 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolBind: Multimodal Alignment of Language, Molecules, and Proteins
Paper and Code
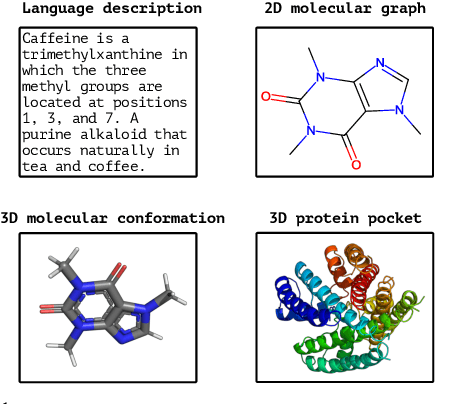
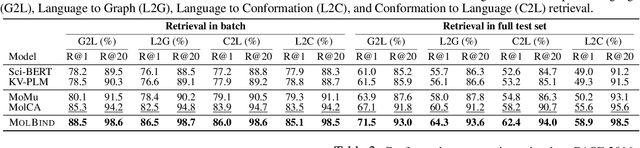
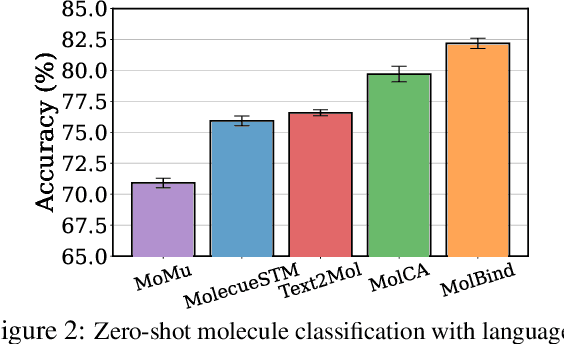

Recent advancements in biology and chemistry have leveraged multi-modal learning, integrating molecules and their natural language descriptions to enhance drug discovery. However, current pre-training frameworks are limited to two modalities, and designing a unified network to process different modalities (e.g., natural language, 2D molecular graphs, 3D molecular conformations, and 3D proteins) remains challenging due to inherent gaps among them. In this work, we propose MolBind, a framework that trains encoders for multiple modalities through contrastive learning, mapping all modalities to a shared feature space for multi-modal semantic alignment. To facilitate effective pre-training of MolBind on multiple modalities, we also build and collect a high-quality dataset with four modalities, MolBind-M4, including graph-language, conformation-language, graph-conformation, and conformation-protein paired data. MolBind shows superior zero-shot learning performance across a wide range of tasks, demonstrating its strong capability of capturing the underlying semantics of multiple modalities.