 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Stage Goal-Driven Network for Pedestrian Trajectory Prediction
Jun 26, 2024



Pedestrian trajectory prediction plays a pivotal role in ensuring the safety and efficiency of various applications, including autonomous vehicles and traffic management systems. This paper proposes a novel method for pedestrian trajectory prediction, called multi-stage goal-driven network (MGNet). Diverging from prior approaches relying on stepwise recursive prediction and the singular forecasting of a long-term goal, MGNet directs trajectory generation by forecasting intermediate stage goals, thereby reducing prediction errors. The network comprises three main components: a conditional variational autoencoder (CVAE), an attention module, and a multi-stage goal evaluator. Trajectories are encoded using conditional variational autoencoders to acquire knowledge about the approximate distribution of pedestrians' future trajectories, and combined with an attention mechanism to capture the temporal dependency between trajectory sequences. The pivotal module is the multi-stage goal evaluator, which utilizes the encoded feature vectors to predict intermediate goals, effectively minimizing cumulative errors in the recursive inference process. The effectiveness of MGNet is demonstrated through comprehensive experiments on the JAAD and PIE datasets. Comparative evaluations against state-of-the-art algorithms reveal significant performance improvements achieved by our proposed method.
Long-length Legal Document Classification
Dec 14, 2019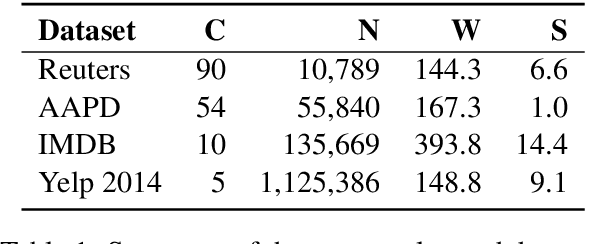
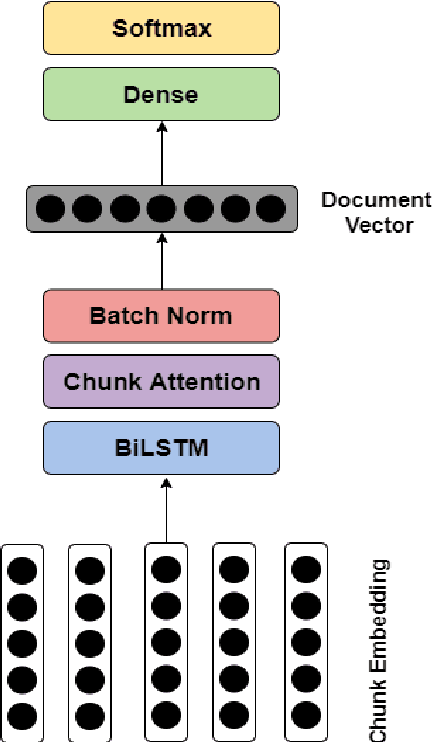
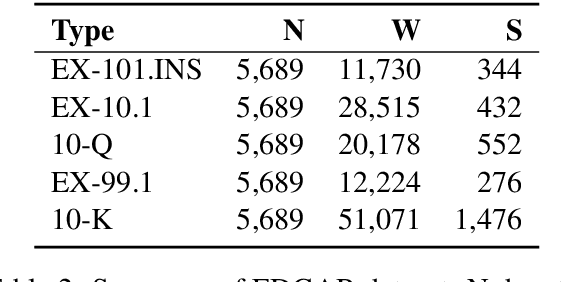
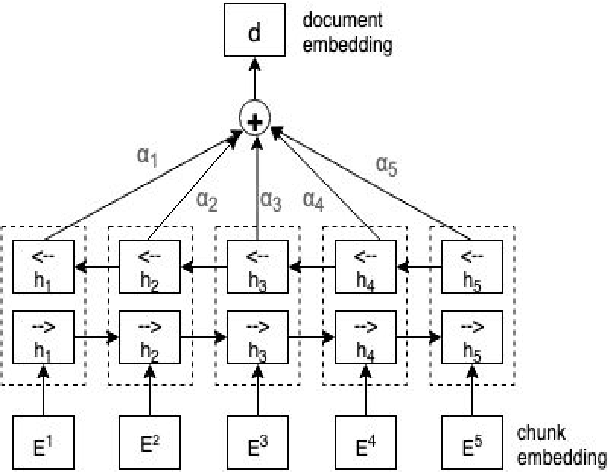
One of the principal tasks of machine learning with major applications is text classification. This paper focuses on the legal domain and, in particular, on the classification of lengthy legal documents. The main challenge that this study addresses is the limitation that current models impose on the length of the input text. In addition, the present paper shows that dividing the text into segments and later combining the resulting embeddings with a BiLSTM architecture to form a single document embedding can improve results. These advancements are achieved by utilising a simpler structure, rather than an increasingly complex one, which is often the case in NLP research. The dataset used in this paper is obtained from an online public database containing lengthy legal documents with highly domain-specific vocabulary and thus, the comparison of our results to the ones produced by models implemented on the commonly used datasets would be unjustified. This work provides the foundation for future work in document classification in the legal field.
Robust Non-linear Regression: A Greedy Approach Employing Kernels with Application to Image Denoising
Aug 03, 2016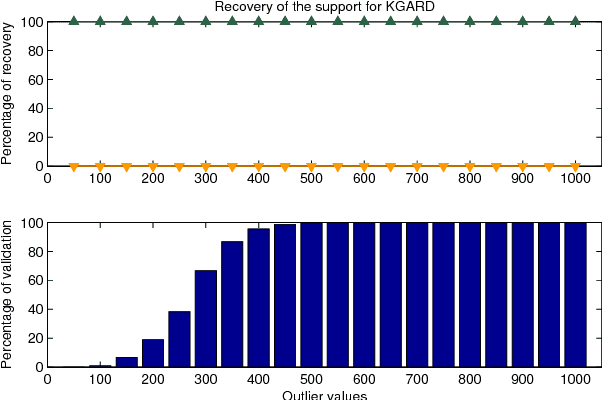
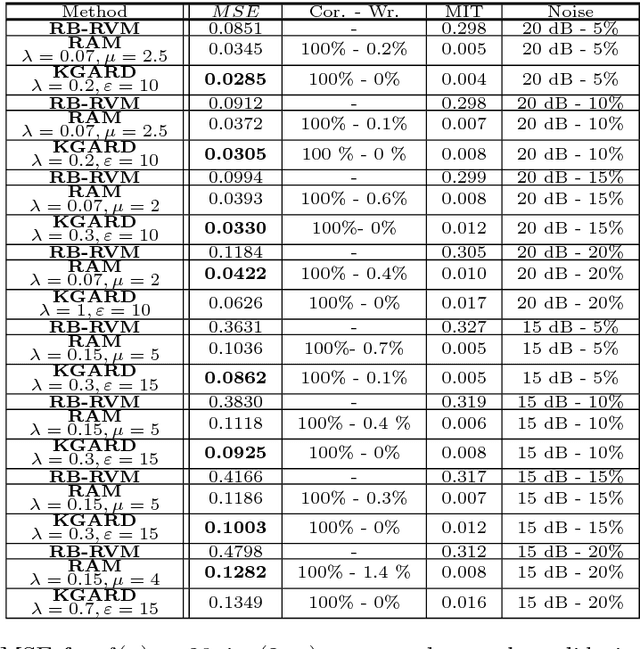
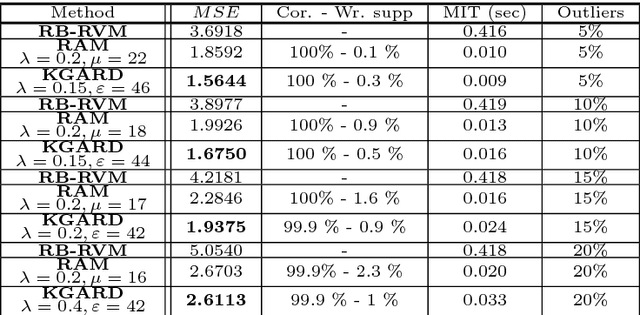
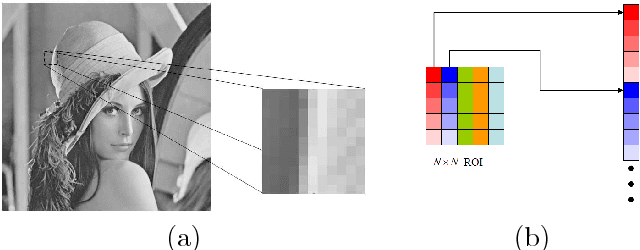
We consider the task of robust non-linear regression in the presence of both inlier noise and outliers. Assuming that the unknown non-linear function belongs to a Reproducing Kernel Hilbert Space (RKHS), our goal is to estimate the set of the associated unknown parameters. Due to the presence of outliers, common techniques such as the Kernel Ridge Regression (KRR) or the Support Vector Regression (SVR) turn out to be inadequate. Instead, we employ sparse modeling arguments to explicitly model and estimate the outliers, adopting a greedy approach. The proposed robust scheme, i.e., Kernel Greedy Algorithm for Robust Denoising (KGARD), is inspired by the classical Orthogonal Matching Pursuit (OMP) algorithm. Specifically, the proposed method alternates between a KRR task and an OMP-like selection step. Theoretical results concerning the identification of the outliers are provided. Moreover, KGARD is compared against other cutting edge methods, where its performance is evaluated via a set of experiments with various types of noise. Finally, the proposed robust estimation framework is applied to the task of image denoising, and its enhanced performance in the presence of outliers is demonstrated.