 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Query Position and Performing Similar Attention for Transformer-Based Detection Heads
Aug 22, 2021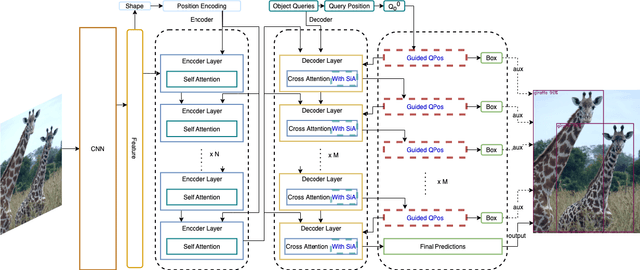
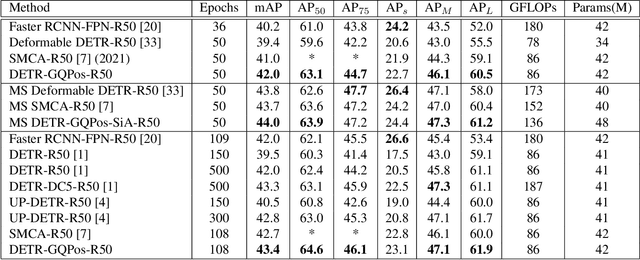


After DETR was proposed, this novel transformer-based detection paradigm which performs several cross-attentions between object queries and feature maps for predictions has subsequently derived a series of transformer-based detection heads. These models iterate object queries after each cross-attention. However, they don't renew the query position which indicates object queries' position information. Thus model needs extra learning to figure out the newest regions that query position should express and need more attention. To fix this issue, we propose the Guided Query Position (GQPos) method to embed the latest location information of object queries to query position iteratively. Another problem of such transformer-based detection heads is the high complexity to perform attention on multi-scale feature maps, which hinders them from improving detection performance at all scales. Therefore we propose a novel fusion scheme named Similar Attention (SiA): besides the feature maps is fused, SiA also fuse the attention weights maps to accelerate the learning of high-resolution attention weight map by well-learned low-resolution attention weight map. Our experiments show that the proposed GQPos improves the performance of a series of models, including DETR, SMCA, YoloS, and HoiTransformer and SiA consistently improve the performance of multi-scale transformer-based detection heads like DETR and HoiTransformer.