 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMCT: Segment Any CT Allowing Labor-Free Task-Indicator Prompts
Mar 20, 2024



Segment anything model (SAM), a foundation model with superior versatility and generalization across diverse segmentation tasks, has attracted widespread attention in medical imaging. However, it has been proved that SAM would encounter severe performance degradation due to the lack of medical knowledge in training and local feature encoding. Though several SAM-based models have been proposed for tuning SAM in medical imaging, they still suffer from insufficient feature extraction and highly rely on high-quality prompts. In this paper, we construct a large CT dataset consisting of 1.1M CT images and 5M masks from public datasets and propose a powerful foundation model SAMCT allowing labor-free prompts. Specifically, based on SAM, SAMCT is further equipped with a U-shaped CNN image encoder, a cross-branch interaction module, and a task-indicator prompt encoder. The U-shaped CNN image encoder works in parallel with the ViT image encoder in SAM to supplement local features. Cross-branch interaction enhances the feature expression capability of the CNN image encoder and the ViT image encoder by exchanging global perception and local features from one to the other. The task-indicator prompt encoder is a plug-and-play component to effortlessly encode task-related indicators into prompt embeddings. In this way, SAMCT can work in an automatic manner in addition to the semi-automatic interactive strategy in SAM. Extensive experiments demonstrate the superiority of SAMCT against the state-of-the-art task-specific and SAM-based medical foundation models on various tasks. The code, data, and models are released at https://github.com/xianlin7/SAMCT.
SAMUS: Adapting Segment Anything Model for Clinically-Friendly and Generalizable Ultrasound Image Segmentation
Sep 13, 2023Segment anything model (SAM), an eminent universal image segmentation model, has recently gathered considerable attention within the domain of medical image segmentation. Despite the remarkable performance of SAM on natural images, it grapples with significant performance degradation and limited generalization when confronted with medical images, particularly with those involving objects of low contrast, faint boundaries, intricate shapes, and diminutive sizes. In this paper, we propose SAMUS, a universal model tailored for ultrasound image segmentation. In contrast to previous SAM-based universal models, SAMUS pursues not only better generalization but also lower deployment cost, rendering it more suitable for clinical applications. Specifically, based on SAM, a parallel CNN branch is introduced to inject local features into the ViT encoder through cross-branch attention for better medical image segmentation. Then, a position adapter and a feature adapter are developed to adapt SAM from natural to medical domains and from requiring large-size inputs (1024x1024) to small-size inputs (256x256) for more clinical-friendly deployment. A comprehensive ultrasound dataset, comprising about 30k images and 69k masks and covering six object categories, is collected for verification. Extensive comparison experiments demonstrate SAMUS's superiority against the state-of-the-art task-specific models and universal foundation models under both task-specific evaluation and generalization evaluation. Moreover, SAMUS is deployable on entry-level GPUs, as it has been liberated from the constraints of long sequence encoding. The code, data, and models will be released at https://github.com/xianlin7/SAMUS.
ConvFormer: Plug-and-Play CNN-Style Transformers for Improving Medical Image Segmentation
Sep 09, 2023Transformers have been extensively studied in medical image segmentation to build pairwise long-range dependence. Yet, relatively limited well-annotated medical image data makes transformers struggle to extract diverse global features, resulting in attention collapse where attention maps become similar or even identical. Comparatively, convolutional neural networks (CNNs) have better convergence properties on small-scale training data but suffer from limited receptive fields. Existing works are dedicated to exploring the combinations of CNN and transformers while ignoring attention collapse, leaving the potential of transformers under-explored. In this paper, we propose to build CNN-style Transformers (ConvFormer) to promote better attention convergence and thus better segmentation performance. Specifically, ConvFormer consists of pooling, CNN-style self-attention (CSA), and convolutional feed-forward network (CFFN) corresponding to tokenization, self-attention, and feed-forward network in vanilla vision transformers. In contrast to positional embedding and tokenization, ConvFormer adopts 2D convolution and max-pooling for both position information preservation and feature size reduction. In this way, CSA takes 2D feature maps as inputs and establishes long-range dependency by constructing self-attention matrices as convolution kernels with adaptive sizes. Following CSA, 2D convolution is utilized for feature refinement through CFFN. Experimental results on multiple datasets demonstrate the effectiveness of ConvFormer working as a plug-and-play module for consistent performance improvement of transformer-based frameworks. Code is available at https://github.com/xianlin7/ConvFormer.
The Lighter The Better: Rethinking Transformers in Medical Image Segmentation Through Adaptive Pruning
Jun 29, 2022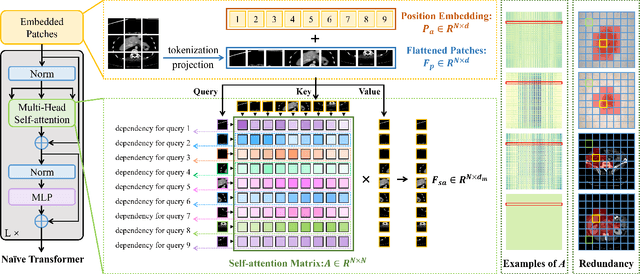


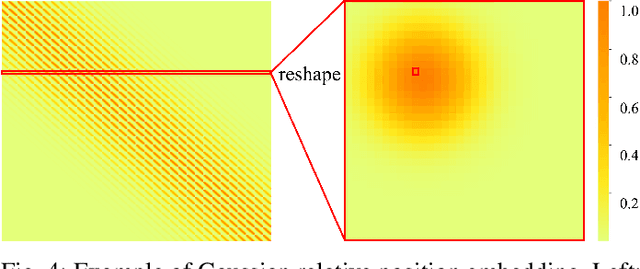
Vision transformers have recently set off a new wave in the field of medical image analysis due to their remarkable performance on various computer vision tasks. However, recent hybrid-/transformer-based approaches mainly focus on the benefits of transformers in capturing long-range dependency while ignoring the issues of their daunting computational complexity, high training costs, and redundant dependency. In this paper, we propose to employ adaptive pruning to transformers for medical image segmentation and propose a lightweight and effective hybrid network APFormer. To our best knowledge, this is the first work on transformer pruning for medical image analysis tasks. The key features of APFormer mainly are self-supervised self-attention (SSA) to improve the convergence of dependency establishment, Gaussian-prior relative position embedding (GRPE) to foster the learning of position information, and adaptive pruning to eliminate redundant computations and perception information. Specifically, SSA and GRPE consider the well-converged dependency distribution and the Gaussian heatmap distribution separately as the prior knowledge of self-attention and position embedding to ease the training of transformers and lay a solid foundation for the following pruning operation. Then, adaptive transformer pruning, both query-wise and dependency-wise, is performed by adjusting the gate control parameters for both complexity reduction and performance improvement. Extensive experiments on two widely-used datasets demonstrate the prominent segmentation performance of APFormer against the state-of-the-art methods with much fewer parameters and lower GFLOPs. More importantly, we prove, through ablation studies, that adaptive pruning can work as a plug-n-play module for performance improvement on other hybrid-/transformer-based methods. Code is available at https://github.com/xianlin7/APFormer.
C2FTrans: Coarse-to-Fine Transformers for Medical Image Segmentation
Jun 29, 2022
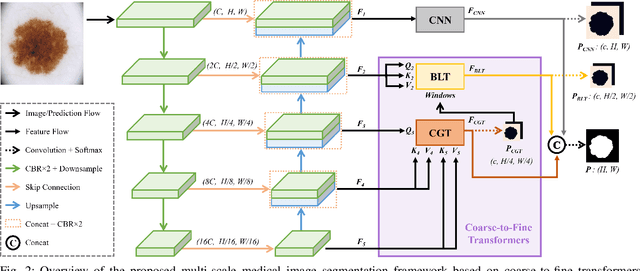
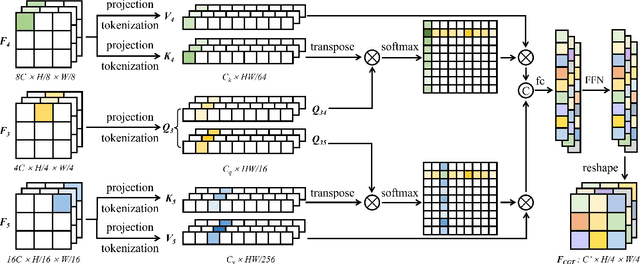
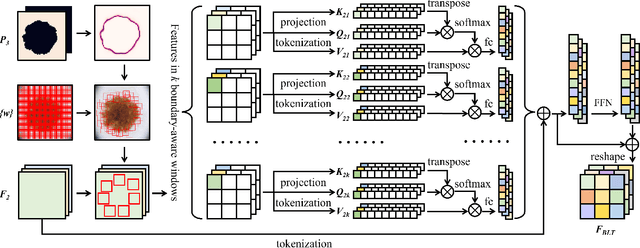
Convolutional neural networks (CNN), the most prevailing architecture for deep-learning based medical image analysis, are still functionally limited by their intrinsic inductive biases and inadequate receptive fields. Transformer, born to address this issue, has drawn explosive attention in natural language processing and computer vision due to its remarkable ability in capturing long-range dependency. However, most recent transformer-based methods for medical image segmentation directly apply vanilla transformers as an auxiliary module in CNN-based methods, resulting in severe detail loss due to the rigid patch partitioning scheme in transformers. To address this problem, we propose C2FTrans, a novel multi-scale architecture that formulates medical image segmentation as a coarse-to-fine procedure. C2FTrans mainly consists of a cross-scale global transformer (CGT) which addresses local contextual similarity in CNN and a boundary-aware local transformer (BLT) which overcomes boundary uncertainty brought by rigid patch partitioning in transformers. Specifically, CGT builds global dependency across three different small-scale feature maps to obtain rich global semantic features with an acceptable computational cost, while BLT captures mid-range dependency by adaptively generating windows around boundaries under the guidance of entropy to reduce computational complexity and minimize detail loss based on large-scale feature maps. Extensive experimental results on three public datasets demonstrate the superior performance of C2FTrans against state-of-the-art CNN-based and transformer-based methods with fewer parameters and lower FLOPs. We believe the design of C2FTrans would further inspire future work on developing efficient and lightweight transformers for medical image segmentation. The source code of this paper is publicly available at https://github.com/xianlin7/C2FTrans.