 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Utility Conflicts Are Not Global: Surgical Alignment via Head-Level Diagnosis
Jan 07, 2026Safety alignment in Large Language Models (LLMs) inherently presents a multi-objective optimization conflict, often accompanied by an unintended degradation of general capabilities. Existing mitigation strategies typically rely on global gradient geometry to resolve these conflicts, yet they overlook Modular Heterogeneity within Transformers, specifically that the functional sensitivity and degree of conflict vary substantially across different attention heads. Such global approaches impose uniform update rules across all parameters, often resulting in suboptimal trade-offs by indiscriminately updating utility sensitive heads that exhibit intense gradient conflicts. To address this limitation, we propose Conflict-Aware Sparse Tuning (CAST), a framework that integrates head-level diagnosis with sparse fine-tuning. CAST first constructs a pre-alignment conflict map by synthesizing Optimization Conflict and Functional Sensitivity, which then guides the selective update of parameters. Experiments reveal that alignment conflicts in LLMs are not uniformly distributed. We find that the drop in general capabilities mainly comes from updating a small group of ``high-conflict'' heads. By simply skipping these heads during training, we significantly reduce this loss without compromising safety, offering an interpretable and parameter-efficient approach to improving the safety-utility trade-off.
Token-Level Policy Optimization: Linking Group-Level Rewards to Token-Level Aggregation via Markov Likelihood
Oct 10, 2025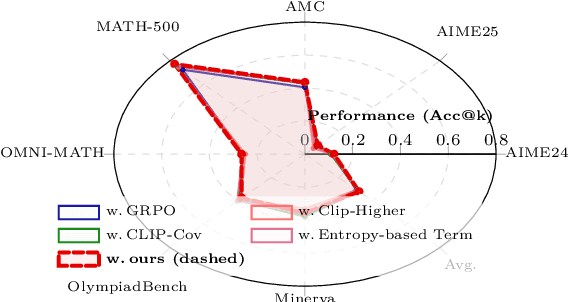
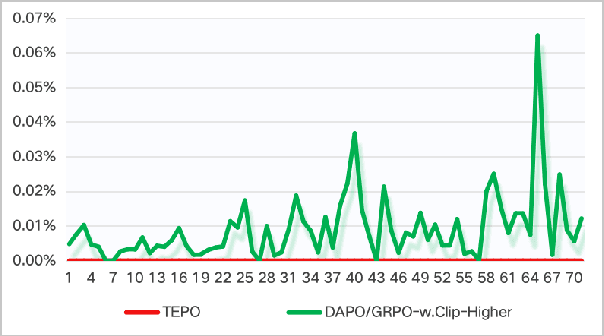
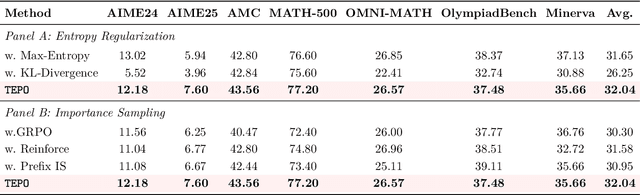
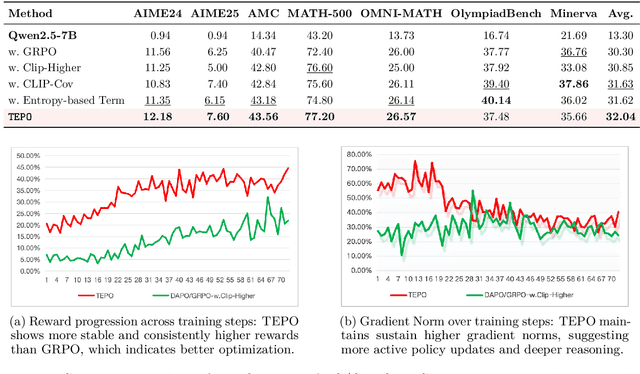
Group Relative Policy Optimization (GRPO) has significantly advanced the reasoning ability of large language models (LLMs), particularly by boosting their mathematical performance. However, GRPO and related entropy-regularization methods still face challenges rooted in the sparse token rewards inherent to chain-of-thought (CoT). Current approaches often rely on undifferentiated token-level entropy adjustments, which frequently lead to entropy collapse or model collapse. In this work, we propose TEPO, a novel token-level framework that incorporates Markov Likelihood (sequence likelihood) links group-level rewards with tokens via token-level aggregation. Experiments show that TEPO consistently outperforms existing baselines across key metrics (including @k and accuracy). It not only sets a new state of the art on mathematical reasoning tasks but also significantly enhances training stability.
Knowledgeable-r1: Policy Optimization for Knowledge Exploration in Retrieval-Augmented Generation
Jun 05, 2025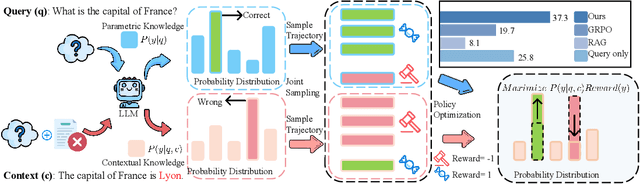

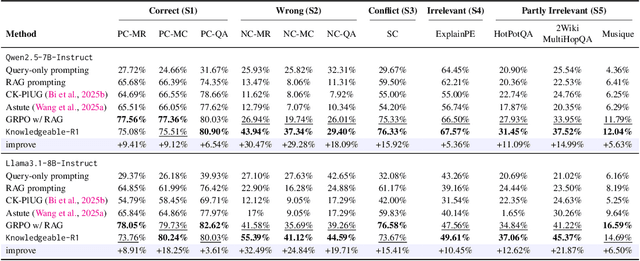
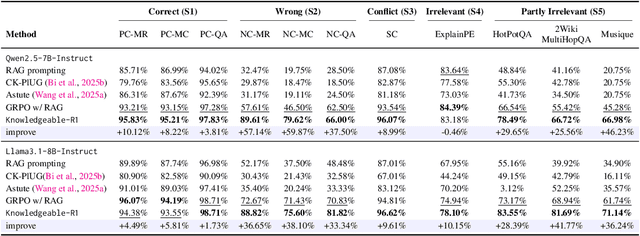
Retrieval-augmented generation (RAG) is a mainstream method for improving performance on knowledge-intensive tasks. However,current RAG systems often place too much emphasis on retrieved contexts. This can lead to reliance on inaccurate sources and overlook the model's inherent knowledge, especially when dealing with misleading or excessive information. To resolve this imbalance, we propose Knowledgeable-r1 that using joint sampling and define multi policy distributions in knowledge capability exploration to stimulate large language models'self-integrated utilization of parametric and contextual knowledge. Experiments show that Knowledgeable-r1 significantly enhances robustness and reasoning accuracy in both parameters and contextual conflict tasks and general RAG tasks, especially outperforming baselines by 17.07% in counterfactual scenarios and demonstrating consistent gains across RAG tasks. Our code are available at https://github.com/lcy80366872/ knowledgeable-r1.
Generative Hierarchical Temporal Transformer for Hand Action Recognition and Motion Prediction
Nov 29, 2023



We present a novel framework that concurrently tackles hand action recognition and 3D future hand motion prediction. While previous works focus on either recognition or prediction, we propose a generative Transformer VAE architecture to jointly capture both aspects, facilitating realistic motion prediction by leveraging the short-term hand motion and long-term action consistency observed across timestamps.To ensure faithful representation of the semantic dependency and different temporal granularity of hand pose and action, our framework is decomposed into two cascaded VAE blocks. The lower pose block models short-span poses, while the upper action block models long-span action. These are connected by a mid-level feature that represents sub-second series of hand poses.Our framework is trained across multiple datasets, where pose and action blocks are trained separately to fully utilize pose-action annotations of different qualities. Evaluations show that on multiple datasets, the joint modeling of recognition and prediction improves over separate solutions, and the semantic and temporal hierarchy enables long-term pose and action modeling.
MindMap: Knowledge Graph Prompting Sparks Graph of Thoughts in Large Language Models
Aug 28, 2023LLMs usually exhibit limitations in their ability to incorporate new knowledge, the generation of hallucinations, and the transparency of their decision-making process. In this paper, we explore how to prompt LLMs with knowledge graphs (KG), working as a remedy to engage LLMs with up-to-date knowledge and elicit the reasoning pathways from LLMs. Specifically, we build a prompting pipeline that endows LLMs with the capability of comprehending KG inputs and inferring with a combined implicit knowledge and the retrieved external knowledge. In addition, we investigate eliciting the mind map on which LLMs perform the reasoning and generate the answers. It is identified that the produced mind map exhibits the reasoning pathways of LLMs grounded on the ontology of knowledge, hence bringing the prospects of probing and gauging LLM inference in production. The experiments on three question & answering datasets also show that MindMap prompting leads to a striking empirical gain. For instance, prompting a GPT-3.5 with MindMap yields an overwhelming performance over GPT-4 consistently. We also demonstrate that with structured facts retrieved from KG, MindMap can outperform a series of prompting-with-document-retrieval methods, benefiting from more accurate, concise, and comprehensive knowledge from KGs.
IMKGA-SM: Interpretable Multimodal Knowledge Graph Answer Prediction via Sequence Modeling
Jan 11, 2023



Multimodal knowledge graph link prediction aims to improve the accuracy and efficiency of link prediction tasks for multimodal data. However, for complex multimodal information and sparse training data, it is usually difficult to achieve interpretability and high accuracy simultaneously for most methods. To address this difficulty, a new model is developed in this paper, namely Interpretable Multimodal Knowledge Graph Answer Prediction via Sequence Modeling (IMKGA-SM). First, a multi-modal fine-grained fusion method is proposed, and Vgg16 and Optical Character Recognition (OCR) techniques are adopted to effectively extract text information from images and images. Then, the knowledge graph link prediction task is modelled as an offline reinforcement learning Markov decision model, which is then abstracted into a unified sequence framework. An interactive perception-based reward expectation mechanism and a special causal masking mechanism are designed, which "converts" the query into an inference path. Then, an autoregressive dynamic gradient adjustment mechanism is proposed to alleviate the insufficient problem of multimodal optimization. Finally, two datasets are adopted for experiments, and the popular SOTA baselines are used for comparison. The results show that the developed IMKGA-SM achieves much better performance than SOTA baselines on multimodal link prediction datasets of different sizes.
Hierarchical Temporal Transformer for 3D Hand Pose Estimation and Action Recognition from Egocentric RGB Videos
Sep 20, 2022
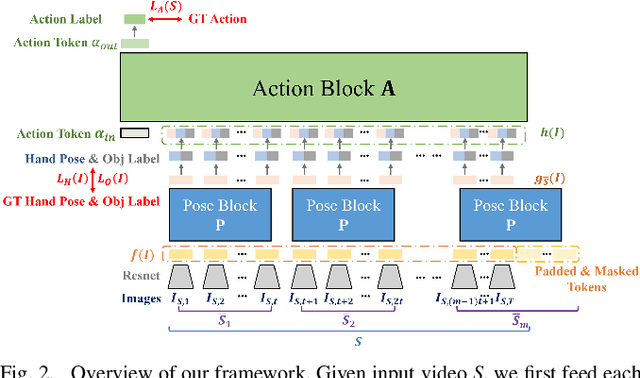


Understanding dynamic hand motions and actions from egocentric RGB videos is a fundamental yet challenging task due to self-occlusion and ambiguity. To address occlusion and ambiguity, we develop a transformer-based framework to exploit temporal information for robust estimation. Noticing the different temporal granularity of and the semantic correlation between hand pose estimation and action recognition, we build a network hierarchy with two cascaded transformer encoders, where the first one exploits the short-term temporal cue for hand pose estimation, and the latter aggregates per-frame pose and object information over a longer time span to recognize the action. Our approach achieves competitive results on two first-person hand action benchmarks, namely FPHA and H2O. Extensive ablation studies verify our design choices. We will open-source code and data to facilitate future research.
Gen6D: Generalizable Model-Free 6-DoF Object Pose Estimation from RGB Images
Apr 22, 2022
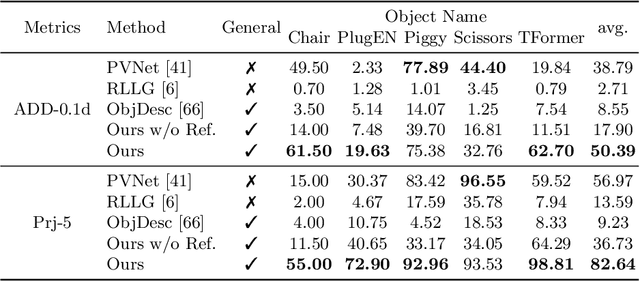

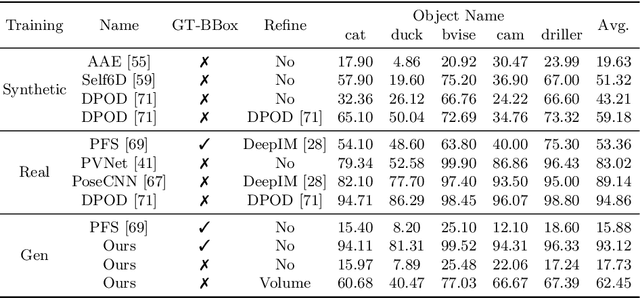
In this paper, we present a generalizable model-free 6-DoF object pose estimator called Gen6D. Existing generalizable pose estimators either need high-quality object models or require additional depth maps or object masks in test time, which significantly limits their application scope. In contrast, our pose estimator only requires some posed images of the unseen object and is able to accurately predict the poses of the object in arbitrary environments. Gen6D consists of an object detector, a viewpoint selector and a pose refiner, all of which do not require the 3D object model and can generalize to unseen objects. Experiments show that Gen6D achieves state-of-the-art results on two model-free datasets: the MOPED dataset and a new GenMOP dataset collected by us. In addition, on the LINEMOD dataset, Gen6D achieves competitive results compared with instance-specific pose estimators. Project page: https://liuyuan-pal.github.io/Gen6D/.
Disentangled Implicit Shape and Pose Learning for Scalable 6D Pose Estimation
Jul 27, 2021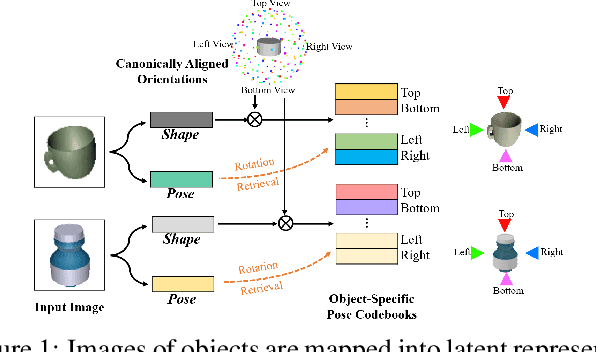
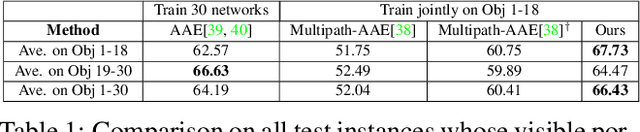
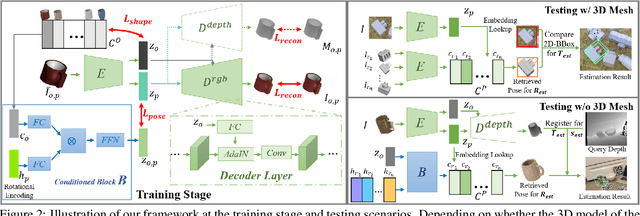

6D pose estimation of rigid objects from a single RGB image has seen tremendous improvements recently by using deep learning to combat complex real-world variations, but a majority of methods build models on the per-object level, failing to scale to multiple objects simultaneously. In this paper, we present a novel approach for scalable 6D pose estimation, by self-supervised learning on synthetic data of multiple objects using a single autoencoder. To handle multiple objects and generalize to unseen objects, we disentangle the latent object shape and pose representations, so that the latent shape space models shape similarities, and the latent pose code is used for rotation retrieval by comparison with canonical rotations. To encourage shape space construction, we apply contrastive metric learning and enable the processing of unseen objects by referring to similar training objects. The different symmetries across objects induce inconsistent latent pose spaces, which we capture with a conditioned block producing shape-dependent pose codebooks by re-entangling shape and pose representations. We test our method on two multi-object benchmarks with real data, T-LESS and NOCS REAL275, and show it outperforms existing RGB-based methods in terms of pose estimation accuracy and generalization.