 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stream Interactive Joint Learning of Scene Parsing and Geometric Vision Tasks
Feb 14, 2026Inspired by the human visual system, which operates on two parallel yet interactive streams for contextual and spatial understanding, this article presents Two Interactive Streams (TwInS), a novel bio-inspired joint learning framework capable of simultaneously performing scene parsing and geometric vision tasks. TwInS adopts a unified, general-purpose architecture in which multi-level contextual features from the scene parsing stream are infused into the geometric vision stream to guide its iterative refinement. In the reverse direction, decoded geometric features are projected into the contextual feature space for selective heterogeneous feature fusion via a novel cross-task adapter, which leverages rich cross-view geometric cues to enhance scene parsing. To eliminate the dependence on costly human-annotated correspondence ground truth, TwInS is further equipped with a tailored semi-supervised training strategy, which unleashes the potential of large-scale multi-view data and enables continuous self-evolution without requiring ground-truth correspondences. Extensive experiments conducted on three public datasets validate the effectiveness of TwInS's core components and demonstrate its superior performance over existing state-of-the-art approaches. The source code will be made publicly available upon publication.
TiCoSS: Tightening the Coupling between Semantic Segmentation and Stereo Matching within A Joint Learning Framework
Jul 25, 2024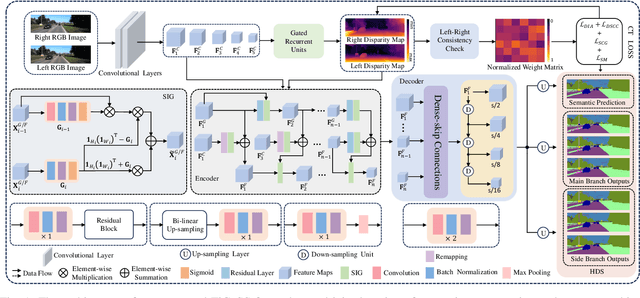



Semantic segmentation and stereo matching, respectively analogous to the ventral and dorsal streams in our human brain, are two key components of autonomous driving perception systems. Addressing these two tasks with separate networks is no longer the mainstream direction in developing computer vision algorithms, particularly with the recent advances in large vision models and embodied artificial intelligence. The trend is shifting towards combining them within a joint learning framework, especially emphasizing feature sharing between the two tasks. The major contributions of this study lie in comprehensively tightening the coupling between semantic segmentation and stereo matching. Specifically, this study introduces three novelties: (1) a tightly coupled, gated feature fusion strategy, (2) a hierarchical deep supervision strategy, and (3) a coupling tightening loss function. The combined use of these technical contributions results in TiCoSS, a state-of-the-art joint learning framework that simultaneously tackles semantic segmentation and stereo matching. Through extensive experiments on the KITTI and vKITTI2 datasets, along with qualitative and quantitative analyses, we validate the effectiveness of our developed strategies and loss function, and demonstrate its superior performance compared to prior arts, with a notable increase in mIoU by over 9%. Our source code will be publicly available at mias.group/TiCoSS upon publication.