 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeomCLIP: Contrastive Geometry-Text Pre-training for Molecules
Paper and Code
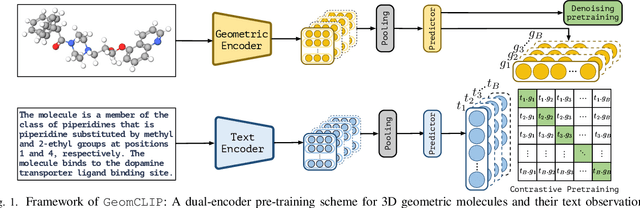
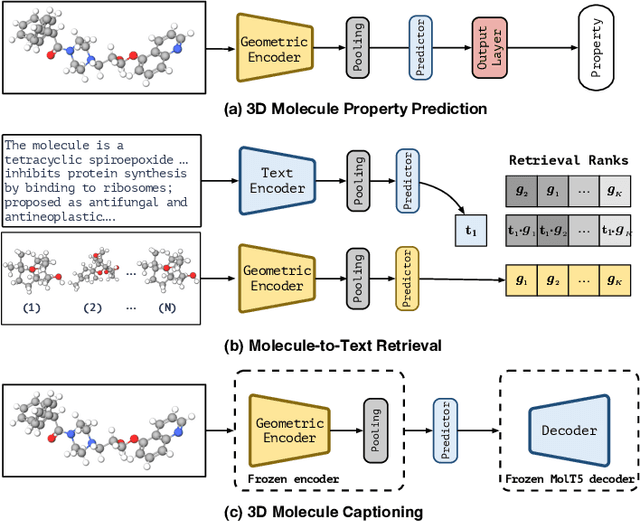
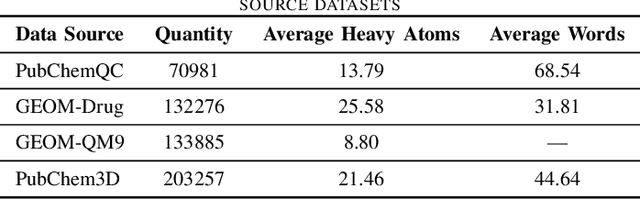
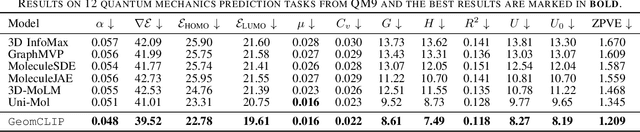
Pretraining molecular representations is crucial for drug and material discovery. Recent methods focus on learning representations from geometric structures, effectively capturing 3D position information. Yet, they overlook the rich information in biomedical texts, which detail molecules' properties and substructures. With this in mind, we set up a data collection effort for 200K pairs of ground-state geometric structures and biomedical texts, resulting in a PubChem3D dataset. Based on this dataset, we propose the GeomCLIP framework to enhance for multi-modal representation learning from molecular structures and biomedical text. During pre-training, we design two types of tasks, i.e., multimodal representation alignment and unimodal denoising pretraining, to align the 3D geometric encoder with textual information and, at the same time, preserve its original representation power. Experimental results show the effectiveness of GeomCLIP in various tasks such as molecular property prediction, zero-shot text-molecule retrieval, and 3D molecule captioning. Our code and collected dataset are available at \url{https://github.com/xiaocui3737/GeomCLIP}