 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenPose: Learning Keypoint Tokens for Human Pose Estimation
Paper and Code
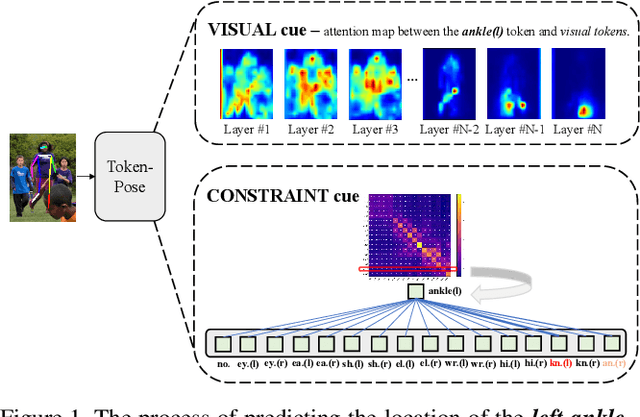

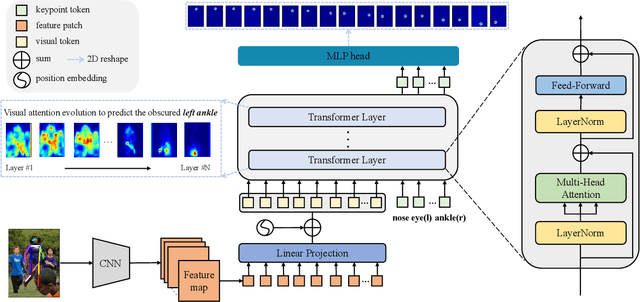

Human pose estimation deeply relies on visual clues and anatomical constraints between parts to locate keypoints. Most existing CNN-based methods do well in visual representation, however, lacking in the ability to explicitly learn the constraint relationships between keypoints. In this paper, we propose a novel approach based on Token representation for human Pose estimation~(TokenPose). In detail, each keypoint is explicitly embedded as a token to simultaneously learn constraint relationships and appearance cues from images. Extensive experiments show that the small and large TokenPose models are on par with state-of-the-art CNN-based counterparts while being more lightweight. Specifically, our TokenPose-S and TokenPose-L achieve 72.5 AP and 75.8 AP on COCO validation dataset respectively, with significant reduction in parameters ($\downarrow80.6\%$ ; $\downarrow$ $56.8\%$) and GFLOPs ($\downarrow$$ 75.3\%$; $\downarrow$ $24.7\%$).