 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleSculptor: Zero-Shot Style-Controllable 3D Asset Generation with Texture-Geometry Dual Guidance
Sep 16, 2025Creating 3D assets that follow the texture and geometry style of existing ones is often desirable or even inevitable in practical applications like video gaming and virtual reality. While impressive progress has been made in generating 3D objects from text or images, creating style-controllable 3D assets remains a complex and challenging problem. In this work, we propose StyleSculptor, a novel training-free approach for generating style-guided 3D assets from a content image and one or more style images. Unlike previous works, StyleSculptor achieves style-guided 3D generation in a zero-shot manner, enabling fine-grained 3D style control that captures the texture, geometry, or both styles of user-provided style images. At the core of StyleSculptor is a novel Style Disentangled Attention (SD-Attn) module, which establishes a dynamic interaction between the input content image and style image for style-guided 3D asset generation via a cross-3D attention mechanism, enabling stable feature fusion and effective style-guided generation. To alleviate semantic content leakage, we also introduce a style-disentangled feature selection strategy within the SD-Attn module, which leverages the variance of 3D feature patches to disentangle style- and content-significant channels, allowing selective feature injection within the attention framework. With SD-Attn, the network can dynamically compute texture-, geometry-, or both-guided features to steer the 3D generation process. Built upon this, we further propose the Style Guided Control (SGC) mechanism, which enables exclusive geometry- or texture-only stylization, as well as adjustable style intensity control. Extensive experiments demonstrate that StyleSculptor outperforms existing baseline methods in producing high-fidelity 3D assets.
LuSh-NeRF: Lighting up and Sharpening NeRFs for Low-light Scenes
Nov 11, 2024



Neural Radiance Fields (NeRFs) have shown remarkable performances in producing novel-view images from high-quality scene images. However, hand-held low-light photography challenges NeRFs as the captured images may simultaneously suffer from low visibility, noise, and camera shakes. While existing NeRF methods may handle either low light or motion, directly combining them or incorporating additional image-based enhancement methods does not work as these degradation factors are highly coupled. We observe that noise in low-light images is always sharp regardless of camera shakes, which implies an implicit order of these degradation factors within the image formation process. To this end, we propose in this paper a novel model, named LuSh-NeRF, which can reconstruct a clean and sharp NeRF from a group of hand-held low-light images. The key idea of LuSh-NeRF is to sequentially model noise and blur in the images via multi-view feature consistency and frequency information of NeRF, respectively. Specifically, LuSh-NeRF includes a novel Scene-Noise Decomposition (SND) module for decoupling the noise from the scene representation and a novel Camera Trajectory Prediction (CTP) module for the estimation of camera motions based on low-frequency scene information. To facilitate training and evaluations, we construct a new dataset containing both synthetic and real images. Experiments show that LuSh-NeRF outperforms existing approaches. Our code and dataset can be found here: https://github.com/quzefan/LuSh-NeRF.
DROP: Decouple Re-Identification and Human Parsing with Task-specific Features for Occluded Person Re-identification
Jan 31, 2024The paper introduces the Decouple Re-identificatiOn and human Parsing (DROP) method for occluded person re-identification (ReID). Unlike mainstream approaches using global features for simultaneous multi-task learning of ReID and human parsing, or relying on semantic information for attention guidance, DROP argues that the inferior performance of the former is due to distinct granularity requirements for ReID and human parsing features. ReID focuses on instance part-level differences between pedestrian parts, while human parsing centers on semantic spatial context, reflecting the internal structure of the human body. To address this, DROP decouples features for ReID and human parsing, proposing detail-preserving upsampling to combine varying resolution feature maps. Parsing-specific features for human parsing are decoupled, and human position information is exclusively added to the human parsing branch. In the ReID branch, a part-aware compactness loss is introduced to enhance instance-level part differences. Experimental results highlight the efficacy of DROP, especially achieving a Rank-1 accuracy of 76.8% on Occluded-Duke, surpassing two mainstream methods. The codebase is accessible at https://github.com/shuguang-52/DROP.
Online Video Quality Enhancement with Spatial-Temporal Look-up Tables
Nov 22, 2023

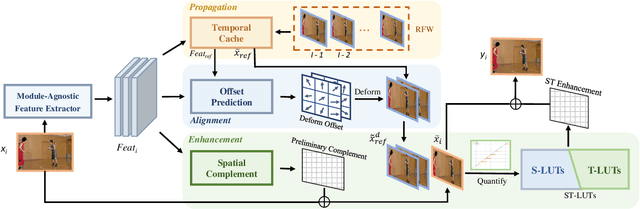

Low latency rates are crucial for online video-based applications, such as video conferencing and cloud gaming, which make improving video quality in online scenarios increasingly important. However, existing quality enhancement methods are limited by slow inference speed and the requirement for temporal information contained in future frames, making it challenging to deploy them directly in online tasks. In this paper, we propose a novel method, STLVQE, specifically designed to address the rarely studied online video quality enhancement (Online-VQE) problem. Our STLVQE designs a new VQE framework which contains a Module-Agnostic Feature Extractor that greatly reduces the redundant computations and redesign the propagation, alignment, and enhancement module of the network. A Spatial-Temporal Look-up Tables (STL) is proposed, which extracts spatial-temporal information in videos while saving substantial inference time. To the best of our knowledge, we are the first to exploit the LUT structure to extract temporal information in video tasks. Extensive experiments on the MFQE 2.0 dataset demonstrate that our STLVQE achieves a satisfactory performance-speed trade-off.