 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Power Grid Multi-Stage Cascading Failure Mitigation
May 13, 2025Cascading failures in power grids can lead to grid collapse, causing severe disruptions to social operations and economic activities. In certain cases, multi-stage cascading failures can occur. However, existing cascading-failure-mitigation strategies are usually single-stage-based, overlooking the complexity of the multi-stage scenario. This paper treats the multi-stage cascading failure problem as a reinforcement learning task and develops a simulation environment. The reinforcement learning agent is then trained via the deterministic policy gradient algorithm to achieve continuous actions. Finally, the effectiveness of the proposed approach is validated on the IEEE 14-bus and IEEE 118-bus systems.
QD-VMR: Query Debiasing with Contextual Understanding Enhancement for Video Moment Retrieval
Aug 23, 2024Video Moment Retrieval (VMR) aims to retrieve relevant moments of an untrimmed video corresponding to the query. While cross-modal interaction approaches have shown progress in filtering out query-irrelevant information in videos, they assume the precise alignment between the query semantics and the corresponding video moments, potentially overlooking the misunderstanding of the natural language semantics. To address this challenge, we propose a novel model called \textit{QD-VMR}, a query debiasing model with enhanced contextual understanding. Firstly, we leverage a Global Partial Aligner module via video clip and query features alignment and video-query contrastive learning to enhance the cross-modal understanding capabilities of the model. Subsequently, we employ a Query Debiasing Module to obtain debiased query features efficiently, and a Visual Enhancement module to refine the video features related to the query. Finally, we adopt the DETR structure to predict the possible target video moments. Through extensive evaluations of three benchmark datasets, QD-VMR achieves state-of-the-art performance, proving its potential to improve the accuracy of VMR. Further analytical experiments demonstrate the effectiveness of our proposed module. Our code will be released to facilitate future research.
Poison Dart Frog: A Clean-Label Attack with Low Poisoning Rate and High Attack Success Rate in the Absence of Training Data
Aug 21, 2023To successfully launch backdoor attacks, injected data needs to be correctly labeled; otherwise, they can be easily detected by even basic data filters. Hence, the concept of clean-label attacks was introduced, which is more dangerous as it doesn't require changing the labels of injected data. To the best of our knowledge, the existing clean-label backdoor attacks largely relies on an understanding of the entire training set or a portion of it. However, in practice, it is very difficult for attackers to have it because of training datasets often collected from multiple independent sources. Unlike all current clean-label attacks, we propose a novel clean label method called 'Poison Dart Frog'. Poison Dart Frog does not require access to any training data; it only necessitates knowledge of the target class for the attack, such as 'frog'. On CIFAR10, Tiny-ImageNet, and TSRD, with a mere 0.1\%, 0.025\%, and 0.4\% poisoning rate of the training set size, respectively, Poison Dart Frog achieves a high Attack Success Rate compared to LC, HTBA, BadNets, and Blend. Furthermore, compared to the state-of-the-art attack, NARCISSUS, Poison Dart Frog achieves similar attack success rates without any training data. Finally, we demonstrate that four typical backdoor defense algorithms struggle to counter Poison Dart Frog.
GCsT: Graph Convolutional Skeleton Transformer for Action Recognition
Sep 10, 2021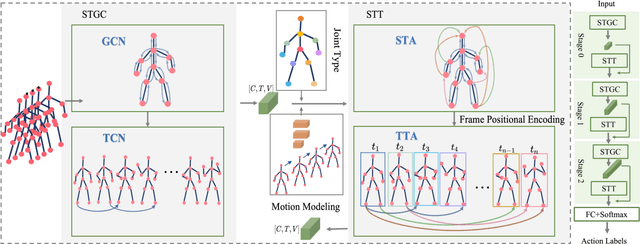
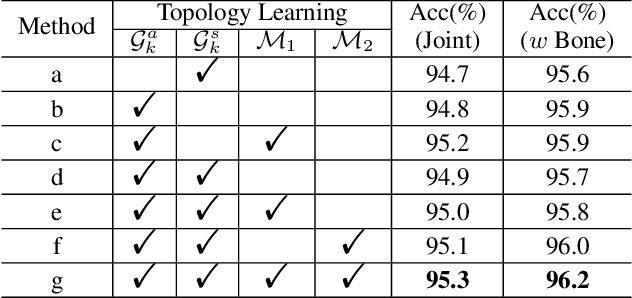
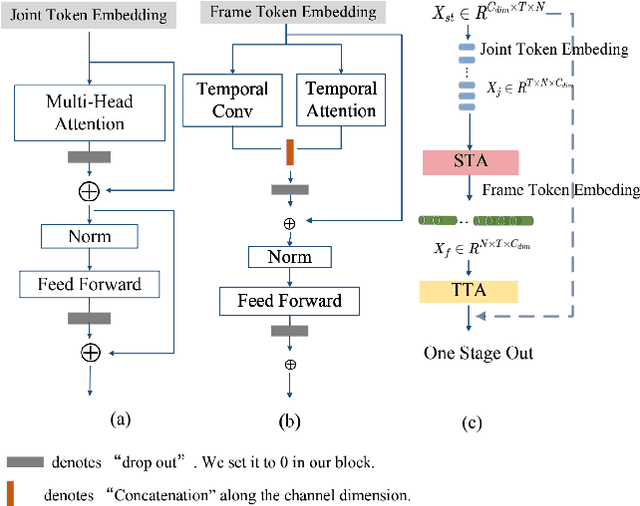
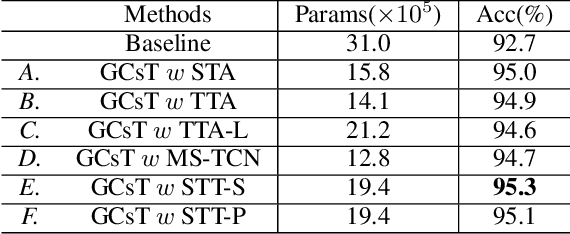
Graph convolutional networks (GCNs) achieve promising performance for skeleton-based action recognition. However, in most GCN-based methods, the spatial-temporal graph convolution is strictly restricted by the graph topology while only captures the short-term temporal context, thus lacking the flexibility of feature extraction. In this work, we present a novel architecture, named Graph Convolutional skeleton Transformer (GCsT), which addresses limitations in GCNs by introducing Transformer. Our GCsT employs all the benefits of Transformer (i.e. dynamical attention and global context) while keeps the advantages of GCNs (i.e. hierarchy and local topology structure). In GCsT, the spatial-temporal GCN forces the capture of local dependencies while Transformer dynamically extracts global spatial-temporal relationships. Furthermore, the proposed GCsT shows stronger expressive capability by adding additional information present in skeleton sequences. Incorporating the Transformer allows that information to be introduced into the model almost effortlessly. We validate the proposed GCsT by conducting extensive experiments, which achieves the state-of-the-art performance on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA datasets.
Rethinking the Aligned and Misaligned Features in One-stage Object Detection
Sep 08, 2021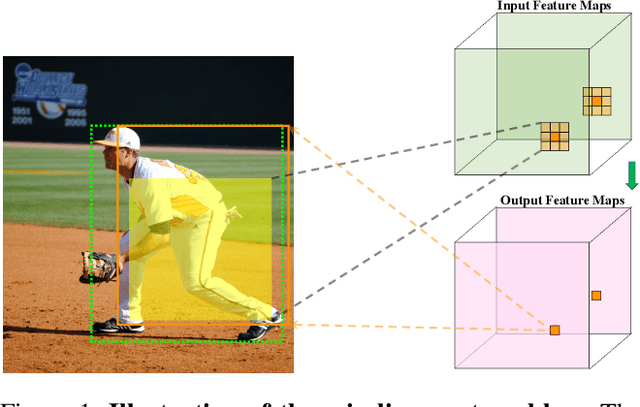
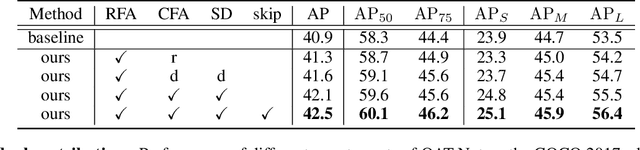
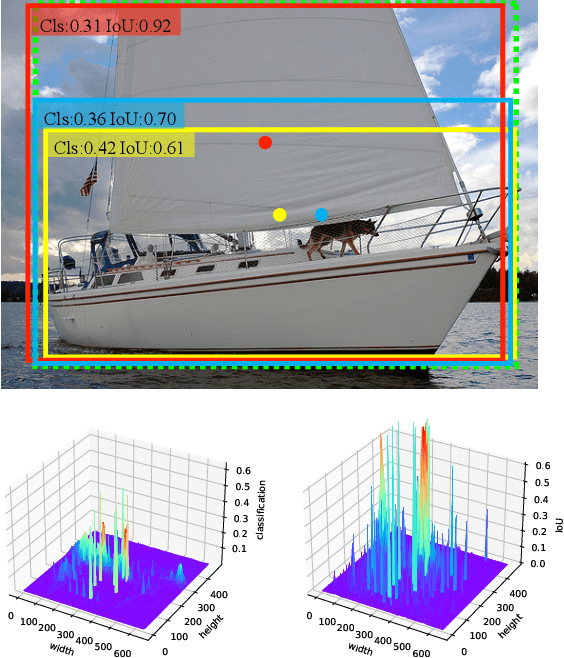
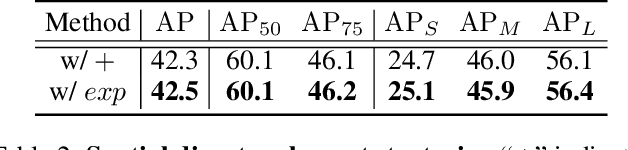
One-stage object detectors rely on a point feature to predict the detection results. However, the point feature often lacks the information of the whole object, thereby leading to a misalignment between the object and the point feature. Meanwhile, the classification and regression tasks are sensitive to different object regions, but their features are spatially aligned. Both of these two problems hinder the detection performance. In order to solve these two problems, we propose a simple and plug-in operator that can generate aligned and disentangled features for each task, respectively, without breaking the fully convolutional manner. By predicting two task-aware point sets that are located in each sensitive region, the proposed operator can align the point feature with the object and disentangle the two tasks from the spatial dimension. We also reveal an interesting finding of the opposite effect of the long-range skip connection for classification and regression. On the basis of the Object-Aligned and Task-disentangled operator (OAT), we propose OAT-Net, which explicitly exploits point-set features for accurate detection results. Extensive experiments on the MS-COCO dataset show that OAT can consistently boost different state-of-the-art one-stage detectors by $\sim$2 AP. Notably, OAT-Net with Res2Net-101-DCN backbone achieves 53.7 AP on the COCO test-dev.
Objects as Extreme Points
May 22, 2021
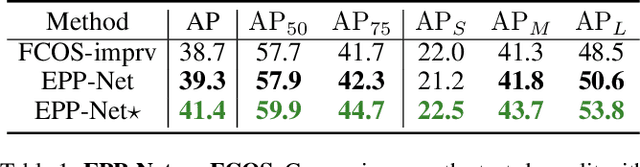
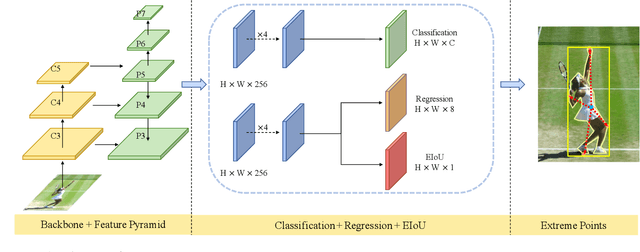
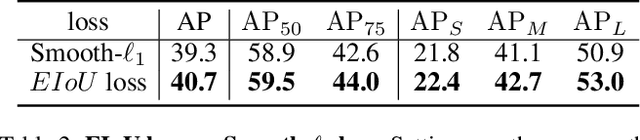
Object detection can be regarded as a pixel clustering task, and its boundary is determined by four extreme points (leftmost, top, rightmost, and bottom). However, most studies focus on the center or corner points of the object, which are actually conditional results of the extreme points. In this paper, we present an Extreme-Point-Prediction- Based object detector (EPP-Net), which directly regresses the relative displacement vector between each pixel and the four extreme points. We also propose a new metric to measure the similarity between two groups of extreme points, namely, Extreme Intersection over Union (EIoU), and incorporate this EIoU as a new regression loss. Moreover, we propose a novel branch to predict the EIoU between the ground-truth and the prediction results, and take it as the localization confidence to filter out poor detection results. On the MS-COCO dataset, our method achieves an average precision (AP) of 44.0% with ResNet-50 and an AP of 50.3% with ResNeXt-101-DCN. The proposed EPP-Net provides a new method to detect objects and outperforms state-of-the-art anchor-free detectors.