 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend to Who You Are: Supervising Self-Attention for Keypoint Detection and Instance-Aware Association
Nov 25, 2021
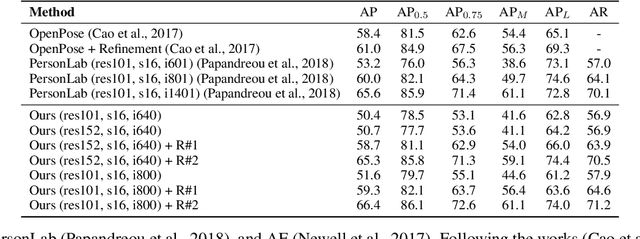
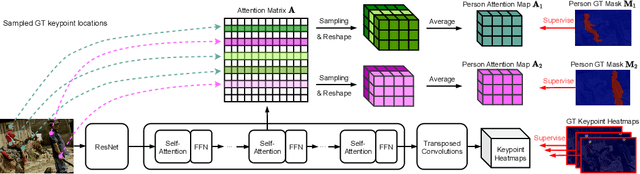
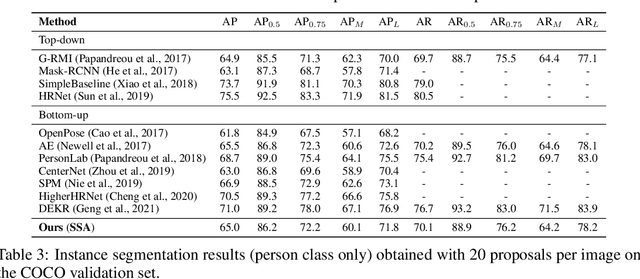
This paper presents a new method to solve keypoint detection and instance association by using Transformer. For bottom-up multi-person pose estimation models, they need to detect keypoints and learn associative information between keypoints. We argue that these problems can be entirely solved by Transformer. Specifically, the self-attention in Transformer measures dependencies between any pair of locations, which can provide association information for keypoints grouping. However, the naive attention patterns are still not subjectively controlled, so there is no guarantee that the keypoints will always attend to the instances to which they belong. To address it we propose a novel approach of supervising self-attention for multi-person keypoint detection and instance association. By using instance masks to supervise self-attention to be instance-aware, we can assign the detected keypoints to their corresponding instances based on the pairwise attention scores, without using pre-defined offset vector fields or embedding like CNN-based bottom-up models. An additional benefit of our method is that the instance segmentation results of any number of people can be directly obtained from the supervised attention matrix, thereby simplifying the pixel assignment pipeline. The experiments on the COCO multi-person keypoint detection challenge and person instance segmentation task demonstrate the effectiveness and simplicity of the proposed method and show a promising way to control self-attention behavior for specific purposes.
SIENet: Spatial Information Enhancement Network for 3D Object Detection from Point Cloud
Apr 01, 2021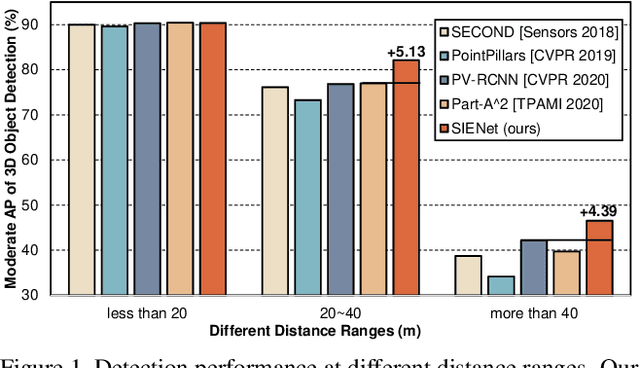
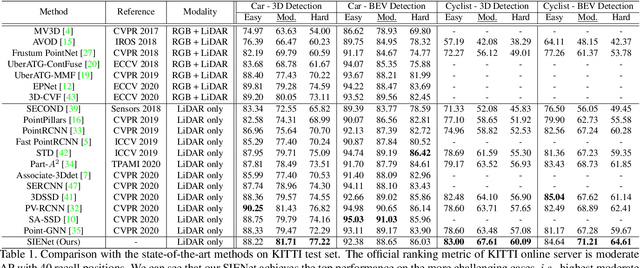
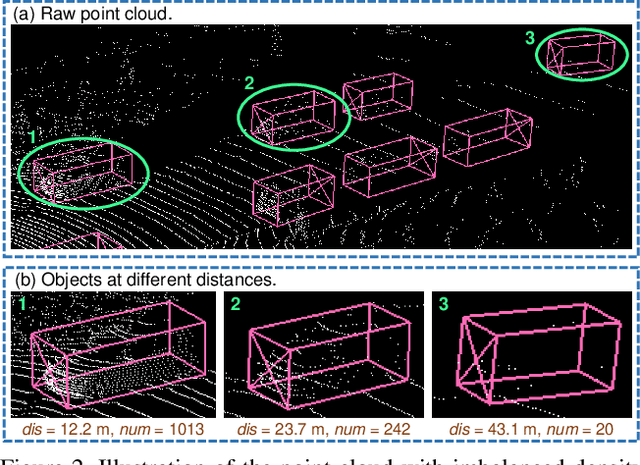
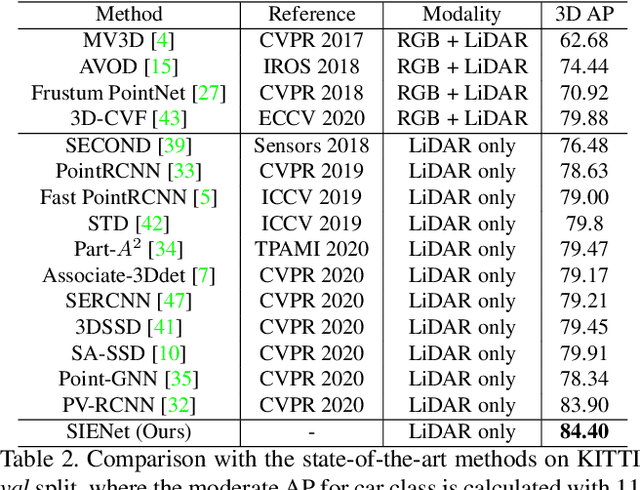
LiDAR-based 3D object detection pushes forward an immense influence on autonomous vehicles. Due to the limitation of the intrinsic properties of LiDAR, fewer points are collected at the objects farther away from the sensor. This imbalanced density of point clouds degrades the detection accuracy but is generally neglected by previous works. To address the challenge, we propose a novel two-stage 3D object detection framework, named SIENet. Specifically, we design the Spatial Information Enhancement (SIE) module to predict the spatial shapes of the foreground points within proposals, and extract the structure information to learn the representative features for further box refinement. The predicted spatial shapes are complete and dense point sets, thus the extracted structure information contains more semantic representation. Besides, we design the Hybrid-Paradigm Region Proposal Network (HP-RPN) which includes multiple branches to learn discriminate features and generate accurate proposals for the SIE module. Extensive experiments on the KITTI 3D object detection benchmark show that our elaborately designed SIENet outperforms the state-of-the-art methods by a large margin.
TransPose: Towards Explainable Human Pose Estimation by Transformer
Dec 31, 2020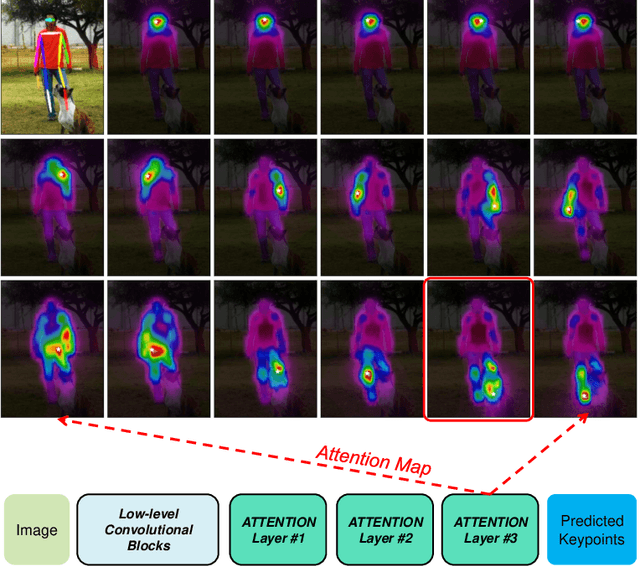
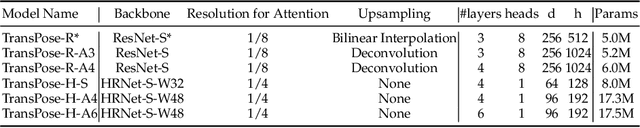
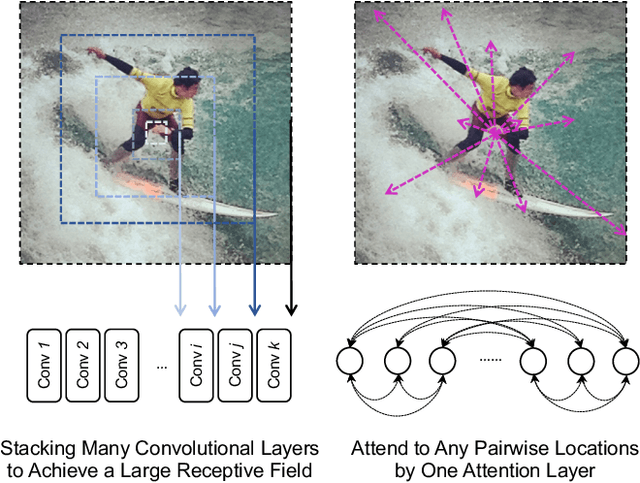
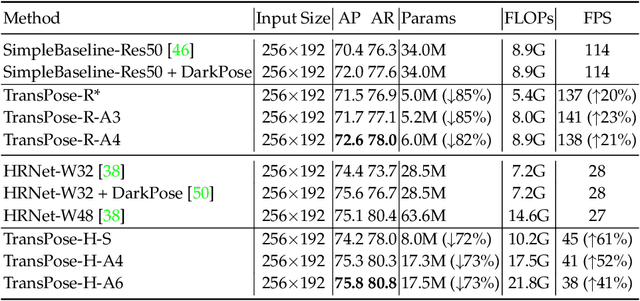
Deep Convolutional Neural Networks (CNNs) have made remarkable progress on human pose estimation task. However, there is no explicit understanding of how the locations of body keypoints are predicted by CNN, and it is also unknown what spatial dependency relationships between structural variables are learned in the model. To explore these questions, we construct an explainable model named TransPose based on Transformer architecture and low-level convolutional blocks. Given an image, the attention layers built in Transformer can capture long-range spatial relationships between keypoints and explain what dependencies the predicted keypoints locations highly rely on. We analyze the rationality of using attention as the explanation to reveal the spatial dependencies in this task. The revealed dependencies are image-specific and variable for different keypoint types, layer depths, or trained models. The experiments show that TransPose can accurately predict the positions of keypoints. It achieves state-of-the-art performance on COCO dataset, while being more interpretable, lightweight, and efficient than mainstream fully convolutional architectures.