 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCsT: Graph Convolutional Skeleton Transformer for Action Recognition
Sep 10, 2021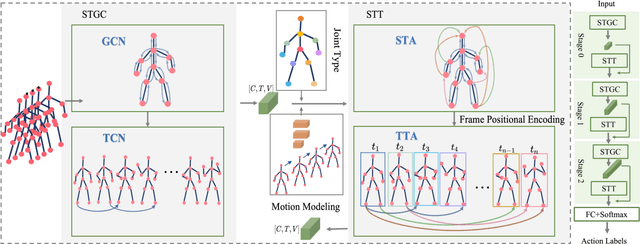
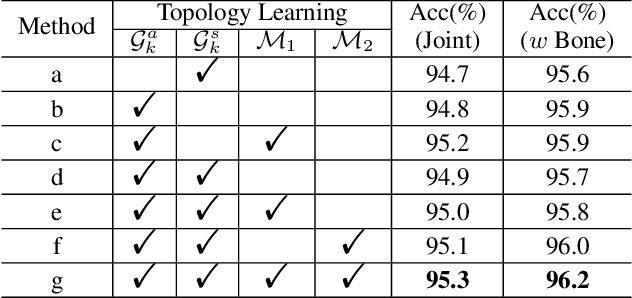
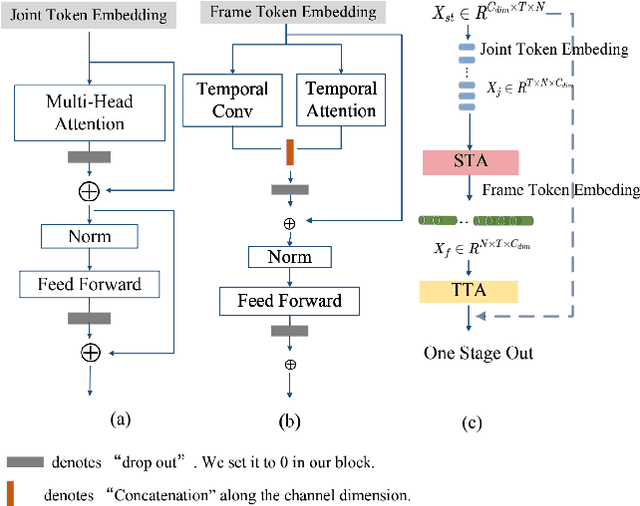
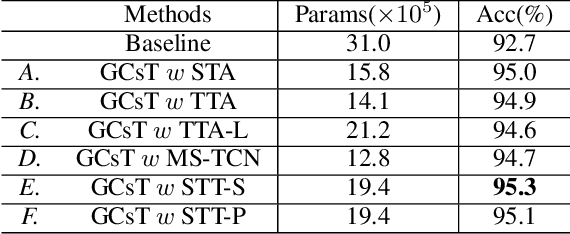
Graph convolutional networks (GCNs) achieve promising performance for skeleton-based action recognition. However, in most GCN-based methods, the spatial-temporal graph convolution is strictly restricted by the graph topology while only captures the short-term temporal context, thus lacking the flexibility of feature extraction. In this work, we present a novel architecture, named Graph Convolutional skeleton Transformer (GCsT), which addresses limitations in GCNs by introducing Transformer. Our GCsT employs all the benefits of Transformer (i.e. dynamical attention and global context) while keeps the advantages of GCNs (i.e. hierarchy and local topology structure). In GCsT, the spatial-temporal GCN forces the capture of local dependencies while Transformer dynamically extracts global spatial-temporal relationships. Furthermore, the proposed GCsT shows stronger expressive capability by adding additional information present in skeleton sequences. Incorporating the Transformer allows that information to be introduced into the model almost effortlessly. We validate the proposed GCsT by conducting extensive experiments, which achieves the state-of-the-art performance on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA datasets.