 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPose: Category-Level Object Pose Estimation with Pre-trained Vision-Language Knowledge
Feb 24, 2024



Most of existing category-level object pose estimation methods devote to learning the object category information from point cloud modality. However, the scale of 3D datasets is limited due to the high cost of 3D data collection and annotation. Consequently, the category features extracted from these limited point cloud samples may not be comprehensive. This motivates us to investigate whether we can draw on knowledge of other modalities to obtain category information. Inspired by this motivation, we propose CLIPose, a novel 6D pose framework that employs the pre-trained vision-language model to develop better learning of object category information, which can fully leverage abundant semantic knowledge in image and text modalities. To make the 3D encoder learn category-specific features more efficiently, we align representations of three modalities in feature space via multi-modal contrastive learning. In addition to exploiting the pre-trained knowledge of the CLIP's model, we also expect it to be more sensitive with pose parameters. Therefore, we introduce a prompt tuning approach to fine-tune image encoder while we incorporate rotations and translations information in the text descriptions. CLIPose achieves state-of-the-art performance on two mainstream benchmark datasets, REAL275 and CAMERA25, and runs in real-time during inference (40FPS).
TransPose: 6D Object Pose Estimation with Geometry-Aware Transformer
Oct 25, 2023



Estimating the 6D object pose is an essential task in many applications. Due to the lack of depth information, existing RGB-based methods are sensitive to occlusion and illumination changes. How to extract and utilize the geometry features in depth information is crucial to achieve accurate predictions. To this end, we propose TransPose, a novel 6D pose framework that exploits Transformer Encoder with geometry-aware module to develop better learning of point cloud feature representations. Specifically, we first uniformly sample point cloud and extract local geometry features with the designed local feature extractor base on graph convolution network. To improve robustness to occlusion, we adopt Transformer to perform the exchange of global information, making each local feature contains global information. Finally, we introduce geometry-aware module in Transformer Encoder, which to form an effective constrain for point cloud feature learning and makes the global information exchange more tightly coupled with point cloud tasks. Extensive experiments indicate the effectiveness of TransPose, our pose estimation pipeline achieves competitive results on three benchmark datasets.
RoadFormer: Duplex Transformer for RGB-Normal Semantic Road Scene Parsing
Sep 19, 2023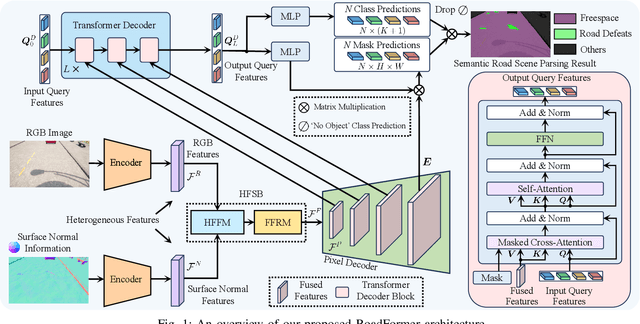
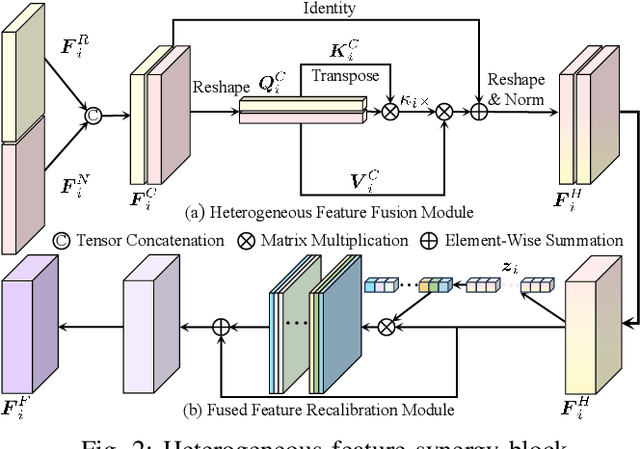
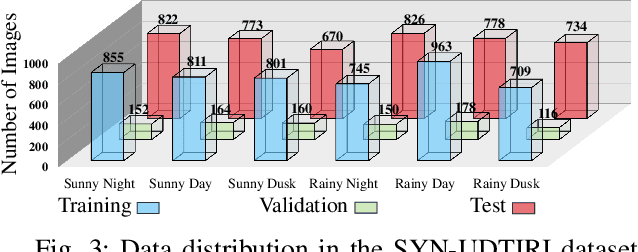

The recent advancements in deep convolutional neural networks have shown significant promise in the domain of road scene parsing. Nevertheless, the existing works focus primarily on freespace detection, with little attention given to hazardous road defects that could compromise both driving safety and comfort. In this paper, we introduce RoadFormer, a novel Transformer-based data-fusion network developed for road scene parsing. RoadFormer utilizes a duplex encoder architecture to extract heterogeneous features from both RGB images and surface normal information. The encoded features are subsequently fed into a novel heterogeneous feature synergy block for effective feature fusion and recalibration. The pixel decoder then learns multi-scale long-range dependencies from the fused and recalibrated heterogeneous features, which are subsequently processed by a Transformer decoder to produce the final semantic prediction. Additionally, we release SYN-UDTIRI, the first large-scale road scene parsing dataset that contains over 10,407 RGB images, dense depth images, and the corresponding pixel-level annotations for both freespace and road defects of different shapes and sizes. Extensive experimental evaluations conducted on our SYN-UDTIRI dataset, as well as on three public datasets, including KITTI road, CityScapes, and ORFD, demonstrate that RoadFormer outperforms all other state-of-the-art networks for road scene parsing. Specifically, RoadFormer ranks first on the KITTI road benchmark. Our source code, created dataset, and demo video are publicly available at mias.group/RoadFormer.