 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Personality Control and Adaptation for LLM Agents
Jan 15, 2026Large Language Models (LLMs) are increasingly shaping human-computer interaction (HCI), from personalized assistants to social simulations. Beyond language competence, researchers are exploring whether LLMs can exhibit human-like characteristics that influence engagement, decision-making, and perceived realism. Personality, in particular, is critical, yet existing approaches often struggle to achieve both nuanced and adaptable expression. We present a framework that models LLM personality via Jungian psychological types, integrating three mechanisms: a dominant-auxiliary coordination mechanism for coherent core expression, a reinforcement-compensation mechanism for temporary adaptation to context, and a reflection mechanism that drives long-term personality evolution. This design allows the agent to maintain nuanced traits while dynamically adjusting to interaction demands and gradually updating its underlying structure. Personality alignment is evaluated using Myers-Briggs Type Indicator questionnaires and tested under diverse challenge scenarios as a preliminary structured assessment. Findings suggest that evolving, personality-aware LLMs can support coherent, context-sensitive interactions, enabling naturalistic agent design in HCI.
Multi-Layered Safety of Redundant Robot Manipulators via Task-Oriented Planning and Control
Oct 23, 2024Ensuring safety is crucial to promote the application of robot manipulators in open workspace. Factors such as sensor errors or unpredictable collisions make the environment full of uncertainties. In this work, we investigate these potential safety challenges on redundant robot manipulators, and propose a task-oriented planning and control framework to achieve multi-layered safety while maintaining efficient task execution. Our approach consists of two main parts: a task-oriented trajectory planner based on multiple-shooting model predictive control method, and a torque controller that allows safe and efficient collision reaction using only proprioceptive data. Through extensive simulations and real-hardware experiments, we demonstrate that the proposed framework can effectively handle uncertain static or dynamic obstacles, and perform disturbance resistance in manipulation tasks when unforeseen contacts occur. All code will be open-sourced to benefit the community.
A Novel Dual-pooling Attention Module for UAV Vehicle Re-identification
Jun 25, 2023Vehicle re-identification (Re-ID) involves identifying the same vehicle captured by other cameras, given a vehicle image. It plays a crucial role in the development of safe cities and smart cities. With the rapid growth and implementation of unmanned aerial vehicles (UAVs) technology, vehicle Re-ID in UAV aerial photography scenes has garnered significant attention from researchers. However, due to the high altitude of UAVs, the shooting angle of vehicle images sometimes approximates vertical, resulting in fewer local features for Re-ID. Therefore, this paper proposes a novel dual-pooling attention (DpA) module, which achieves the extraction and enhancement of locally important information about vehicles from both channel and spatial dimensions by constructing two branches of channel-pooling attention (CpA) and spatial-pooling attention (SpA), and employing multiple pooling operations to enhance the attention to fine-grained information of vehicles. Specifically, the CpA module operates between the channels of the feature map and splices features by combining four pooling operations so that vehicle regions containing discriminative information are given greater attention. The SpA module uses the same pooling operations strategy to identify discriminative representations and merge vehicle features in image regions in a weighted manner. The feature information of both dimensions is finally fused and trained jointly using label smoothing cross-entropy loss and hard mining triplet loss, thus solving the problem of missing detail information due to the high height of UAV shots. The proposed method's effectiveness is demonstrated through extensive experiments on the UAV-based vehicle datasets VeRi-UAV and VRU.
Motion Control based on Disturbance Estimation and Time-Varying Gain for Robotic Manipulators
Jun 05, 2023To achieve high-accuracy manipulation in the presence of unknown dynamics and external disturbance, we propose an efficient and robust motion controller (named TvUDE) for robotic manipulators. The controller incorporates a disturbance estimation mechanism that utilizes reformulated robot dynamics and filtering operations to obtain uncertainty and disturbance without requiring measurement of acceleration. Furthermore, we design a time-varying control input gain to enhance the control system's robustness. Finally, we analyze the boundness of the control signal and the stability of the closed-loop system, and conduct a set of experiments on a six-DOF robotic manipulator. The experimental results verify the effectiveness of TvUDE in handling internal uncertainty and external static or transient disturbance.
RetVec: Resilient and Efficient Text Vectorizer
Feb 18, 2023This paper describes RetVec, a resilient multilingual embedding scheme designed for neural-based text processing, including small-text classification and large-language models. RetVec combines a novel character encoding with an optional small model to embed words into a 256-dimensional vector space. These embeddings enable training competitive multilingual text models resilient to typos and adversarial attacks. In this paper, we evaluate and compare RetVec to state-of-the-art tokenizers and word embeddings on common model architectures. These comparisons demonstrate that RetVec leads to competitive models that are significantly more resilient to text perturbations across a variety of common tasks. RetVec is available under Apache 2 license at \url{https://github.com/[anonymized]}.
BCI: Breast Cancer Immunohistochemical Image Generation through Pyramid Pix2pix
Apr 25, 2022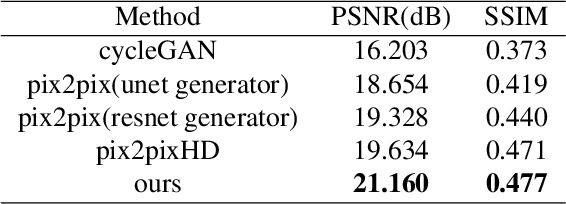
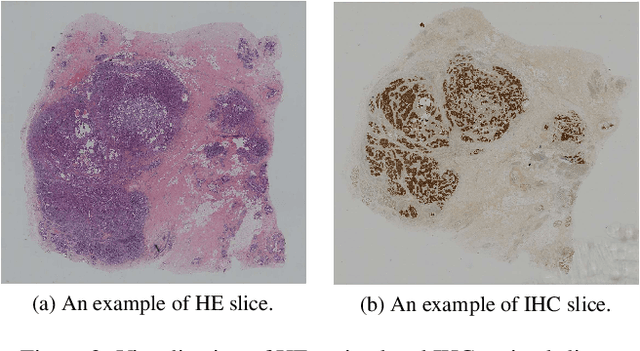
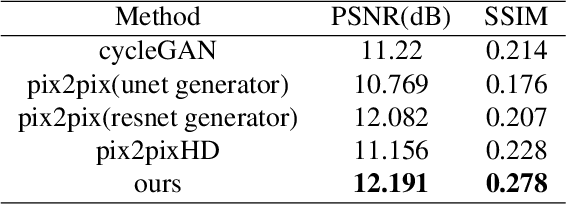
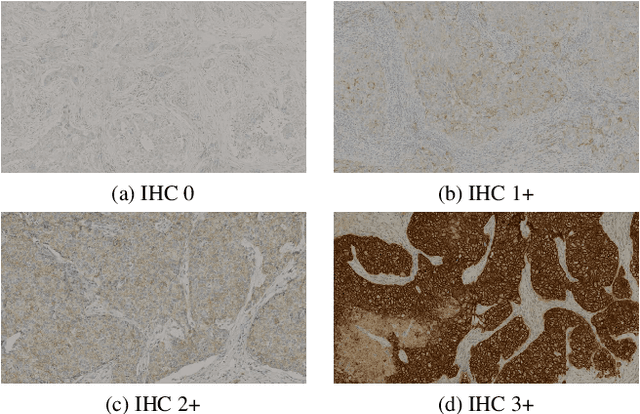
The evaluation of human epidermal growth factor receptor 2 (HER2) expression is essential to formulate a precise treatment for breast cancer. The routine evaluation of HER2 is conducted with immunohistochemical techniques (IHC), which is very expensive. Therefore, for the first time, we propose a breast cancer immunohistochemical (BCI) benchmark attempting to synthesize IHC data directly with the paired hematoxylin and eosin (HE) stained images. The dataset contains 4870 registered image pairs, covering a variety of HER2 expression levels. Based on BCI, as a minor contribution, we further build a pyramid pix2pix image generation method, which achieves better HE to IHC translation results than the other current popular algorithms. Extensive experiments demonstrate that BCI poses new challenges to the existing image translation research. Besides, BCI also opens the door for future pathology studies in HER2 expression evaluation based on the synthesized IHC images. BCI dataset can be downloaded from https://bupt-ai-cz.github.io/BCI.
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
Aug 24, 2021
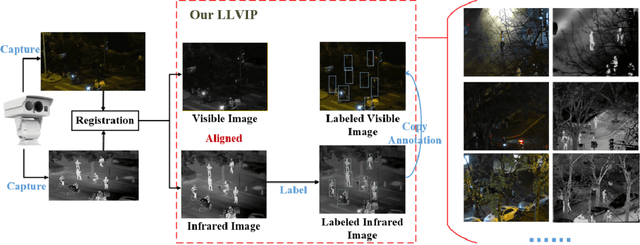
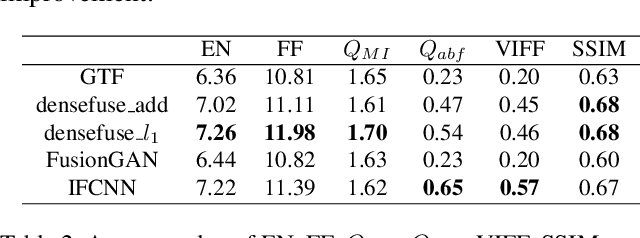

It is very challenging for various visual tasks such as image fusion, pedestrian detection and image-to-image translation in low light conditions due to the loss of effective target areas. In this case, infrared and visible images can be used together to provide both rich detail information and effective target areas. In this paper, we present LLVIP, a visible-infrared paired dataset for low-light vision. This dataset contains 33672 images, or 16836 pairs, most of which were taken at very dark scenes, and all of the images are strictly aligned in time and space. Pedestrians in the dataset are labeled. We compare the dataset with other visible-infrared datasets and evaluate the performance of some popular visual algorithms including image fusion, pedestrian detection and image-to-image translation on the dataset. The experimental results demonstrate the complementary effect of fusion on image information, and find the deficiency of existing algorithms of the three visual tasks in very low-light conditions. We believe the LLVIP dataset will contribute to the community of computer vision by promoting image fusion, pedestrian detection and image-to-image translation in very low-light applications. The dataset is being released in https://bupt-ai-cz.github.io/LLVIP.