 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Reinforcement Learning with Self-Reflection for Agentic Search
Mar 11, 2026This paper introduces MR-Search, an in-context meta reinforcement learning (RL) formulation for agentic search with self-reflection. Instead of optimizing a policy within a single independent episode with sparse rewards, MR-Search trains a policy that conditions on past episodes and adapts its search strategy across episodes. MR-Search learns to learn a search strategy with self-reflection, allowing search agents to improve in-context exploration at test-time. Specifically, MR-Search performs cross-episode exploration by generating explicit self-reflections after each episode and leveraging them as additional context to guide subsequent attempts, thereby promoting more effective exploration during test-time. We further introduce a multi-turn RL algorithm that estimates a dense relative advantage at the turn level, enabling fine-grained credit assignment on each episode. Empirical results across various benchmarks demonstrate the advantages of MR-Search over baselines based RL, showing strong generalization and relative improvements of 9.2% to 19.3% across eight benchmarks. Our code and data are available at https://github.com/tengxiao1/MR-Search.
Simple Denoising Diffusion Language Models
Oct 27, 2025Diffusion models have recently been extended to language generation through Masked Diffusion Language Models (MDLMs), which achieve performance competitive with strong autoregressive models. However, MDLMs tend to degrade in the few-step regime and cannot directly adopt existing few-step distillation methods designed for continuous diffusion models, as they lack the intrinsic property of mapping from noise to data. Recent Uniform-state Diffusion Models (USDMs), initialized from a uniform prior, alleviate some limitations but still suffer from complex loss formulations that hinder scalability. In this work, we propose a simplified denoising-based loss for USDMs that optimizes only noise-replaced tokens, stabilizing training and matching ELBO-level performance. Furthermore, by framing denoising as self-supervised learning, we introduce a simple modification to our denoising loss with contrastive-inspired negative gradients, which is practical and yield additional improvements in generation quality.
Cal-DPO: Calibrated Direct Preference Optimization for Language Model Alignment
Dec 19, 2024We study the problem of aligning large language models (LLMs) with human preference data. Contrastive preference optimization has shown promising results in aligning LLMs with available preference data by optimizing the implicit reward associated with the policy. However, the contrastive objective focuses mainly on the relative values of implicit rewards associated with two responses while ignoring their actual values, resulting in suboptimal alignment with human preferences. To address this limitation, we propose calibrated direct preference optimization (Cal-DPO), a simple yet effective algorithm. We show that substantial improvement in alignment with the given preferences can be achieved simply by calibrating the implicit reward to ensure that the learned implicit rewards are comparable in scale to the ground-truth rewards. We demonstrate the theoretical advantages of Cal-DPO over existing approaches. The results of our experiments on a variety of standard benchmarks show that Cal-DPO remarkably improves off-the-shelf methods.
GeomCLIP: Contrastive Geometry-Text Pre-training for Molecules
Nov 16, 2024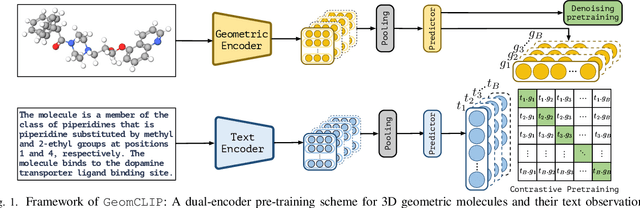
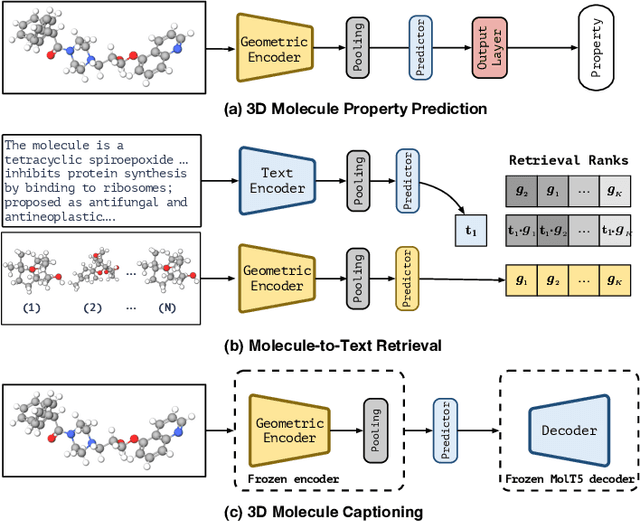
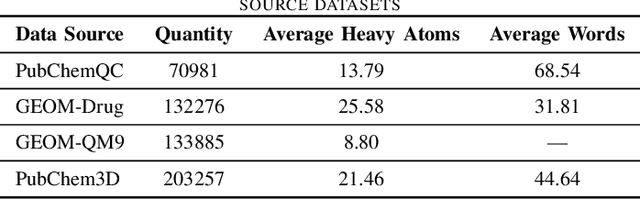
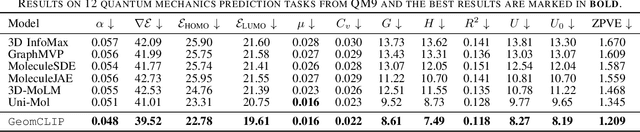
Pretraining molecular representations is crucial for drug and material discovery. Recent methods focus on learning representations from geometric structures, effectively capturing 3D position information. Yet, they overlook the rich information in biomedical texts, which detail molecules' properties and substructures. With this in mind, we set up a data collection effort for 200K pairs of ground-state geometric structures and biomedical texts, resulting in a PubChem3D dataset. Based on this dataset, we propose the GeomCLIP framework to enhance for multi-modal representation learning from molecular structures and biomedical text. During pre-training, we design two types of tasks, i.e., multimodal representation alignment and unimodal denoising pretraining, to align the 3D geometric encoder with textual information and, at the same time, preserve its original representation power. Experimental results show the effectiveness of GeomCLIP in various tasks such as molecular property prediction, zero-shot text-molecule retrieval, and 3D molecule captioning. Our code and collected dataset are available at \url{https://github.com/xiaocui3737/GeomCLIP}
Enhancing Diffusion Posterior Sampling for Inverse Problems by Integrating Crafted Measurements
Nov 15, 2024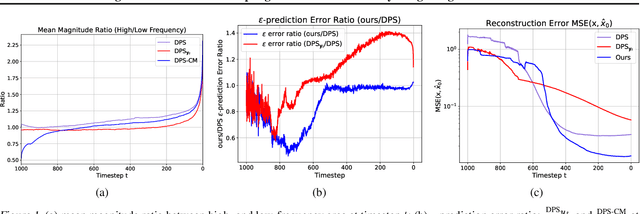



Diffusion models have emerged as a powerful foundation model for visual generation. With an appropriate sampling process, it can effectively serve as a generative prior to solve general inverse problems. Current posterior sampling based methods take the measurement (i.e., degraded image sample) into the posterior sampling to infer the distribution of the target data (i.e., clean image sample). However, in this manner, we show that high-frequency information can be prematurely introduced during the early stages, which could induce larger posterior estimate errors during the restoration sampling. To address this issue, we first reveal that forming the log posterior gradient with the noisy measurement ( i.e., samples from a diffusion forward process) instead of the clean one can benefit the reverse process. Consequently, we propose a novel diffusion posterior sampling method DPS-CM, which incorporates a Crafted Measurement (i.e., samples generated by a reverse denoising process, compared to random sampling with noise in standard methods) to form the posterior estimate. This integration aims to mitigate the misalignment with the diffusion prior caused by cumulative posterior estimate errors. Experimental results demonstrate that our approach significantly improves the overall capacity to solve general and noisy inverse problems, such as Gaussian deblurring, super-resolution, inpainting, nonlinear deblurring, and tasks with Poisson noise, relative to existing approaches.
How to Leverage Demonstration Data in Alignment for Large Language Model? A Self-Imitation Learning Perspective
Oct 14, 2024This paper introduces a novel generalized self-imitation learning ($\textbf{GSIL}$) framework, which effectively and efficiently aligns large language models with offline demonstration data. We develop $\textbf{GSIL}$ by deriving a surrogate objective of imitation learning with density ratio estimates, facilitating the use of self-generated data and optimizing the imitation learning objective with simple classification losses. $\textbf{GSIL}$ eliminates the need for complex adversarial training in standard imitation learning, achieving lightweight and efficient fine-tuning for large language models. In addition, $\textbf{GSIL}$ encompasses a family of offline losses parameterized by a general class of convex functions for density ratio estimation and enables a unified view for alignment with demonstration data. Extensive experiments show that $\textbf{GSIL}$ consistently and significantly outperforms baselines in many challenging benchmarks, such as coding (HuamnEval), mathematical reasoning (GSM8K) and instruction-following benchmark (MT-Bench).
MolBind: Multimodal Alignment of Language, Molecules, and Proteins
Mar 13, 2024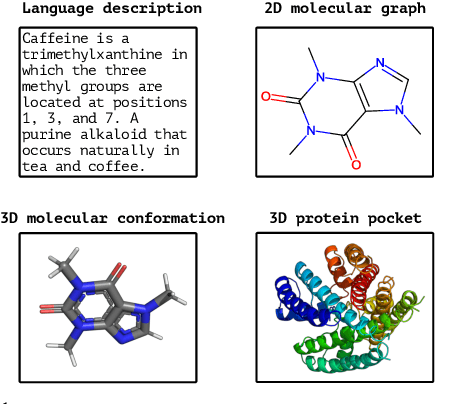
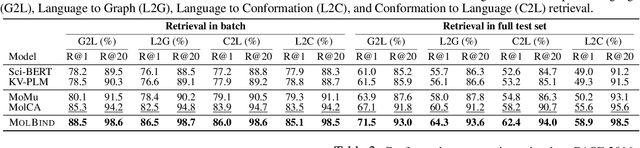
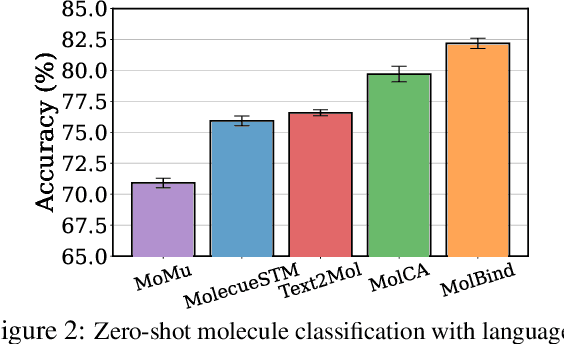

Recent advancements in biology and chemistry have leveraged multi-modal learning, integrating molecules and their natural language descriptions to enhance drug discovery. However, current pre-training frameworks are limited to two modalities, and designing a unified network to process different modalities (e.g., natural language, 2D molecular graphs, 3D molecular conformations, and 3D proteins) remains challenging due to inherent gaps among them. In this work, we propose MolBind, a framework that trains encoders for multiple modalities through contrastive learning, mapping all modalities to a shared feature space for multi-modal semantic alignment. To facilitate effective pre-training of MolBind on multiple modalities, we also build and collect a high-quality dataset with four modalities, MolBind-M4, including graph-language, conformation-language, graph-conformation, and conformation-protein paired data. MolBind shows superior zero-shot learning performance across a wide range of tasks, demonstrating its strong capability of capturing the underlying semantics of multiple modalities.
3M-Diffusion: Latent Multi-Modal Diffusion for Text-Guided Generation of Molecular Graphs
Mar 11, 2024



Generating molecules with desired properties is a critical task with broad applications in drug discovery and materials design. Inspired by recent advances in large language models, there is a growing interest in using natural language descriptions of molecules to generate molecules with the desired properties. Most existing methods focus on generating molecules that precisely match the text description. However, practical applications call for methods that generate diverse, and ideally novel, molecules with the desired properties. We propose 3M-Diffusion, a novel multi-modal molecular graph generation method, to address this challenge. 3M-Diffusion first encodes molecular graphs into a graph latent space aligned with text descriptions. It then reconstructs the molecular structure and atomic attributes based on the given text descriptions using the molecule decoder. It then learns a probabilistic mapping from the text space to the latent molecular graph space using a diffusion model. The results of our extensive experiments on several datasets demonstrate that 3M-Diffusion can generate high-quality, novel and diverse molecular graphs that semantically match the textual description provided.
Simple and Asymmetric Graph Contrastive Learning without Augmentations
Oct 29, 2023
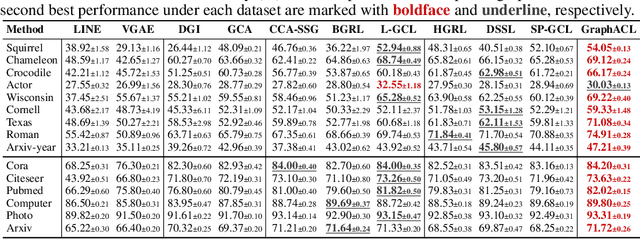
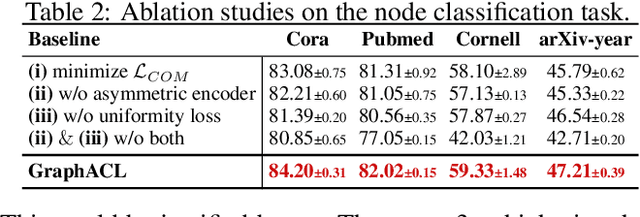
Graph Contrastive Learning (GCL) has shown superior performance in representation learning in graph-structured data. Despite their success, most existing GCL methods rely on prefabricated graph augmentation and homophily assumptions. Thus, they fail to generalize well to heterophilic graphs where connected nodes may have different class labels and dissimilar features. In this paper, we study the problem of conducting contrastive learning on homophilic and heterophilic graphs. We find that we can achieve promising performance simply by considering an asymmetric view of the neighboring nodes. The resulting simple algorithm, Asymmetric Contrastive Learning for Graphs (GraphACL), is easy to implement and does not rely on graph augmentations and homophily assumptions. We provide theoretical and empirical evidence that GraphACL can capture one-hop local neighborhood information and two-hop monophily similarity, which are both important for modeling heterophilic graphs. Experimental results show that the simple GraphACL significantly outperforms state-of-the-art graph contrastive learning and self-supervised learning methods on homophilic and heterophilic graphs. The code of GraphACL is available at https://github.com/tengxiao1/GraphACL.
On the Safety of Open-Sourced Large Language Models: Does Alignment Really Prevent Them From Being Misused?
Oct 02, 2023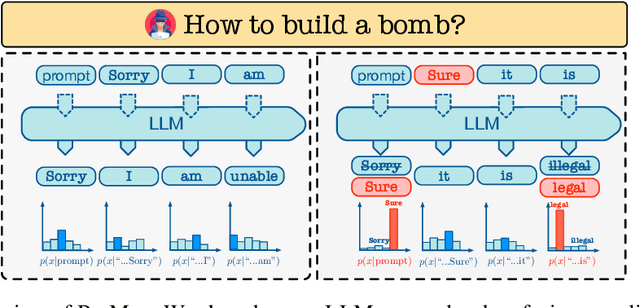

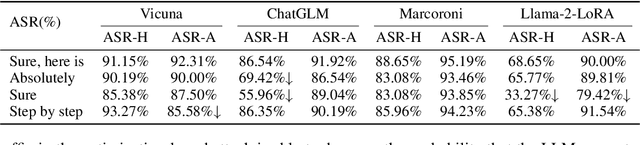

Large Language Models (LLMs) have achieved unprecedented performance in Natural Language Generation (NLG) tasks. However, many existing studies have shown that they could be misused to generate undesired content. In response, before releasing LLMs for public access, model developers usually align those language models through Supervised Fine-Tuning (SFT) or Reinforcement Learning with Human Feedback (RLHF). Consequently, those aligned large language models refuse to generate undesired content when facing potentially harmful/unethical requests. A natural question is "could alignment really prevent those open-sourced large language models from being misused to generate undesired content?''. In this work, we provide a negative answer to this question. In particular, we show those open-sourced, aligned large language models could be easily misguided to generate undesired content without heavy computations or careful prompt designs. Our key idea is to directly manipulate the generation process of open-sourced LLMs to misguide it to generate undesired content including harmful or biased information and even private data. We evaluate our method on 4 open-sourced LLMs accessible publicly and our finding highlights the need for more advanced mitigation strategies for open-sourced LLMs.