 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC$^2$FG: Control Classifier-Free Guidance via Score Discrepancy Analysis
Mar 09, 2026Classifier-Free Guidance (CFG) is a cornerstone of modern conditional diffusion models, yet its reliance on the fixed or heuristic dynamic guidance weight is predominantly empirical and overlooks the inherent dynamics of the diffusion process. In this paper, we provide a rigorous theoretical analysis of the Classifier-Free Guidance. Specifically, we establish strict upper bounds on the score discrepancy between conditional and unconditional distributions at different timesteps based on the diffusion process. This finding explains the limitations of fixed-weight strategies and establishes a principled foundation for time-dependent guidance. Motivated by this insight, we introduce \textbf{Control Classifier-Free Guidance (C$^2$FG)}, a novel, training-free, and plug-in method that aligns the guidance strength with the diffusion dynamics via an exponential decay control function. Extensive experiments demonstrate that C$^2$FG is effective and broadly applicable across diverse generative tasks, while also exhibiting orthogonality to existing strategies.
Revisiting Lightweight Low-Light Image Enhancement: From a YUV Color Space Perspective
Jan 24, 2026In the current era of mobile internet, Lightweight Low-Light Image Enhancement (L3IE) is critical for mobile devices, which faces a persistent trade-off between visual quality and model compactness. While recent methods employ disentangling strategies to simplify lightweight architectural design, such as Retinex theory and YUV color space transformations, their performance is fundamentally limited by overlooking channel-specific degradation patterns and cross-channel interactions. To address this gap, we perform a frequency-domain analysis that confirms the superiority of the YUV color space for L3IE. We identify a key insight: the Y channel primarily loses low-frequency content, while the UV channels are corrupted by high-frequency noise. Leveraging this finding, we propose a novel YUV-based paradigm that strategically restores channels using a Dual-Stream Global-Local Attention module for the Y channel, a Y-guided Local-Aware Frequency Attention module for the UV channels, and a Guided Interaction module for final feature fusion. Extensive experiments validate that our model establishes a new state-of-the-art on multiple benchmarks, delivering superior visual quality with a significantly lower parameter count.
Federated and Generalized Person Re-identification through Domain and Feature Hallucinating
Mar 08, 2022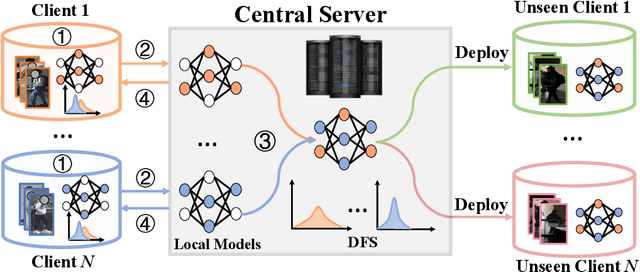
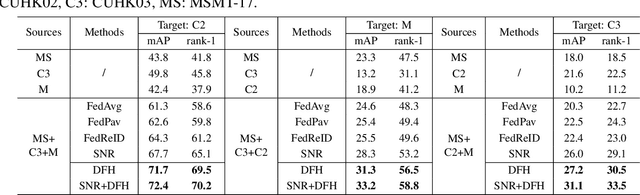
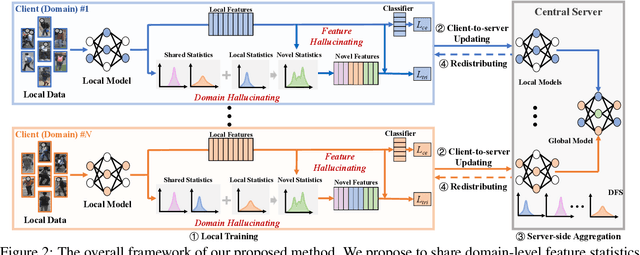
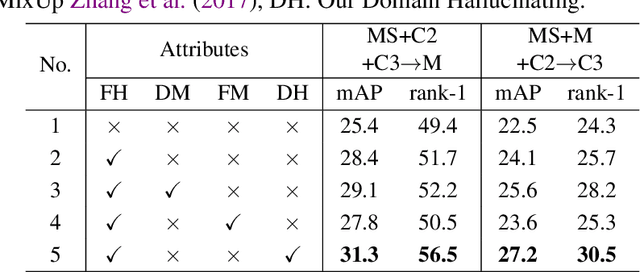
In this paper, we study the problem of federated domain generalization (FedDG) for person re-identification (re-ID), which aims to learn a generalized model with multiple decentralized labeled source domains. An empirical method (FedAvg) trains local models individually and averages them to obtain the global model for further local fine-tuning or deploying in unseen target domains. One drawback of FedAvg is neglecting the data distributions of other clients during local training, making the local model overfit local data and producing a poorly-generalized global model. To solve this problem, we propose a novel method, called "Domain and Feature Hallucinating (DFH)", to produce diverse features for learning generalized local and global models. Specifically, after each model aggregation process, we share the Domain-level Feature Statistics (DFS) among different clients without violating data privacy. During local training, the DFS are used to synthesize novel domain statistics with the proposed domain hallucinating, which is achieved by re-weighting DFS with random weights. Then, we propose feature hallucinating to diversify local features by scaling and shifting them to the distribution of the obtained novel domain. The synthesized novel features retain the original pair-wise similarities, enabling us to utilize them to optimize the model in a supervised manner. Extensive experiments verify that the proposed DFH can effectively improve the generalization ability of the global model. Our method achieves the state-of-the-art performance for FedDG on four large-scale re-ID benchmarks.
Joint Noise-Tolerant Learning and Meta Camera Shift Adaptation for Unsupervised Person Re-Identification
Mar 08, 2021
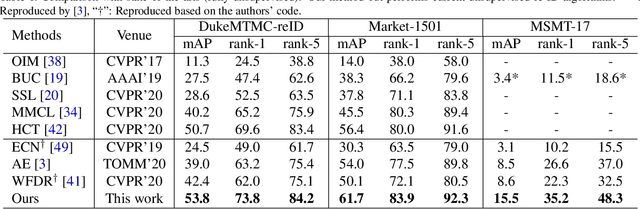

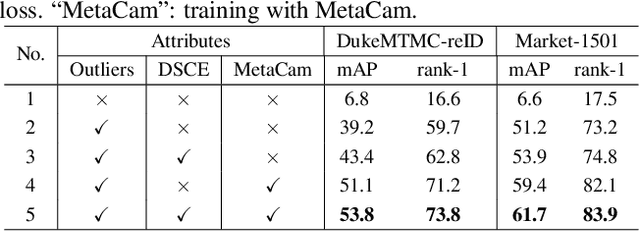
This paper considers the problem of unsupervised person re-identification (re-ID), which aims to learn discriminative models with unlabeled data. One popular method is to obtain pseudo-label by clustering and use them to optimize the model. Although this kind of approach has shown promising accuracy, it is hampered by 1) noisy labels produced by clustering and 2) feature variations caused by camera shift. The former will lead to incorrect optimization and thus hinders the model accuracy. The latter will result in assigning the intra-class samples of different cameras to different pseudo-label, making the model sensitive to camera variations. In this paper, we propose a unified framework to solve both problems. Concretely, we propose a Dynamic and Symmetric Cross-Entropy loss (DSCE) to deal with noisy samples and a camera-aware meta-learning algorithm (MetaCam) to adapt camera shift. DSCE can alleviate the negative effects of noisy samples and accommodate the change of clusters after each clustering step. MetaCam simulates cross-camera constraint by splitting the training data into meta-train and meta-test based on camera IDs. With the interacted gradient from meta-train and meta-test, the model is enforced to learn camera-invariant features. Extensive experiments on three re-ID benchmarks show the effectiveness and the complementary of the proposed DSCE and MetaCam. Our method outperforms the state-of-the-art methods on both fully unsupervised re-ID and unsupervised domain adaptive re-ID.
Learning to Generalize Unseen Domains via Memory-based Multi-Source Meta-Learning for Person Re-Identification
Dec 01, 2020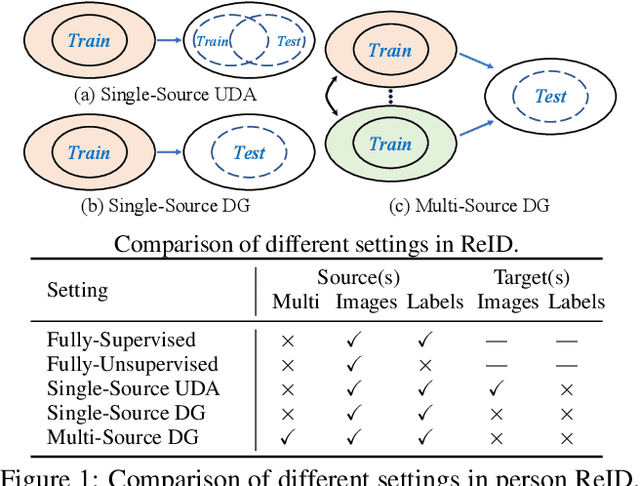
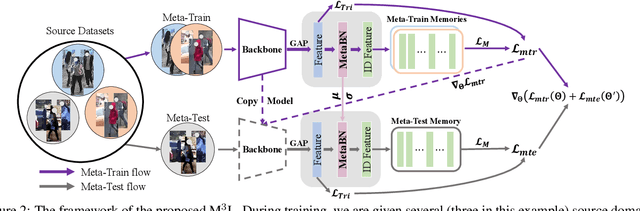
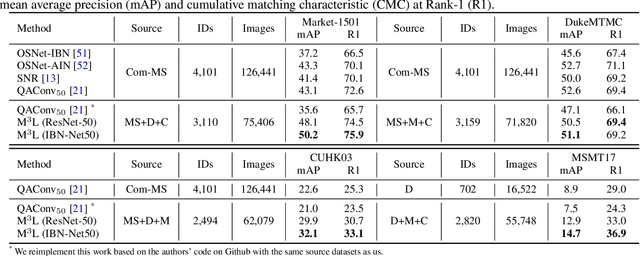
Recent advances in person re-identification (ReID) obtain impressive accuracy in the supervised and unsupervised learning settings. However, most of the existing methods need to train a new model for a new domain by accessing data. Due to public privacy, the new domain data are not always accessible, leading to a limited applicability of these methods. In this paper, we study the problem of multi-source domain generalization in ReID, which aims to learn a model that can perform well on unseen domains with only several labeled source domains. To address this problem, we propose the Memory-based Multi-Source Meta-Learning (M$^3$L) framework to train a generalizable model for unseen domains. Specifically, a meta-learning strategy is introduced to simulate the train-test process of domain generalization for learning more generalizable models. To overcome the unstable meta-optimization caused by the parametric classifier, we propose a memory-based identification loss that is non-parametric and harmonizes with meta-learning. We also present a meta batch normalization layer (MetaBN) to diversify meta-test features, further establishing the advantage of meta-learning. Experiments demonstrate that our M$^3$L can effectively enhance the generalization ability of the model for unseen domains and can outperform the state-of-the-art methods on four large-scale ReID datasets.
Asymmetric Co-Teaching for Unsupervised Cross Domain Person Re-Identification
Dec 03, 2019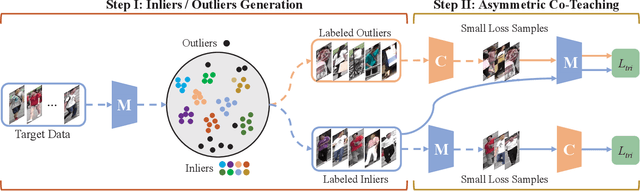
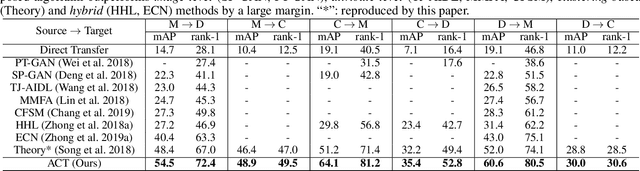
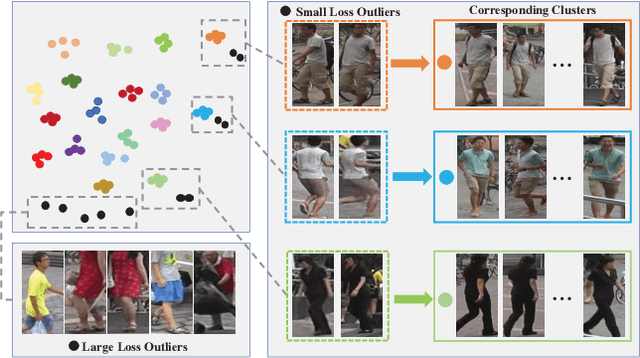

Person re-identification (re-ID), is a challenging task due to the high variance within identity samples and imaging conditions. Although recent advances in deep learning have achieved remarkable accuracy in settled scenes, i.e., source domain, few works can generalize well on the unseen target domain. One popular solution is assigning unlabeled target images with pseudo labels by clustering, and then retraining the model. However, clustering methods tend to introduce noisy labels and discard low confidence samples as outliers, which may hinder the retraining process and thus limit the generalization ability. In this study, we argue that by explicitly adding a sample filtering procedure after the clustering, the mined examples can be much more efficiently used. To this end, we design an asymmetric co-teaching framework, which resists noisy labels by cooperating two models to select data with possibly clean labels for each other. Meanwhile, one of the models receives samples as pure as possible, while the other takes in samples as diverse as possible. This procedure encourages that the selected training samples can be both clean and miscellaneous, and that the two models can promote each other iteratively. Extensive experiments show that the proposed framework can consistently benefit most clustering-based methods, and boost the state-of-the-art adaptation accuracy. Our code is available at https://github.com/FlyingRoastDuck/ACT_AAAI20.
Leveraging Virtual and Real Person for Unsupervised Person Re-identification
Nov 05, 2018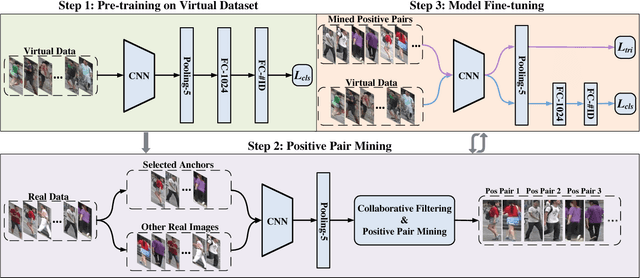
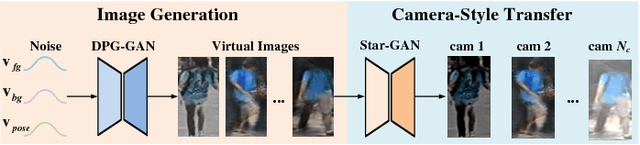

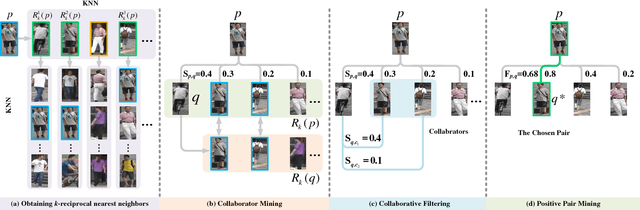
Person re-identification (re-ID) is a challenging problem especially when no labels are available for training. Although recent deep re-ID methods have achieved great improvement, it is still difficult to optimize deep re-ID model without annotations in training data. To address this problem, this study introduces a novel approach for unsupervised person re-ID by leveraging virtual and real data. Our approach includes two components: virtual person generation and training of deep re-ID model. For virtual person generation, we learn a person generation model and a camera style transfer model using unlabeled real data to generate virtual persons with different poses and camera styles. The virtual data is formed as labeled training data, enabling subsequently training deep re-ID model in supervision. For training of deep re-ID model, we divide it into three steps: 1) pre-training a coarse re-ID model by using virtual data; 2) collaborative filtering based positive pair mining from the real data; and 3) fine-tuning of the coarse re-ID model by leveraging the mined positive pairs and virtual data. The final re-ID model is achieved by iterating between step 2 and step 3 until convergence. Experimental results on two large-scale datasets, Market-1501 and DukeMTMC-reID, demonstrate the effectiveness of our approach and shows that the state of the art is achieved in unsupervised person re-ID.