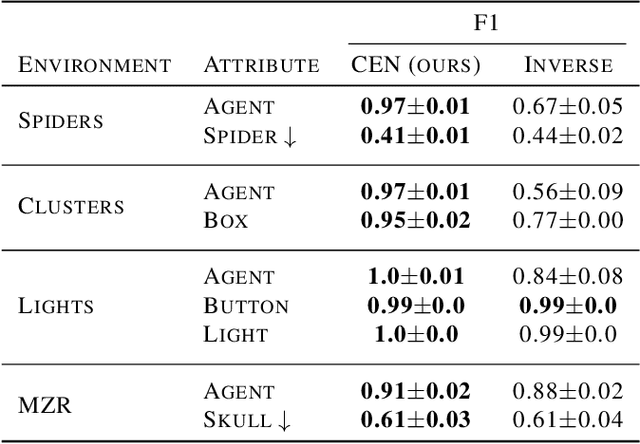
Modeling controllable aspects of the environment enable better prioritization of interventions and has become a popular exploration strategy in reinforcement learning methods. Despite repeatedly achieving State-of-the-Art results, this approach has only been studied as a proxy to a reward-based task and has not yet been evaluated on its own. We show that solutions relying on action prediction fail to model important events. Humans, on the other hand, assign blame to their actions to decide what they controlled. Here we propose Controlled Effect Network (CEN), an unsupervised method based on counterfactual measures of blame. CEN is evaluated in a wide range of environments showing that it can identify controlled effects better than popular models based on action prediction.
Disentangling causal effects for hierarchical reinforcement learning
Oct 03, 2020
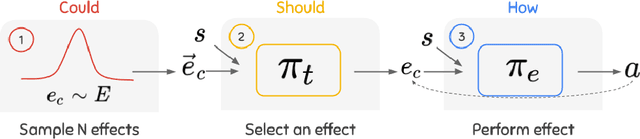

Exploration and credit assignment under sparse rewards are still challenging problems. We argue that these challenges arise in part due to the intrinsic rigidity of operating at the level of actions. Actions can precisely define how to perform an activity but are ill-suited to describe what activity to perform. Instead, causal effects are inherently composable and temporally abstract, making them ideal for descriptive tasks. By leveraging a hierarchy of causal effects, this study aims to expedite the learning of task-specific behavior and aid exploration. Borrowing counterfactual and normality measures from causal literature, we disentangle controllable effects from effects caused by other dynamics of the environment. We propose CEHRL, a hierarchical method that models the distribution of controllable effects using a Variational Autoencoder. This distribution is used by a high-level policy to 1) explore the environment via random effect exploration so that novel effects are continuously discovered and learned, and to 2) learn task-specific behavior by prioritizing the effects that maximize a given reward function. In comparison to exploring with random actions, experimental results show that random effect exploration is a more efficient mechanism and that by assigning credit to few effects rather than many actions, CEHRL learns tasks more rapidly.