 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend to Who You Are: Supervising Self-Attention for Keypoint Detection and Instance-Aware Association
Paper and Code

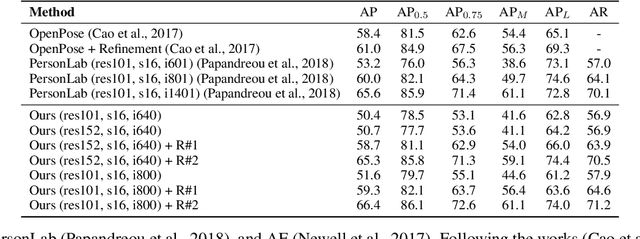
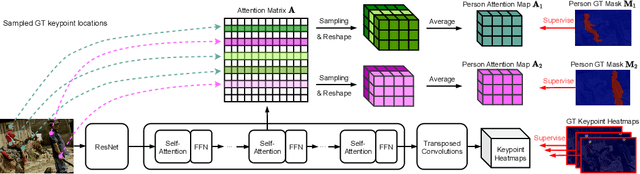
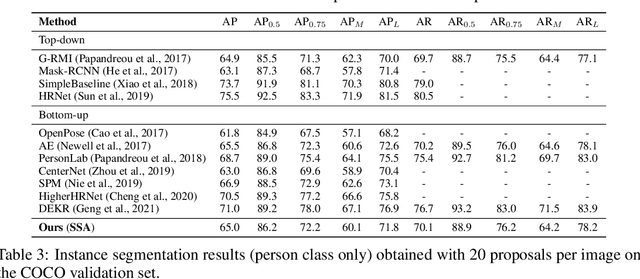
This paper presents a new method to solve keypoint detection and instance association by using Transformer. For bottom-up multi-person pose estimation models, they need to detect keypoints and learn associative information between keypoints. We argue that these problems can be entirely solved by Transformer. Specifically, the self-attention in Transformer measures dependencies between any pair of locations, which can provide association information for keypoints grouping. However, the naive attention patterns are still not subjectively controlled, so there is no guarantee that the keypoints will always attend to the instances to which they belong. To address it we propose a novel approach of supervising self-attention for multi-person keypoint detection and instance association. By using instance masks to supervise self-attention to be instance-aware, we can assign the detected keypoints to their corresponding instances based on the pairwise attention scores, without using pre-defined offset vector fields or embedding like CNN-based bottom-up models. An additional benefit of our method is that the instance segmentation results of any number of people can be directly obtained from the supervised attention matrix, thereby simplifying the pixel assignment pipeline. The experiments on the COCO multi-person keypoint detection challenge and person instance segmentation task demonstrate the effectiveness and simplicity of the proposed method and show a promising way to control self-attention behavior for specific purposes.