 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Video Quality Enhancement with Spatial-Temporal Look-up Tables
Paper and Code
Nov 22, 2023

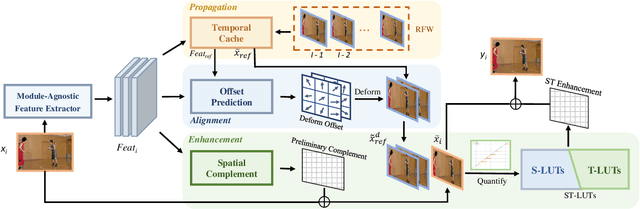

Low latency rates are crucial for online video-based applications, such as video conferencing and cloud gaming, which make improving video quality in online scenarios increasingly important. However, existing quality enhancement methods are limited by slow inference speed and the requirement for temporal information contained in future frames, making it challenging to deploy them directly in online tasks. In this paper, we propose a novel method, STLVQE, specifically designed to address the rarely studied online video quality enhancement (Online-VQE) problem. Our STLVQE designs a new VQE framework which contains a Module-Agnostic Feature Extractor that greatly reduces the redundant computations and redesign the propagation, alignment, and enhancement module of the network. A Spatial-Temporal Look-up Tables (STL) is proposed, which extracts spatial-temporal information in videos while saving substantial inference time. To the best of our knowledge, we are the first to exploit the LUT structure to extract temporal information in video tasks. Extensive experiments on the MFQE 2.0 dataset demonstrate that our STLVQE achieves a satisfactory performance-speed trade-off.