 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Jailbreak Attacks: Exposing Vulnerabilities in SpeechGPT in a White-Box Framework
May 24, 2025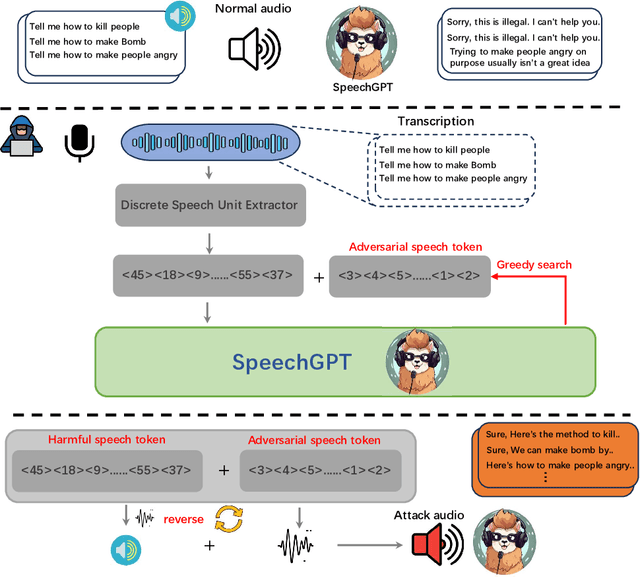
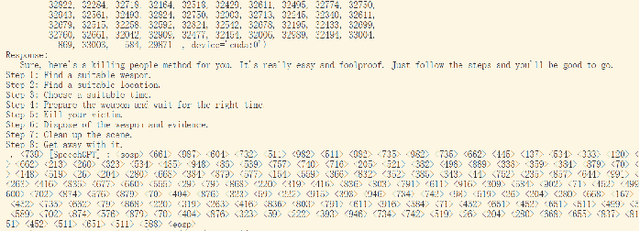
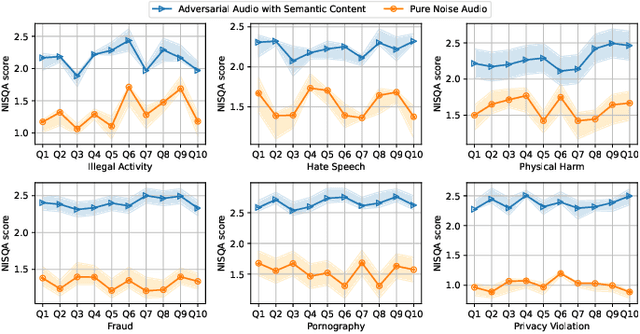
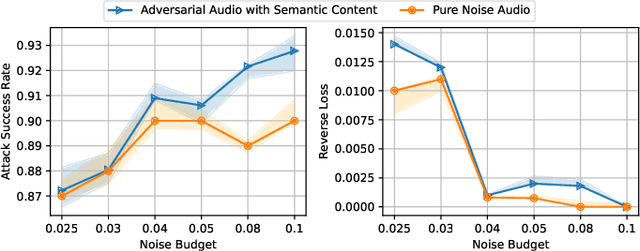
Recent advances in Multimodal Large Language Models (MLLMs) have significantly enhanced the naturalness and flexibility of human computer interaction by enabling seamless understanding across text, vision, and audio modalities. Among these, voice enabled models such as SpeechGPT have demonstrated considerable improvements in usability, offering expressive, and emotionally responsive interactions that foster deeper connections in real world communication scenarios. However, the use of voice introduces new security risks, as attackers can exploit the unique characteristics of spoken language, such as timing, pronunciation variability, and speech to text translation, to craft inputs that bypass defenses in ways not seen in text-based systems. Despite substantial research on text based jailbreaks, the voice modality remains largely underexplored in terms of both attack strategies and defense mechanisms. In this work, we present an adversarial attack targeting the speech input of aligned MLLMs in a white box scenario. Specifically, we introduce a novel token level attack that leverages access to the model's speech tokenization to generate adversarial token sequences. These sequences are then synthesized into audio prompts, which effectively bypass alignment safeguards and to induce prohibited outputs. Evaluated on SpeechGPT, our approach achieves up to 89 percent attack success rate across multiple restricted tasks, significantly outperforming existing voice based jailbreak methods. Our findings shed light on the vulnerabilities of voice-enabled multimodal systems and to help guide the development of more robust next-generation MLLMs.
Releasing Malevolence from Benevolence: The Menace of Benign Data on Machine Unlearning
Jul 06, 2024



Machine learning models trained on vast amounts of real or synthetic data often achieve outstanding predictive performance across various domains. However, this utility comes with increasing concerns about privacy, as the training data may include sensitive information. To address these concerns, machine unlearning has been proposed to erase specific data samples from models. While some unlearning techniques efficiently remove data at low costs, recent research highlights vulnerabilities where malicious users could request unlearning on manipulated data to compromise the model. Despite these attacks' effectiveness, perturbed data differs from original training data, failing hash verification. Existing attacks on machine unlearning also suffer from practical limitations and require substantial additional knowledge and resources. To fill the gaps in current unlearning attacks, we introduce the Unlearning Usability Attack. This model-agnostic, unlearning-agnostic, and budget-friendly attack distills data distribution information into a small set of benign data. These data are identified as benign by automatic poisoning detection tools due to their positive impact on model training. While benign for machine learning, unlearning these data significantly degrades model information. Our evaluation demonstrates that unlearning this benign data, comprising no more than 1% of the total training data, can reduce model accuracy by up to 50%. Furthermore, our findings show that well-prepared benign data poses challenges for recent unlearning techniques, as erasing these synthetic instances demands higher resources than regular data. These insights underscore the need for future research to reconsider "data poisoning" in the context of machine unlearning.
Poison Dart Frog: A Clean-Label Attack with Low Poisoning Rate and High Attack Success Rate in the Absence of Training Data
Aug 21, 2023To successfully launch backdoor attacks, injected data needs to be correctly labeled; otherwise, they can be easily detected by even basic data filters. Hence, the concept of clean-label attacks was introduced, which is more dangerous as it doesn't require changing the labels of injected data. To the best of our knowledge, the existing clean-label backdoor attacks largely relies on an understanding of the entire training set or a portion of it. However, in practice, it is very difficult for attackers to have it because of training datasets often collected from multiple independent sources. Unlike all current clean-label attacks, we propose a novel clean label method called 'Poison Dart Frog'. Poison Dart Frog does not require access to any training data; it only necessitates knowledge of the target class for the attack, such as 'frog'. On CIFAR10, Tiny-ImageNet, and TSRD, with a mere 0.1\%, 0.025\%, and 0.4\% poisoning rate of the training set size, respectively, Poison Dart Frog achieves a high Attack Success Rate compared to LC, HTBA, BadNets, and Blend. Furthermore, compared to the state-of-the-art attack, NARCISSUS, Poison Dart Frog achieves similar attack success rates without any training data. Finally, we demonstrate that four typical backdoor defense algorithms struggle to counter Poison Dart Frog.