 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionUnite: A Vision-Language Foundation Model for Ophthalmology Enhanced with Clinical Knowledge
Aug 05, 2024



The need for improved diagnostic methods in ophthalmology is acute, especially in the less developed regions with limited access to specialists and advanced equipment. Therefore, we introduce VisionUnite, a novel vision-language foundation model for ophthalmology enhanced with clinical knowledge. VisionUnite has been pretrained on an extensive dataset comprising 1.24 million image-text pairs, and further refined using our proposed MMFundus dataset, which includes 296,379 high-quality fundus image-text pairs and 889,137 simulated doctor-patient dialogue instances. Our experiments indicate that VisionUnite outperforms existing generative foundation models such as GPT-4V and Gemini Pro. It also demonstrates diagnostic capabilities comparable to junior ophthalmologists. VisionUnite performs well in various clinical scenarios including open-ended multi-disease diagnosis, clinical explanation, and patient interaction, making it a highly versatile tool for initial ophthalmic disease screening. VisionUnite can also serve as an educational aid for junior ophthalmologists, accelerating their acquisition of knowledge regarding both common and rare ophthalmic conditions. VisionUnite represents a significant advancement in ophthalmology, with broad implications for diagnostics, medical education, and understanding of disease mechanisms.
Three-Filters-to-Normal+: Revisiting Discontinuity Discrimination in Depth-to-Normal Translation
Dec 13, 2023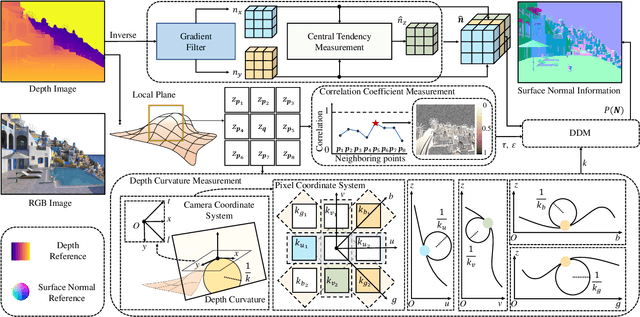
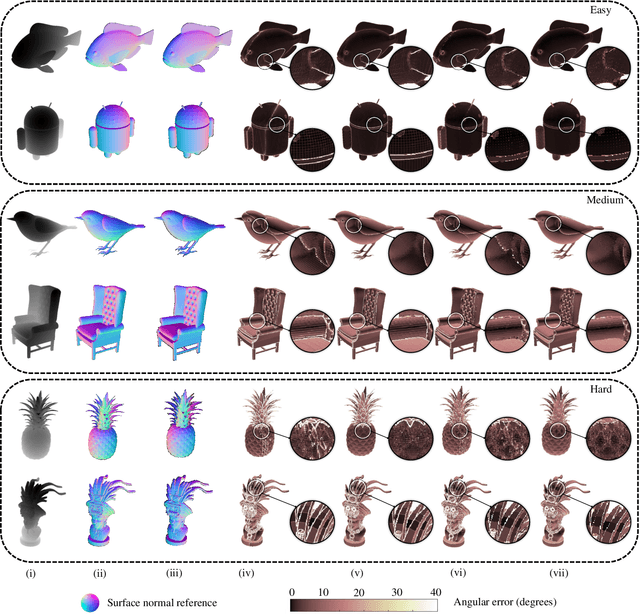
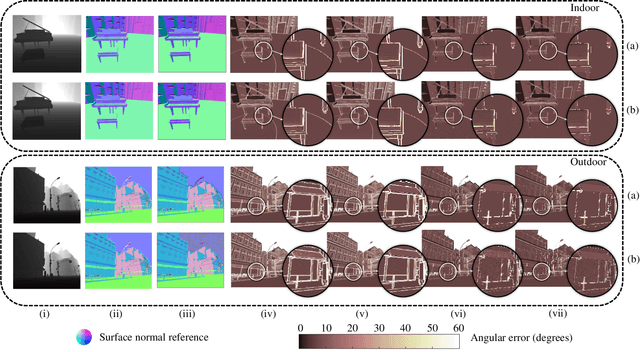
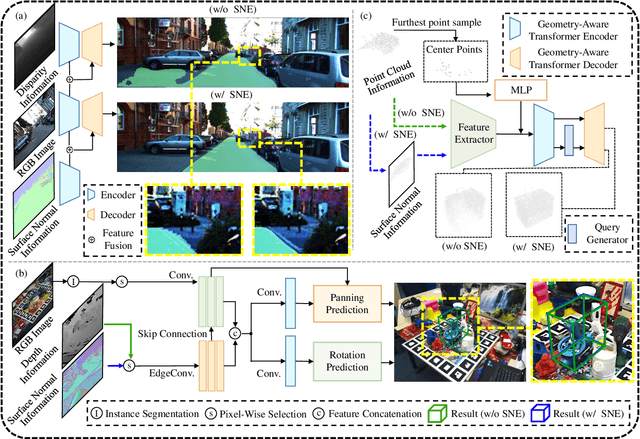
This article introduces three-filters-to-normal+ (3F2N+), an extension of our previous work three-filters-to-normal (3F2N), with a specific focus on incorporating discontinuity discrimination capability into surface normal estimators (SNEs). 3F2N+ achieves this capability by utilizing a novel discontinuity discrimination module (DDM), which combines depth curvature minimization and correlation coefficient maximization through conditional random fields (CRFs). To evaluate the robustness of SNEs on noisy data, we create a large-scale synthetic surface normal (SSN) dataset containing 20 scenarios (ten indoor scenarios and ten outdoor scenarios with and without random Gaussian noise added to depth images). Extensive experiments demonstrate that 3F2N+ achieves greater performance than all other geometry-based surface normal estimators, with average angular errors of 7.85$^\circ$, 8.95$^\circ$, 9.25$^\circ$, and 11.98$^\circ$ on the clean-indoor, clean-outdoor, noisy-indoor, and noisy-outdoor datasets, respectively. We conduct three additional experiments to demonstrate the effectiveness of incorporating our proposed 3F2N+ into downstream robot perception tasks, including freespace detection, 6D object pose estimation, and point cloud completion. Our source code and datasets are publicly available at https://mias.group/3F2Nplus.
TransPose: 6D Object Pose Estimation with Geometry-Aware Transformer
Oct 25, 2023



Estimating the 6D object pose is an essential task in many applications. Due to the lack of depth information, existing RGB-based methods are sensitive to occlusion and illumination changes. How to extract and utilize the geometry features in depth information is crucial to achieve accurate predictions. To this end, we propose TransPose, a novel 6D pose framework that exploits Transformer Encoder with geometry-aware module to develop better learning of point cloud feature representations. Specifically, we first uniformly sample point cloud and extract local geometry features with the designed local feature extractor base on graph convolution network. To improve robustness to occlusion, we adopt Transformer to perform the exchange of global information, making each local feature contains global information. Finally, we introduce geometry-aware module in Transformer Encoder, which to form an effective constrain for point cloud feature learning and makes the global information exchange more tightly coupled with point cloud tasks. Extensive experiments indicate the effectiveness of TransPose, our pose estimation pipeline achieves competitive results on three benchmark datasets.