 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Learning Prompt with Distribution-Based Feature Replay for Few-Shot Class-Incremental Learning
Jan 03, 2024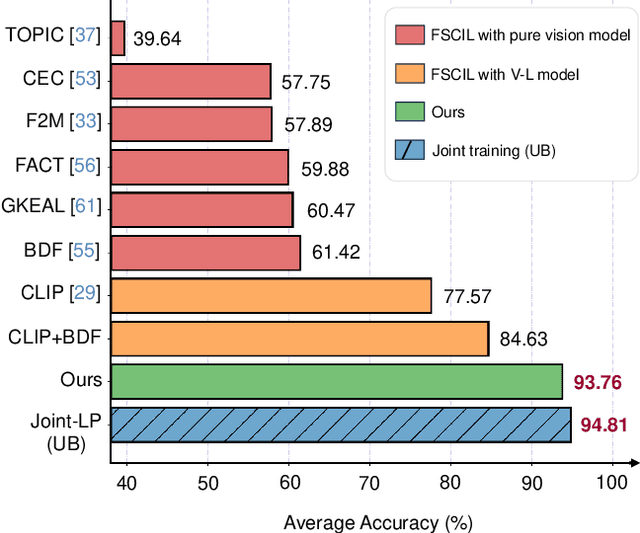



Few-shot Class-Incremental Learning (FSCIL) aims to continuously learn new classes based on very limited training data without forgetting the old ones encountered. Existing studies solely relied on pure visual networks, while in this paper we solved FSCIL by leveraging the Vision-Language model (e.g., CLIP) and propose a simple yet effective framework, named Learning Prompt with Distribution-based Feature Replay (LP-DiF). We observe that simply using CLIP for zero-shot evaluation can substantially outperform the most influential methods. Then, prompt tuning technique is involved to further improve its adaptation ability, allowing the model to continually capture specific knowledge from each session. To prevent the learnable prompt from forgetting old knowledge in the new session, we propose a pseudo-feature replay approach. Specifically, we preserve the old knowledge of each class by maintaining a feature-level Gaussian distribution with a diagonal covariance matrix, which is estimated by the image features of training images and synthesized features generated from a VAE. When progressing to a new session, pseudo-features are sampled from old-class distributions combined with training images of the current session to optimize the prompt, thus enabling the model to learn new knowledge while retaining old knowledge. Experiments on three prevalent benchmarks, i.e., CIFAR100, mini-ImageNet, CUB-200, and two more challenging benchmarks, i.e., SUN-397 and CUB-200$^*$ proposed in this paper showcase the superiority of LP-DiF, achieving new state-of-the-art (SOTA) in FSCIL. Code is publicly available at https://github.com/1170300714/LP-DiF.