 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKairos: Practical Intrusion Detection and Investigation using Whole-system Provenance
Aug 13, 2023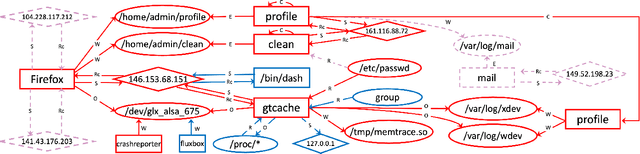

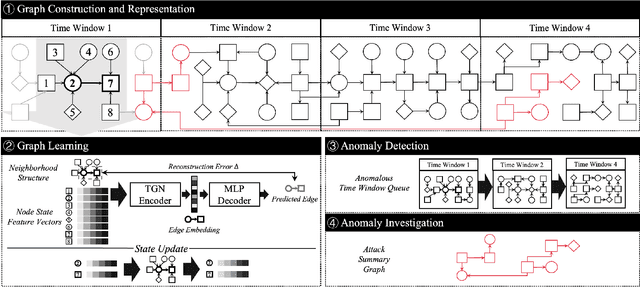
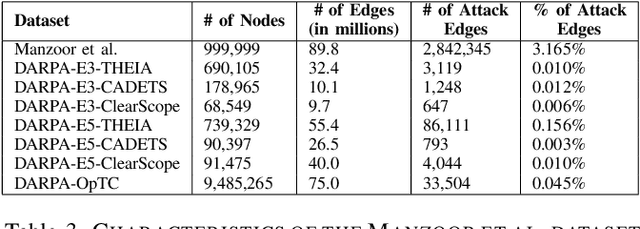
Provenance graphs are structured audit logs that describe the history of a system's execution. Recent studies have explored a variety of techniques to analyze provenance graphs for automated host intrusion detection, focusing particularly on advanced persistent threats. Sifting through their design documents, we identify four common dimensions that drive the development of provenance-based intrusion detection systems (PIDSes): scope (can PIDSes detect modern attacks that infiltrate across application boundaries?), attack agnosticity (can PIDSes detect novel attacks without a priori knowledge of attack characteristics?), timeliness (can PIDSes efficiently monitor host systems as they run?), and attack reconstruction (can PIDSes distill attack activity from large provenance graphs so that sysadmins can easily understand and quickly respond to system intrusion?). We present KAIROS, the first PIDS that simultaneously satisfies the desiderata in all four dimensions, whereas existing approaches sacrifice at least one and struggle to achieve comparable detection performance. Kairos leverages a novel graph neural network-based encoder-decoder architecture that learns the temporal evolution of a provenance graph's structural changes to quantify the degree of anomalousness for each system event. Then, based on this fine-grained information, Kairos reconstructs attack footprints, generating compact summary graphs that accurately describe malicious activity over a stream of system audit logs. Using state-of-the-art benchmark datasets, we demonstrate that Kairos outperforms previous approaches.
GCsT: Graph Convolutional Skeleton Transformer for Action Recognition
Sep 10, 2021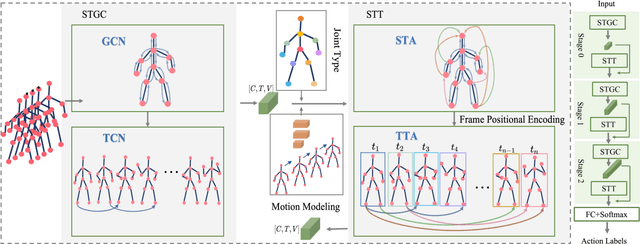
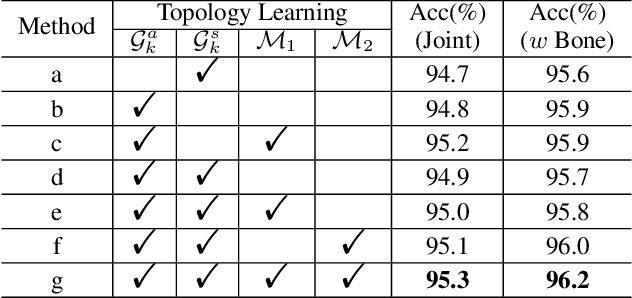
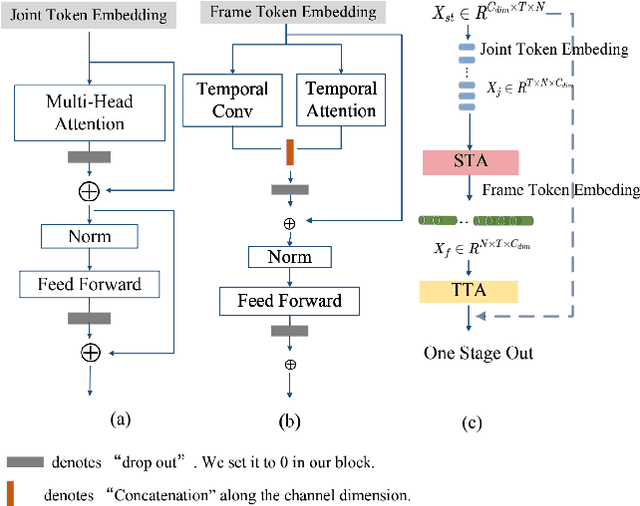
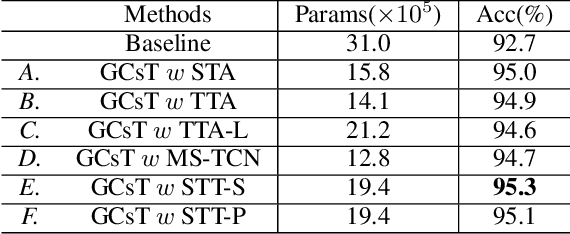
Graph convolutional networks (GCNs) achieve promising performance for skeleton-based action recognition. However, in most GCN-based methods, the spatial-temporal graph convolution is strictly restricted by the graph topology while only captures the short-term temporal context, thus lacking the flexibility of feature extraction. In this work, we present a novel architecture, named Graph Convolutional skeleton Transformer (GCsT), which addresses limitations in GCNs by introducing Transformer. Our GCsT employs all the benefits of Transformer (i.e. dynamical attention and global context) while keeps the advantages of GCNs (i.e. hierarchy and local topology structure). In GCsT, the spatial-temporal GCN forces the capture of local dependencies while Transformer dynamically extracts global spatial-temporal relationships. Furthermore, the proposed GCsT shows stronger expressive capability by adding additional information present in skeleton sequences. Incorporating the Transformer allows that information to be introduced into the model almost effortlessly. We validate the proposed GCsT by conducting extensive experiments, which achieves the state-of-the-art performance on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA datasets.
Rethinking the Aligned and Misaligned Features in One-stage Object Detection
Sep 08, 2021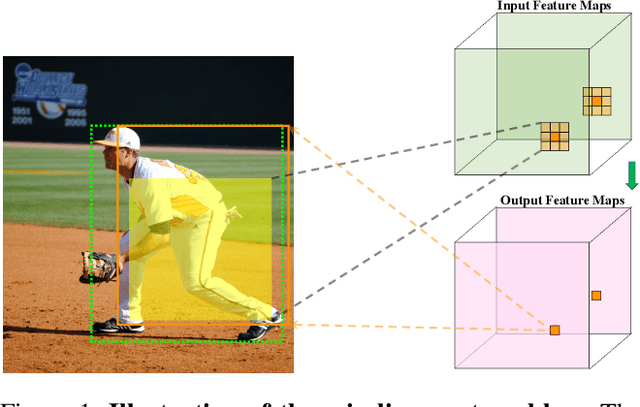
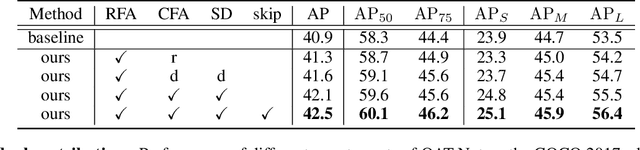
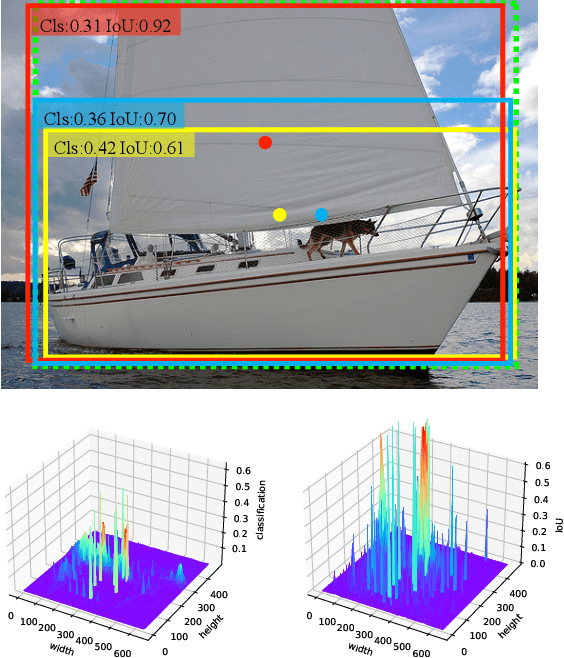
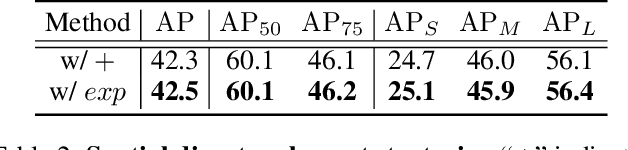
One-stage object detectors rely on a point feature to predict the detection results. However, the point feature often lacks the information of the whole object, thereby leading to a misalignment between the object and the point feature. Meanwhile, the classification and regression tasks are sensitive to different object regions, but their features are spatially aligned. Both of these two problems hinder the detection performance. In order to solve these two problems, we propose a simple and plug-in operator that can generate aligned and disentangled features for each task, respectively, without breaking the fully convolutional manner. By predicting two task-aware point sets that are located in each sensitive region, the proposed operator can align the point feature with the object and disentangle the two tasks from the spatial dimension. We also reveal an interesting finding of the opposite effect of the long-range skip connection for classification and regression. On the basis of the Object-Aligned and Task-disentangled operator (OAT), we propose OAT-Net, which explicitly exploits point-set features for accurate detection results. Extensive experiments on the MS-COCO dataset show that OAT can consistently boost different state-of-the-art one-stage detectors by $\sim$2 AP. Notably, OAT-Net with Res2Net-101-DCN backbone achieves 53.7 AP on the COCO test-dev.
Objects as Extreme Points
May 22, 2021
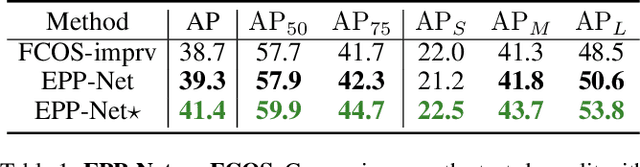
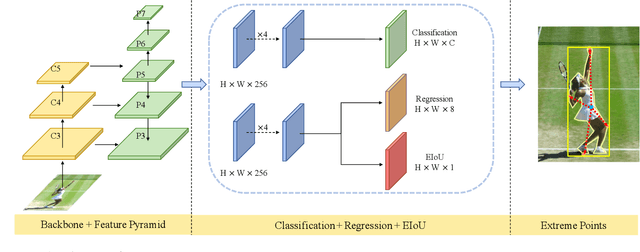
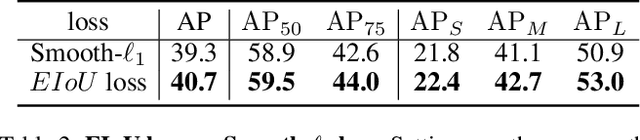
Object detection can be regarded as a pixel clustering task, and its boundary is determined by four extreme points (leftmost, top, rightmost, and bottom). However, most studies focus on the center or corner points of the object, which are actually conditional results of the extreme points. In this paper, we present an Extreme-Point-Prediction- Based object detector (EPP-Net), which directly regresses the relative displacement vector between each pixel and the four extreme points. We also propose a new metric to measure the similarity between two groups of extreme points, namely, Extreme Intersection over Union (EIoU), and incorporate this EIoU as a new regression loss. Moreover, we propose a novel branch to predict the EIoU between the ground-truth and the prediction results, and take it as the localization confidence to filter out poor detection results. On the MS-COCO dataset, our method achieves an average precision (AP) of 44.0% with ResNet-50 and an AP of 50.3% with ResNeXt-101-DCN. The proposed EPP-Net provides a new method to detect objects and outperforms state-of-the-art anchor-free detectors.