 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Device Scheduling and Resource Allocation for Latency Constrained Wireless Federated Learning
Jul 14, 2020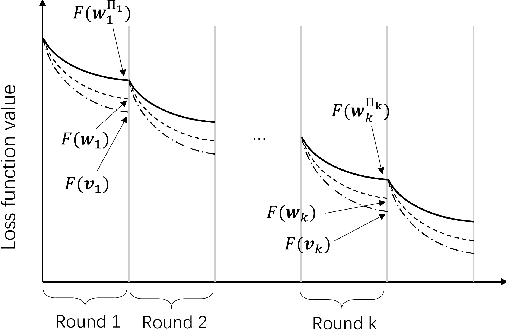
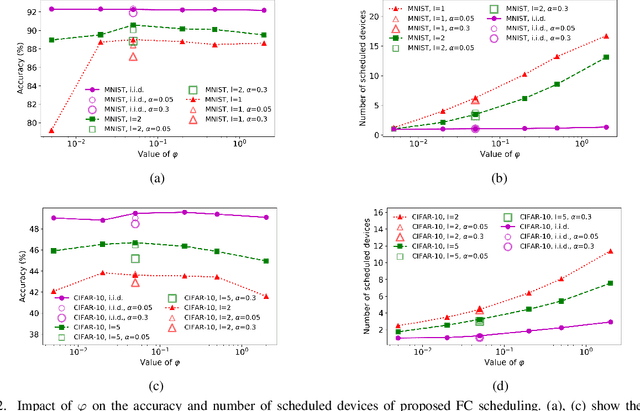
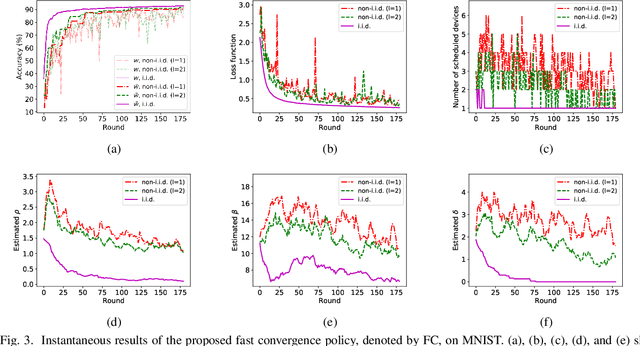
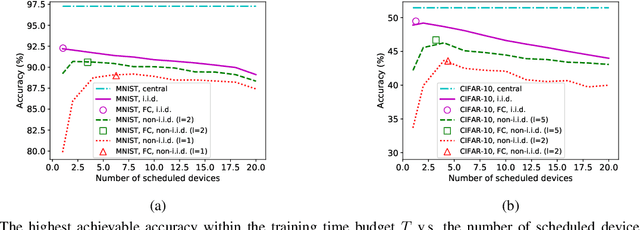
In federated learning (FL), devices contribute to the global training by uploading their local model updates via wireless channels. Due to limited computation and communication resources, device scheduling is crucial to the convergence rate of FL. In this paper, we propose a joint device scheduling and resource allocation policy to maximize the model accuracy within a given total training time budget for latency constrained wireless FL. A lower bound on the reciprocal of the training performance loss, in terms of the number of training rounds and the number of scheduled devices per round, is derived. Based on the bound, the accuracy maximization problem is solved by decoupling it into two sub-problems. First, given the scheduled devices, the optimal bandwidth allocation suggests allocating more bandwidth to the devices with worse channel conditions or weaker computation capabilities. Then, a greedy device scheduling algorithm is introduced, which in each step selects the device consuming the least updating time obtained by the optimal bandwidth allocation, until the lower bound begins to increase, meaning that scheduling more devices will degrade the model accuracy. Experiments show that the proposed policy outperforms state-of-the-art scheduling policies under extensive settings of data distributions and cell radius.
Improving Device-Edge Cooperative Inference of Deep Learning via 2-Step Pruning
Mar 08, 2019

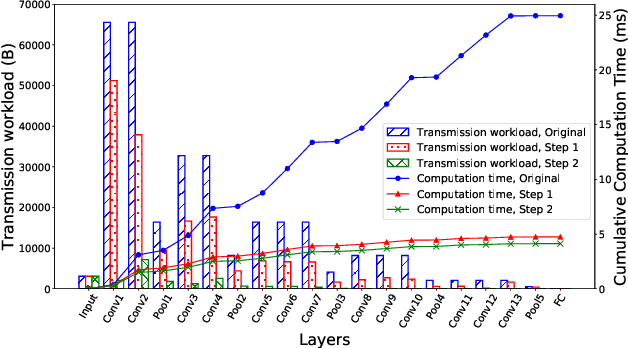

Deep neural networks (DNNs) are state-of-the-art solutions for many machine learning applications, and have been widely used on mobile devices. Running DNNs on resource-constrained mobile devices often requires the help from edge servers via computation offloading. However, offloading through a bandwidth-limited wireless link is non-trivial due to the tight interplay between the computation resources on mobile devices and wireless resources. Existing studies have focused on cooperative inference where DNN models are partitioned at different neural network layers, and the two parts are executed at the mobile device and the edge server, respectively. Since the output data size of a DNN layer can be larger than that of the raw data, offloading intermediate data between layers can suffer from high transmission latency under limited wireless bandwidth. In this paper, we propose an efficient and flexible 2-step pruning framework for DNN partition between mobile devices and edge servers. In our framework, the DNN model only needs to be pruned once in the training phase where unimportant convolutional filters are removed iteratively. By limiting the pruning region, our framework can greatly reduce either the wireless transmission workload of the device or the total computation workload. A series of pruned models are generated in the training phase, from which the framework can automatically select to satisfy varying latency and accuracy requirements. Furthermore, coding for the intermediate data is added to provide extra transmission workload reduction. Our experiments show that the proposed framework can achieve up to 25.6$\times$ reduction on transmission workload, 6.01$\times$ acceleration on total computation and 4.81$\times$ reduction on end-to-end latency as compared to partitioning the original DNN model without pruning.