 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fall of ROME: Understanding the Collapse of LLMs in Model Editing
Paper and Code
Jun 17, 2024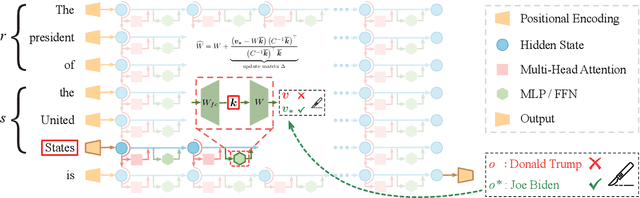
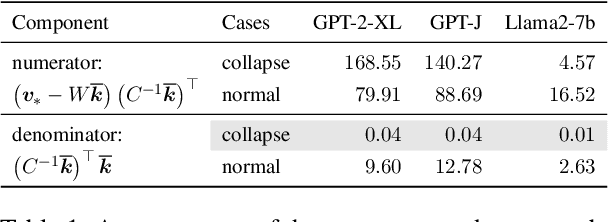
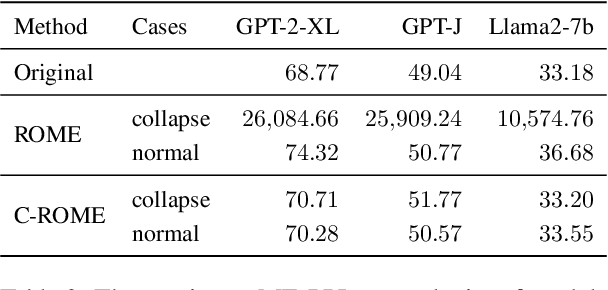
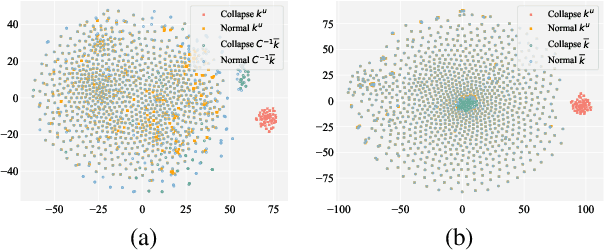
Despite significant progress in model editing methods, their application in real-world scenarios remains challenging as they often cause large language models (LLMs) to collapse. Among them, ROME is particularly concerning, as it could disrupt LLMs with only a single edit. In this paper, we study the root causes of such collapse. Through extensive analysis, we identify two primary factors that contribute to the collapse: i) inconsistent handling of prefixed and unprefixed keys in the parameter update equation may result in very small denominators, causing excessively large parameter updates; ii) the subject of collapse cases is usually the first token, whose unprefixed key distribution significantly differs from the prefixed key distribution in autoregressive transformers, causing the aforementioned issue to materialize. To validate our analysis, we propose a simple yet effective approach: uniformly using prefixed keys during editing phase and adding prefixes during the testing phase. The experimental results show that the proposed solution can prevent model collapse while maintaining the effectiveness of the edits.