 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovieTeller: Tool-augmented Movie Synopsis with ID Consistent Progressive Abstraction
Feb 26, 2026With the explosive growth of digital entertainment, automated video summarization has become indispensable for applications such as content indexing, personalized recommendation, and efficient media archiving. Automatic synopsis generation for long-form videos, such as movies and TV series, presents a significant challenge for existing Vision-Language Models (VLMs). While proficient at single-image captioning, these general-purpose models often exhibit critical failures in long-duration contexts, primarily a lack of ID-consistent character identification and a fractured narrative coherence. To overcome these limitations, we propose MovieTeller, a novel framework for generating movie synopses via tool-augmented progressive abstraction. Our core contribution is a training-free, tool-augmented, fact-grounded generation process. Instead of requiring costly model fine-tuning, our framework directly leverages off-the-shelf models in a plug-and-play manner. We first invoke a specialized face recognition model as an external "tool" to establish Factual Groundings--precise character identities and their corresponding bounding boxes. These groundings are then injected into the prompt to steer the VLM's reasoning, ensuring the generated scene descriptions are anchored to verifiable facts. Furthermore, our progressive abstraction pipeline decomposes the summarization of a full-length movie into a multi-stage process, effectively mitigating the context length limitations of current VLMs. Experiments demonstrate that our approach yields significant improvements in factual accuracy, character consistency, and overall narrative coherence compared to end-to-end baselines.
GridCodex: A RAG-Driven AI Framework for Power Grid Code Reasoning and Compliance
Aug 18, 2025



The global shift towards renewable energy presents unprecedented challenges for the electricity industry, making regulatory reasoning and compliance increasingly vital. Grid codes, the regulations governing grid operations, are complex and often lack automated interpretation solutions, which hinders industry expansion and undermines profitability for electricity companies. We introduce GridCodex, an end to end framework for grid code reasoning and compliance that leverages large language models and retrieval-augmented generation (RAG). Our framework advances conventional RAG workflows through multi stage query refinement and enhanced retrieval with RAPTOR. We validate the effectiveness of GridCodex with comprehensive benchmarks, including automated answer assessment across multiple dimensions and regulatory agencies. Experimental results showcase a 26.4% improvement in answer quality and more than a 10 fold increase in recall rate. An ablation study further examines the impact of base model selection.
GCsT: Graph Convolutional Skeleton Transformer for Action Recognition
Sep 10, 2021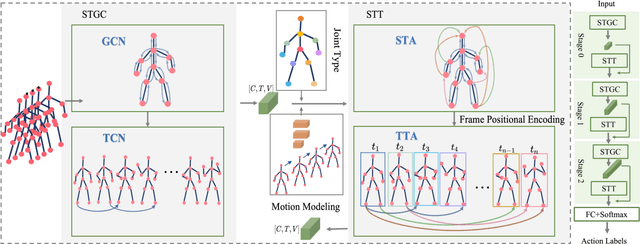
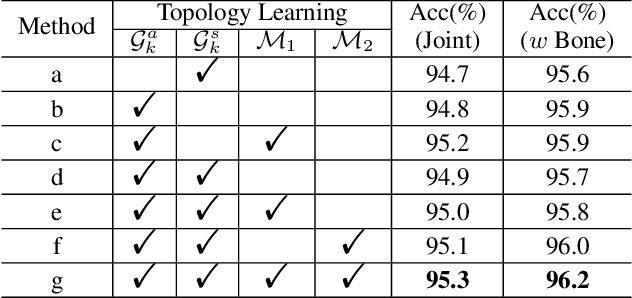
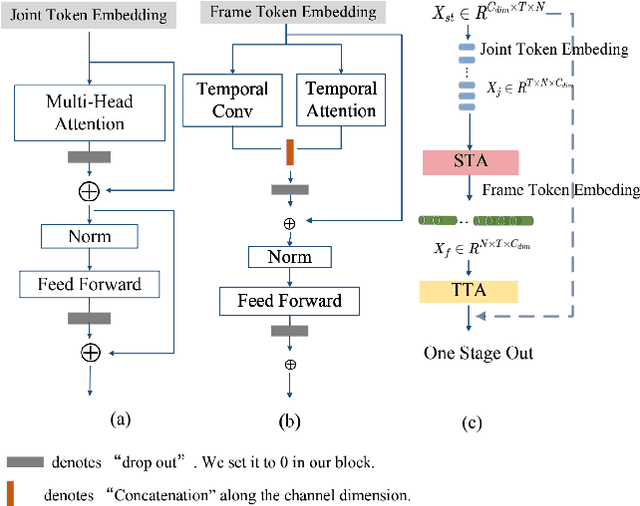
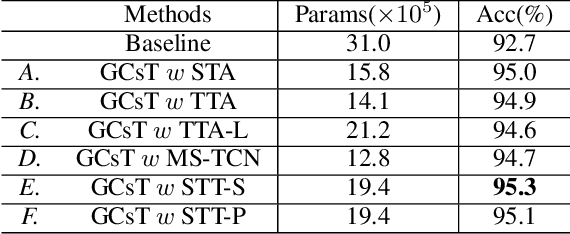
Graph convolutional networks (GCNs) achieve promising performance for skeleton-based action recognition. However, in most GCN-based methods, the spatial-temporal graph convolution is strictly restricted by the graph topology while only captures the short-term temporal context, thus lacking the flexibility of feature extraction. In this work, we present a novel architecture, named Graph Convolutional skeleton Transformer (GCsT), which addresses limitations in GCNs by introducing Transformer. Our GCsT employs all the benefits of Transformer (i.e. dynamical attention and global context) while keeps the advantages of GCNs (i.e. hierarchy and local topology structure). In GCsT, the spatial-temporal GCN forces the capture of local dependencies while Transformer dynamically extracts global spatial-temporal relationships. Furthermore, the proposed GCsT shows stronger expressive capability by adding additional information present in skeleton sequences. Incorporating the Transformer allows that information to be introduced into the model almost effortlessly. We validate the proposed GCsT by conducting extensive experiments, which achieves the state-of-the-art performance on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA datasets.
Joint Device Scheduling and Resource Allocation for Latency Constrained Wireless Federated Learning
Jul 14, 2020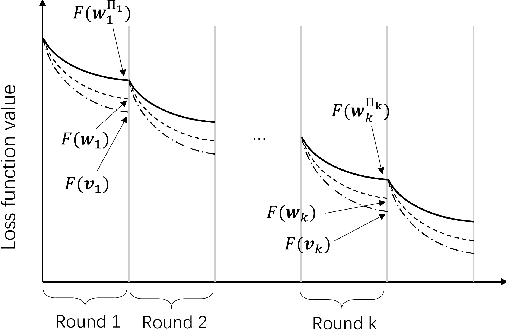
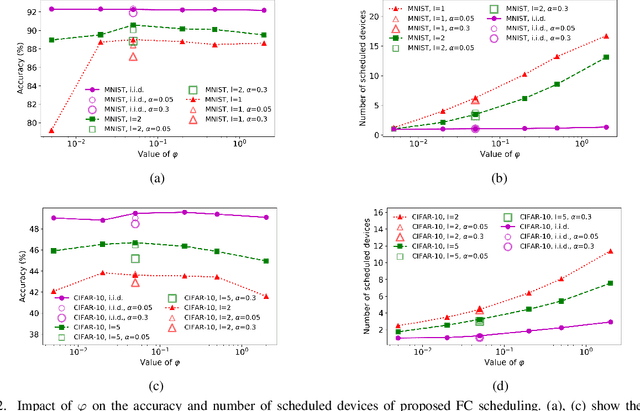
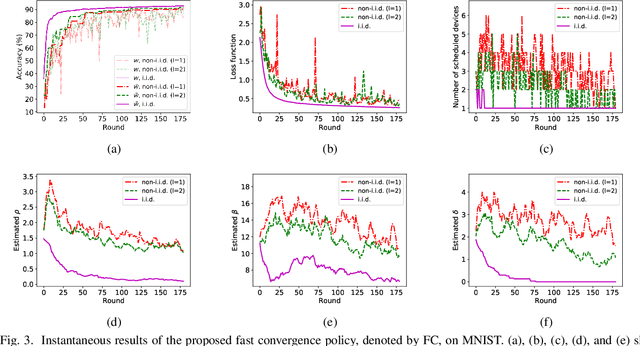
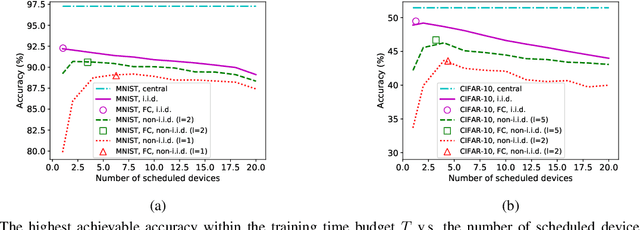
In federated learning (FL), devices contribute to the global training by uploading their local model updates via wireless channels. Due to limited computation and communication resources, device scheduling is crucial to the convergence rate of FL. In this paper, we propose a joint device scheduling and resource allocation policy to maximize the model accuracy within a given total training time budget for latency constrained wireless FL. A lower bound on the reciprocal of the training performance loss, in terms of the number of training rounds and the number of scheduled devices per round, is derived. Based on the bound, the accuracy maximization problem is solved by decoupling it into two sub-problems. First, given the scheduled devices, the optimal bandwidth allocation suggests allocating more bandwidth to the devices with worse channel conditions or weaker computation capabilities. Then, a greedy device scheduling algorithm is introduced, which in each step selects the device consuming the least updating time obtained by the optimal bandwidth allocation, until the lower bound begins to increase, meaning that scheduling more devices will degrade the model accuracy. Experiments show that the proposed policy outperforms state-of-the-art scheduling policies under extensive settings of data distributions and cell radius.
Achieving Fairness in Determining Medicaid Eligibility through Fairgroup Construction
Jun 01, 2019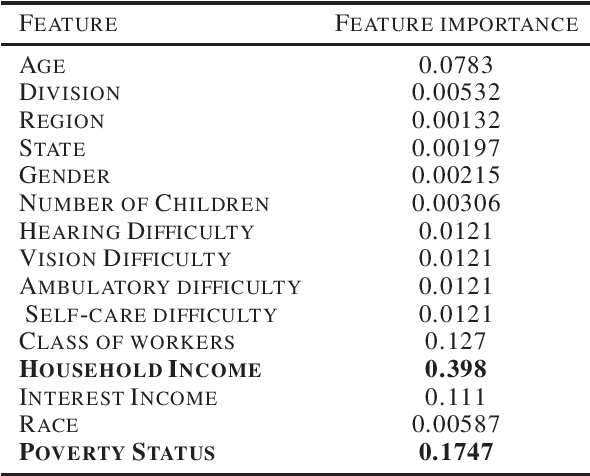
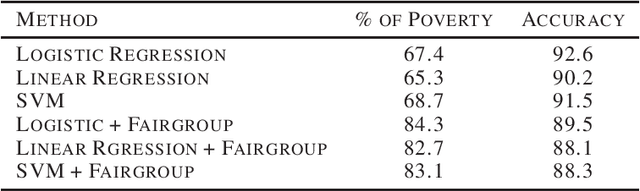
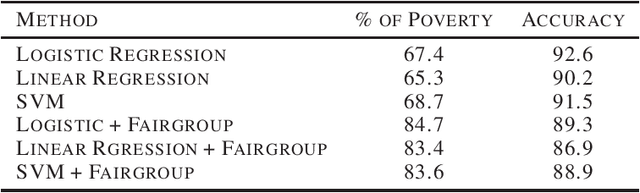
Effective complements to human judgment, artificial intelligence techniques have started to aid human decisions in complicated social problems across the world. In the context of United States for instance, automated ML/DL classification models offer complements to human decisions in determining Medicaid eligibility. However, given the limitations in ML/DL model design, these algorithms may fail to leverage various factors for decision making, resulting in improper decisions that allocate resources to individuals who may not be in the most need. In view of such an issue, we propose in this paper the method of \textit{fairgroup construction}, based on the legal doctrine of \textit{disparate impact}, to improve the fairness of regressive classifiers. Experiments on American Community Survey dataset demonstrate that our method could be easily adapted to a variety of regressive classification models to boost their fairness in deciding Medicaid Eligibility, while maintaining high levels of classification accuracy.