 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Low-Frequency Bias: Feature Recalibration and Frequency Attention Regularization for Adversarial Robustness
Jul 04, 2024


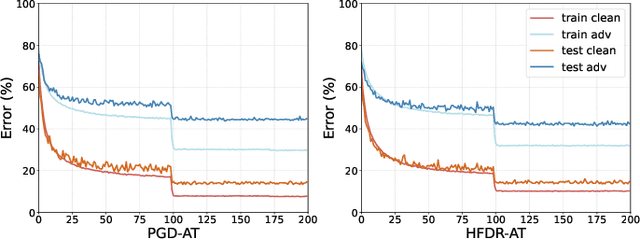
Ensuring the robustness of computer vision models against adversarial attacks is a significant and long-lasting objective. Motivated by adversarial attacks, researchers have devoted considerable efforts to enhancing model robustness by adversarial training (AT). However, we observe that while AT improves the models' robustness against adversarial perturbations, it fails to improve their ability to effectively extract features across all frequency components. Each frequency component contains distinct types of crucial information: low-frequency features provide fundamental structural insights, while high-frequency features capture intricate details and textures. In particular, AT tends to neglect the reliance on susceptible high-frequency features. This low-frequency bias impedes the model's ability to effectively leverage the potentially meaningful semantic information present in high-frequency features. This paper proposes a novel module called High-Frequency Feature Disentanglement and Recalibration (HFDR), which separates features into high-frequency and low-frequency components and recalibrates the high-frequency feature to capture latent useful semantics. Additionally, we introduce frequency attention regularization to magnitude the model's extraction of different frequency features and mitigate low-frequency bias during AT. Extensive experiments showcase the immense potential and superiority of our approach in resisting various white-box attacks, transfer attacks, and showcasing strong generalization capabilities.
A Multi-Stage Goal-Driven Network for Pedestrian Trajectory Prediction
Jun 26, 2024



Pedestrian trajectory prediction plays a pivotal role in ensuring the safety and efficiency of various applications, including autonomous vehicles and traffic management systems. This paper proposes a novel method for pedestrian trajectory prediction, called multi-stage goal-driven network (MGNet). Diverging from prior approaches relying on stepwise recursive prediction and the singular forecasting of a long-term goal, MGNet directs trajectory generation by forecasting intermediate stage goals, thereby reducing prediction errors. The network comprises three main components: a conditional variational autoencoder (CVAE), an attention module, and a multi-stage goal evaluator. Trajectories are encoded using conditional variational autoencoders to acquire knowledge about the approximate distribution of pedestrians' future trajectories, and combined with an attention mechanism to capture the temporal dependency between trajectory sequences. The pivotal module is the multi-stage goal evaluator, which utilizes the encoded feature vectors to predict intermediate goals, effectively minimizing cumulative errors in the recursive inference process. The effectiveness of MGNet is demonstrated through comprehensive experiments on the JAAD and PIE datasets. Comparative evaluations against state-of-the-art algorithms reveal significant performance improvements achieved by our proposed method.
Semi-Supervised Medical Image Segmentation with Co-Distribution Alignment
Jul 24, 2023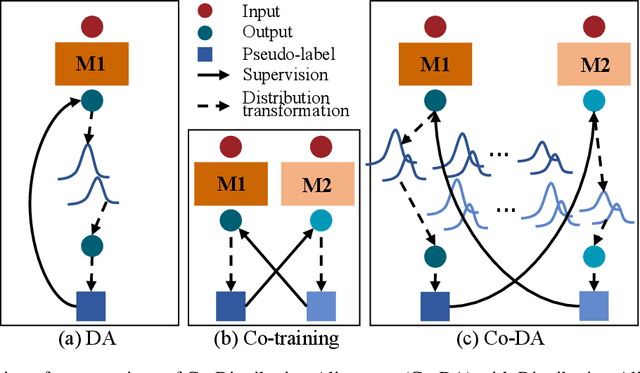
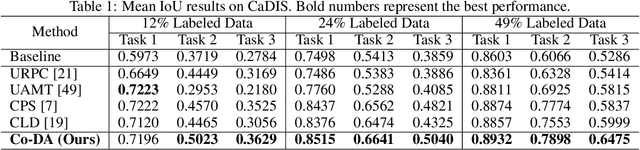
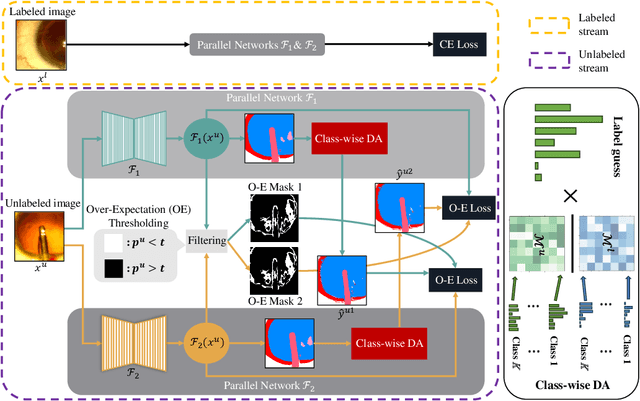

Medical image segmentation has made significant progress when a large amount of labeled data are available. However, annotating medical image segmentation datasets is expensive due to the requirement of professional skills. Additionally, classes are often unevenly distributed in medical images, which severely affects the classification performance on minority classes. To address these problems, this paper proposes Co-Distribution Alignment (Co-DA) for semi-supervised medical image segmentation. Specifically, Co-DA aligns marginal predictions on unlabeled data to marginal predictions on labeled data in a class-wise manner with two differently initialized models before using the pseudo-labels generated by one model to supervise the other. Besides, we design an over-expectation cross-entropy loss for filtering the unlabeled pixels to reduce noise in their pseudo-labels. Quantitative and qualitative experiments on three public datasets demonstrate that the proposed approach outperforms existing state-of-the-art semi-supervised medical image segmentation methods on both the 2D CaDIS dataset and the 3D LGE-MRI and ACDC datasets, achieving an mIoU of 0.8515 with only 24% labeled data on CaDIS, and a Dice score of 0.8824 and 0.8773 with only 20% data on LGE-MRI and ACDC, respectively.
A Multi-Scale Framework for Out-of-Distribution Detection in Dermoscopic Images
Jan 18, 2023The automatic detection of skin diseases via dermoscopic images can improve the efficiency in diagnosis and help doctors make more accurate judgments. However, conventional skin disease recognition systems may produce high confidence for out-of-distribution (OOD) data, which may become a major security vulnerability in practical applications. In this paper, we propose a multi-scale detection framework to detect out-of-distribution skin disease image data to ensure the robustness of the system. Our framework extracts features from different layers of the neural network. In the early layers, rectified activation is used to make the output features closer to the well-behaved distribution, and then an one-class SVM is trained to detect OOD data; in the penultimate layer, an adapted Gram matrix is used to calculate the features after rectified activation, and finally the layer with the best performance is chosen to compute a normality score. Experiments show that the proposed framework achieves superior performance when compared with other state-of-the-art methods in the task of skin disease recognition.
Joint Noise-Tolerant Learning and Meta Camera Shift Adaptation for Unsupervised Person Re-Identification
Mar 08, 2021
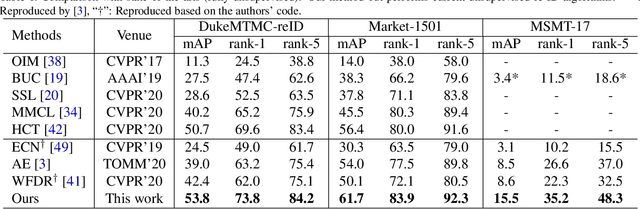

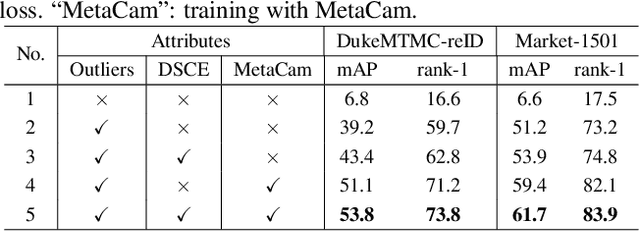
This paper considers the problem of unsupervised person re-identification (re-ID), which aims to learn discriminative models with unlabeled data. One popular method is to obtain pseudo-label by clustering and use them to optimize the model. Although this kind of approach has shown promising accuracy, it is hampered by 1) noisy labels produced by clustering and 2) feature variations caused by camera shift. The former will lead to incorrect optimization and thus hinders the model accuracy. The latter will result in assigning the intra-class samples of different cameras to different pseudo-label, making the model sensitive to camera variations. In this paper, we propose a unified framework to solve both problems. Concretely, we propose a Dynamic and Symmetric Cross-Entropy loss (DSCE) to deal with noisy samples and a camera-aware meta-learning algorithm (MetaCam) to adapt camera shift. DSCE can alleviate the negative effects of noisy samples and accommodate the change of clusters after each clustering step. MetaCam simulates cross-camera constraint by splitting the training data into meta-train and meta-test based on camera IDs. With the interacted gradient from meta-train and meta-test, the model is enforced to learn camera-invariant features. Extensive experiments on three re-ID benchmarks show the effectiveness and the complementary of the proposed DSCE and MetaCam. Our method outperforms the state-of-the-art methods on both fully unsupervised re-ID and unsupervised domain adaptive re-ID.
A Multi-Level Approach to Waste Object Segmentation
Jul 08, 2020

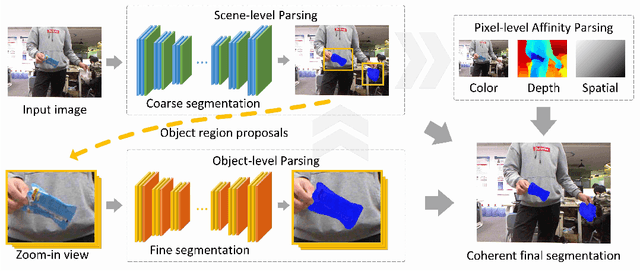
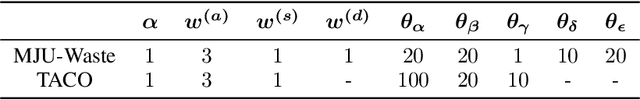
We address the problem of localizing waste objects from a color image and an optional depth image, which is a key perception component for robotic interaction with such objects. Specifically, our method integrates the intensity and depth information at multiple levels of spatial granularity. Firstly, a scene-level deep network produces an initial coarse segmentation, based on which we select a few potential object regions to zoom in and perform fine segmentation. The results of the above steps are further integrated into a densely connected conditional random field that learns to respect the appearance, depth, and spatial affinities with pixel-level accuracy. In addition, we create a new RGBD waste object segmentation dataset, MJU-Waste, that is made public to facilitate future research in this area. The efficacy of our method is validated on both MJU-Waste and the Trash Annotation in Context (TACO) dataset.
Learning a Layout Transfer Network for Context Aware Object Detection
Dec 09, 2019



We present a context aware object detection method based on a retrieve-and-transform scene layout model. Given an input image, our approach first retrieves a coarse scene layout from a codebook of typical layout templates. In order to handle large layout variations, we use a variant of the spatial transformer network to transform and refine the retrieved layout, resulting in a set of interpretable and semantically meaningful feature maps of object locations and scales. The above steps are implemented as a Layout Transfer Network which we integrate into Faster RCNN to allow for joint reasoning of object detection and scene layout estimation. Extensive experiments on three public datasets verified that our approach provides consistent performance improvements to the state-of-the-art object detection baselines on a variety of challenging tasks in the traffic surveillance and the autonomous driving domains.