 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lighter The Better: Rethinking Transformers in Medical Image Segmentation Through Adaptive Pruning
Paper and Code
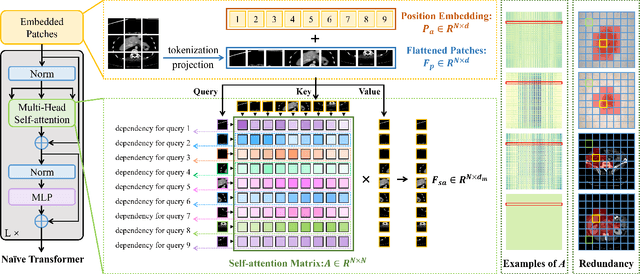


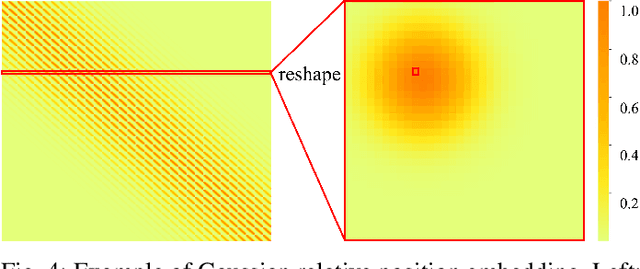
Vision transformers have recently set off a new wave in the field of medical image analysis due to their remarkable performance on various computer vision tasks. However, recent hybrid-/transformer-based approaches mainly focus on the benefits of transformers in capturing long-range dependency while ignoring the issues of their daunting computational complexity, high training costs, and redundant dependency. In this paper, we propose to employ adaptive pruning to transformers for medical image segmentation and propose a lightweight and effective hybrid network APFormer. To our best knowledge, this is the first work on transformer pruning for medical image analysis tasks. The key features of APFormer mainly are self-supervised self-attention (SSA) to improve the convergence of dependency establishment, Gaussian-prior relative position embedding (GRPE) to foster the learning of position information, and adaptive pruning to eliminate redundant computations and perception information. Specifically, SSA and GRPE consider the well-converged dependency distribution and the Gaussian heatmap distribution separately as the prior knowledge of self-attention and position embedding to ease the training of transformers and lay a solid foundation for the following pruning operation. Then, adaptive transformer pruning, both query-wise and dependency-wise, is performed by adjusting the gate control parameters for both complexity reduction and performance improvement. Extensive experiments on two widely-used datasets demonstrate the prominent segmentation performance of APFormer against the state-of-the-art methods with much fewer parameters and lower GFLOPs. More importantly, we prove, through ablation studies, that adaptive pruning can work as a plug-n-play module for performance improvement on other hybrid-/transformer-based methods. Code is available at https://github.com/xianlin7/APFormer.