 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend to Who You Are: Supervising Self-Attention for Keypoint Detection and Instance-Aware Association
Nov 25, 2021
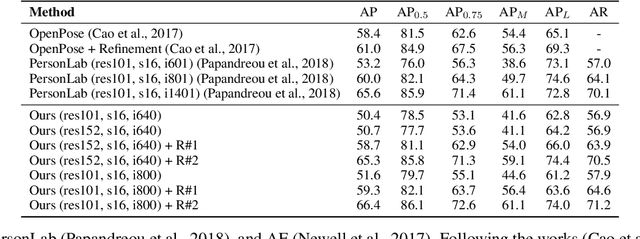
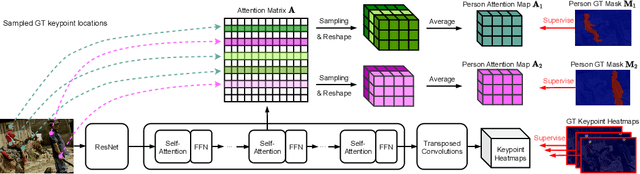
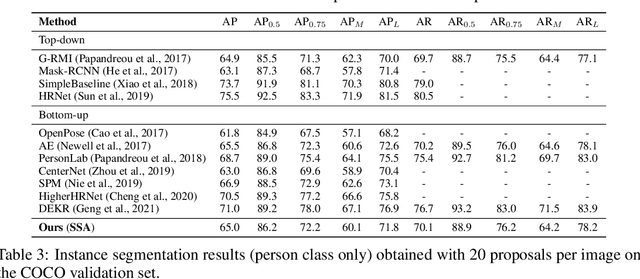
This paper presents a new method to solve keypoint detection and instance association by using Transformer. For bottom-up multi-person pose estimation models, they need to detect keypoints and learn associative information between keypoints. We argue that these problems can be entirely solved by Transformer. Specifically, the self-attention in Transformer measures dependencies between any pair of locations, which can provide association information for keypoints grouping. However, the naive attention patterns are still not subjectively controlled, so there is no guarantee that the keypoints will always attend to the instances to which they belong. To address it we propose a novel approach of supervising self-attention for multi-person keypoint detection and instance association. By using instance masks to supervise self-attention to be instance-aware, we can assign the detected keypoints to their corresponding instances based on the pairwise attention scores, without using pre-defined offset vector fields or embedding like CNN-based bottom-up models. An additional benefit of our method is that the instance segmentation results of any number of people can be directly obtained from the supervised attention matrix, thereby simplifying the pixel assignment pipeline. The experiments on the COCO multi-person keypoint detection challenge and person instance segmentation task demonstrate the effectiveness and simplicity of the proposed method and show a promising way to control self-attention behavior for specific purposes.
Is 2D Heatmap Representation Even Necessary for Human Pose Estimation?
Jul 11, 2021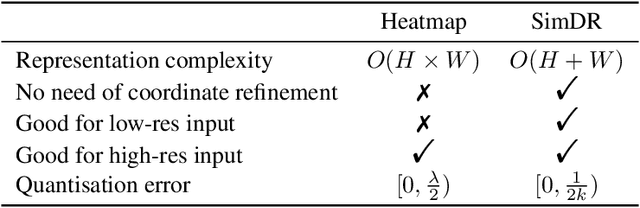
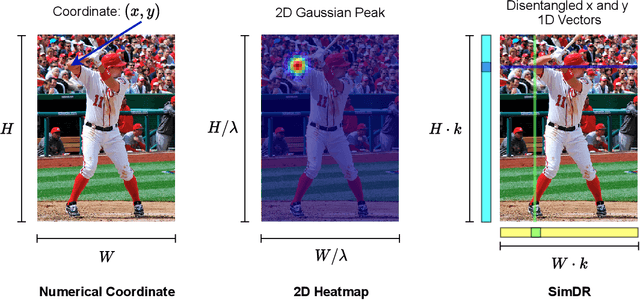
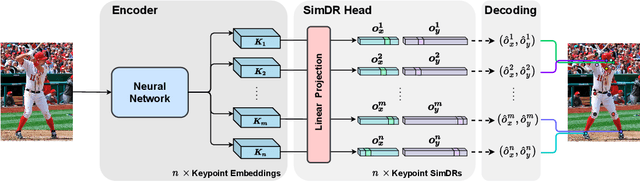
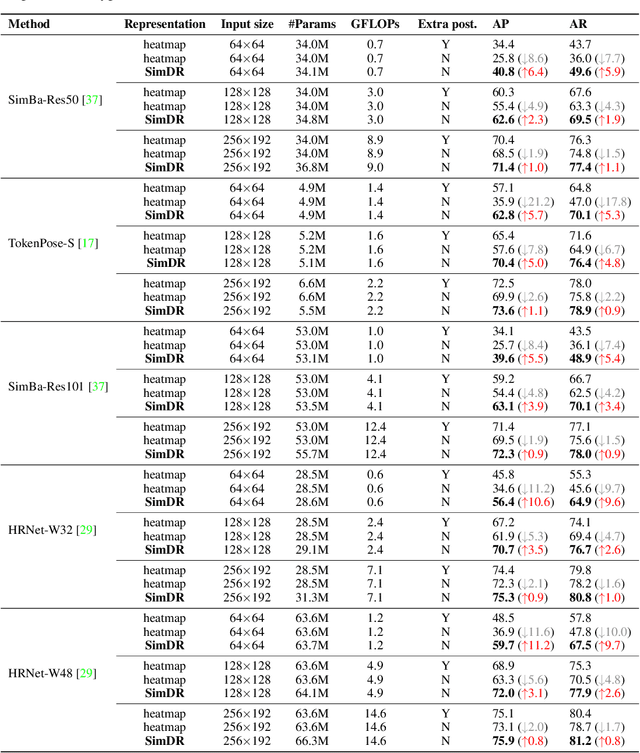
The 2D heatmap representation has dominated human pose estimation for years due to its high performance. However, heatmap-based approaches have some drawbacks: 1) The performance drops dramatically in the low-resolution images, which are frequently encountered in real-world scenarios. 2) To improve the localization precision, multiple upsample layers may be needed to recover the feature map resolution from low to high, which are computationally expensive. 3) Extra coordinate refinement is usually necessary to reduce the quantization error of downscaled heatmaps. To address these issues, we propose a \textbf{Sim}ple yet promising \textbf{D}isentangled \textbf{R}epresentation for keypoint coordinate (\emph{SimDR}), reformulating human keypoint localization as a task of classification. In detail, we propose to disentangle the representation of horizontal and vertical coordinates for keypoint location, leading to a more efficient scheme without extra upsampling and refinement. Comprehensive experiments conducted over COCO dataset show that the proposed \emph{heatmap-free} methods outperform \emph{heatmap-based} counterparts in all tested input resolutions, especially in lower resolutions by a large margin. Code will be made publicly available at \url{https://github.com/leeyegy/SimDR}.
TokenPose: Learning Keypoint Tokens for Human Pose Estimation
Apr 09, 2021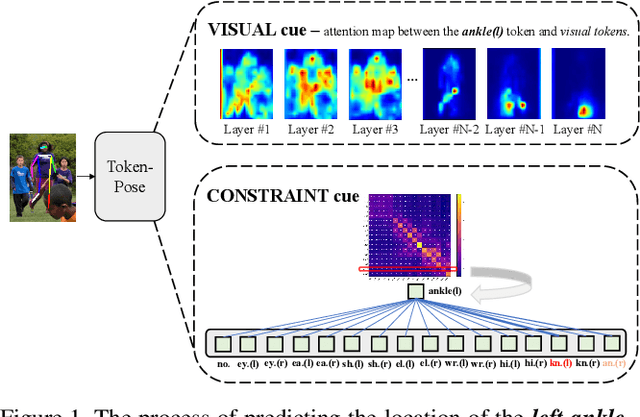

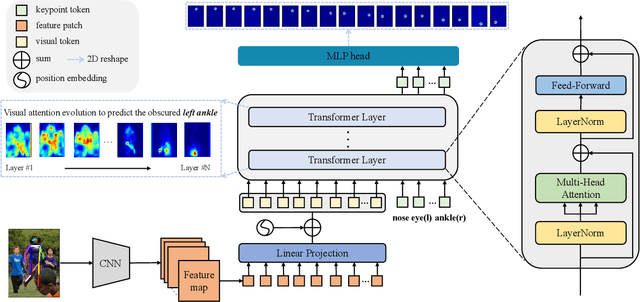

Human pose estimation deeply relies on visual clues and anatomical constraints between parts to locate keypoints. Most existing CNN-based methods do well in visual representation, however, lacking in the ability to explicitly learn the constraint relationships between keypoints. In this paper, we propose a novel approach based on Token representation for human Pose estimation~(TokenPose). In detail, each keypoint is explicitly embedded as a token to simultaneously learn constraint relationships and appearance cues from images. Extensive experiments show that the small and large TokenPose models are on par with state-of-the-art CNN-based counterparts while being more lightweight. Specifically, our TokenPose-S and TokenPose-L achieve 72.5 AP and 75.8 AP on COCO validation dataset respectively, with significant reduction in parameters ($\downarrow80.6\%$ ; $\downarrow$ $56.8\%$) and GFLOPs ($\downarrow$$ 75.3\%$; $\downarrow$ $24.7\%$).