 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Guided Image Editing with Automatic Concept Locating and Forgetting
Paper and Code
May 30, 2024
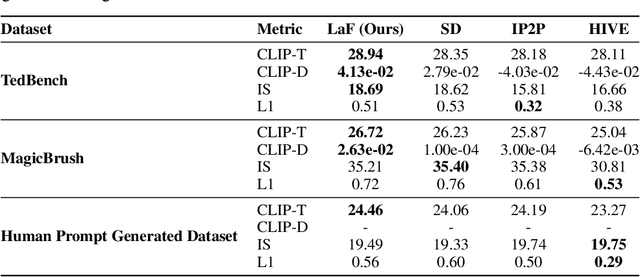

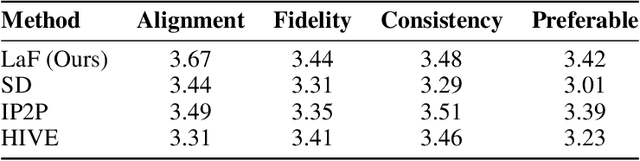
With the advancement of image-to-image diffusion models guided by text, significant progress has been made in image editing. However, a persistent challenge remains in seamlessly incorporating objects into images based on textual instructions, without relying on extra user-provided guidance. Text and images are inherently distinct modalities, bringing out difficulties in fully capturing the semantic intent conveyed through language and accurately translating that into the desired visual modifications. Therefore, text-guided image editing models often produce generations with residual object attributes that do not fully align with human expectations. To address this challenge, the models should comprehend the image content effectively away from a disconnect between the provided textual editing prompts and the actual modifications made to the image. In our paper, we propose a novel method called Locate and Forget (LaF), which effectively locates potential target concepts in the image for modification by comparing the syntactic trees of the target prompt and scene descriptions in the input image, intending to forget their existence clues in the generated image. Compared to the baselines, our method demonstrates its superiority in text-guided image editing tasks both qualitatively and quantitatively.