 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Co-Teaching for Unsupervised Cross Domain Person Re-Identification
Paper and Code
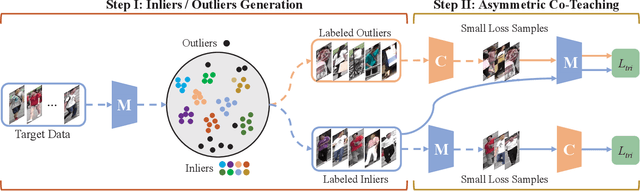
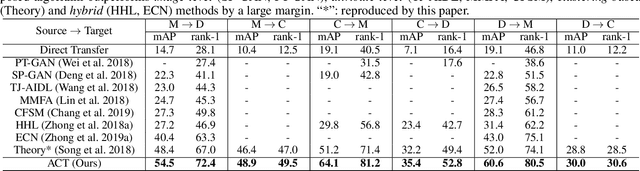
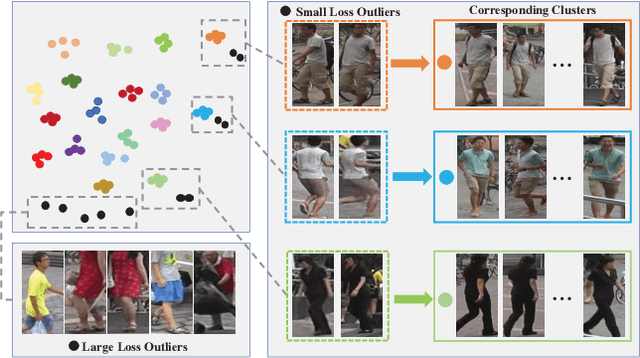

Person re-identification (re-ID), is a challenging task due to the high variance within identity samples and imaging conditions. Although recent advances in deep learning have achieved remarkable accuracy in settled scenes, i.e., source domain, few works can generalize well on the unseen target domain. One popular solution is assigning unlabeled target images with pseudo labels by clustering, and then retraining the model. However, clustering methods tend to introduce noisy labels and discard low confidence samples as outliers, which may hinder the retraining process and thus limit the generalization ability. In this study, we argue that by explicitly adding a sample filtering procedure after the clustering, the mined examples can be much more efficiently used. To this end, we design an asymmetric co-teaching framework, which resists noisy labels by cooperating two models to select data with possibly clean labels for each other. Meanwhile, one of the models receives samples as pure as possible, while the other takes in samples as diverse as possible. This procedure encourages that the selected training samples can be both clean and miscellaneous, and that the two models can promote each other iteratively. Extensive experiments show that the proposed framework can consistently benefit most clustering-based methods, and boost the state-of-the-art adaptation accuracy. Our code is available at https://github.com/FlyingRoastDuck/ACT_AAAI20.