 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Information Theory and Adversarial Learning for Cross-modal Retrieval
Apr 11, 2021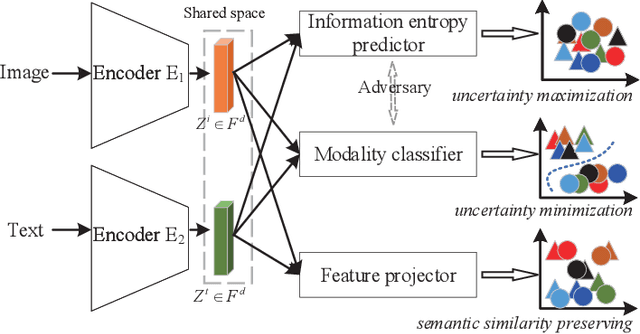
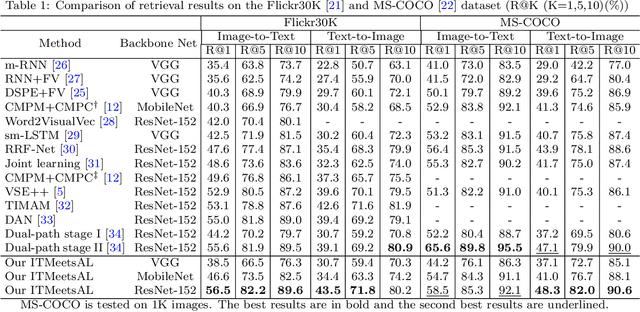
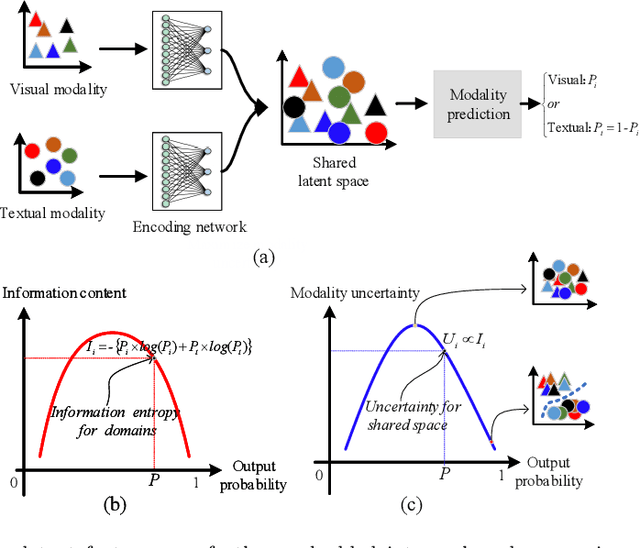
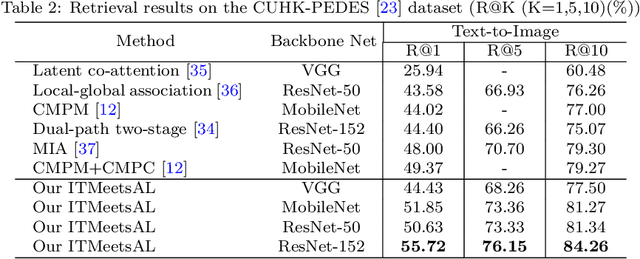
Accurately matching visual and textual data in cross-modal retrieval has been widely studied in the multimedia community. To address these challenges posited by the heterogeneity gap and the semantic gap, we propose integrating Shannon information theory and adversarial learning. In terms of the heterogeneity gap, we integrate modality classification and information entropy maximization adversarially. For this purpose, a modality classifier (as a discriminator) is built to distinguish the text and image modalities according to their different statistical properties. This discriminator uses its output probabilities to compute Shannon information entropy, which measures the uncertainty of the modality classification it performs. Moreover, feature encoders (as a generator) project uni-modal features into a commonly shared space and attempt to fool the discriminator by maximizing its output information entropy. Thus, maximizing information entropy gradually reduces the distribution discrepancy of cross-modal features, thereby achieving a domain confusion state where the discriminator cannot classify two modalities confidently. To reduce the semantic gap, Kullback-Leibler (KL) divergence and bi-directional triplet loss are used to associate the intra- and inter-modality similarity between features in the shared space. Furthermore, a regularization term based on KL-divergence with temperature scaling is used to calibrate the biased label classifier caused by the data imbalance issue. Extensive experiments with four deep models on four benchmarks are conducted to demonstrate the effectiveness of the proposed approach.
Lifelong Person Re-Identification via Adaptive Knowledge Accumulation
Mar 23, 2021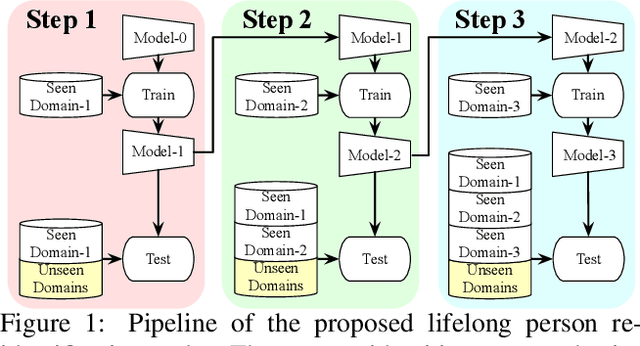
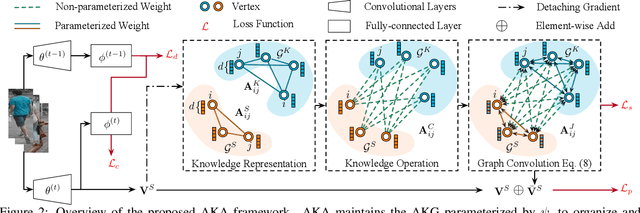
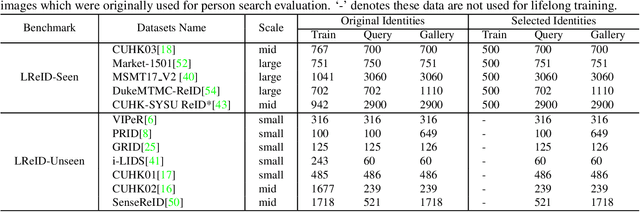
Person ReID methods always learn through a stationary domain that is fixed by the choice of a given dataset. In many contexts (e.g., lifelong learning), those methods are ineffective because the domain is continually changing in which case incremental learning over multiple domains is required potentially. In this work we explore a new and challenging ReID task, namely lifelong person re-identification (LReID), which enables to learn continuously across multiple domains and even generalise on new and unseen domains. Following the cognitive processes in the human brain, we design an Adaptive Knowledge Accumulation (AKA) framework that is endowed with two crucial abilities: knowledge representation and knowledge operation. Our method alleviates catastrophic forgetting on seen domains and demonstrates the ability to generalize to unseen domains. Correspondingly, we also provide a new and large-scale benchmark for LReID. Extensive experiments demonstrate our method outperforms other competitors by a margin of 5.8% mAP in generalising evaluation.
On the Exploration of Incremental Learning for Fine-grained Image Retrieval
Oct 15, 2020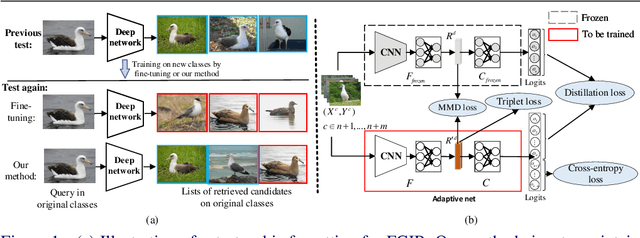
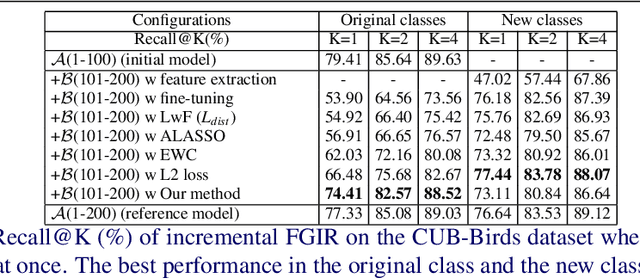
In this paper, we consider the problem of fine-grained image retrieval in an incremental setting, when new categories are added over time. On the one hand, repeatedly training the representation on the extended dataset is time-consuming. On the other hand, fine-tuning the learned representation only with the new classes leads to catastrophic forgetting. To this end, we propose an incremental learning method to mitigate retrieval performance degradation caused by the forgetting issue. Without accessing any samples of the original classes, the classifier of the original network provides soft "labels" to transfer knowledge to train the adaptive network, so as to preserve the previous capability for classification. More importantly, a regularization function based on Maximum Mean Discrepancy is devised to minimize the discrepancy of new classes features from the original network and the adaptive network, respectively. Extensive experiments on two datasets show that our method effectively mitigates the catastrophic forgetting on the original classes while achieving high performance on the new classes.
Dual Gaussian-based Variational Subspace Disentanglement for Visible-Infrared Person Re-Identification
Aug 06, 2020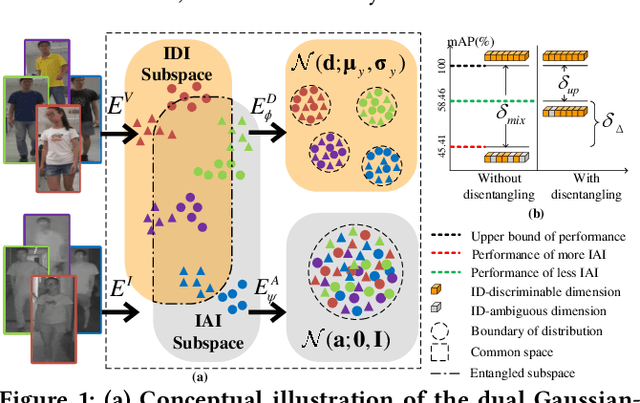
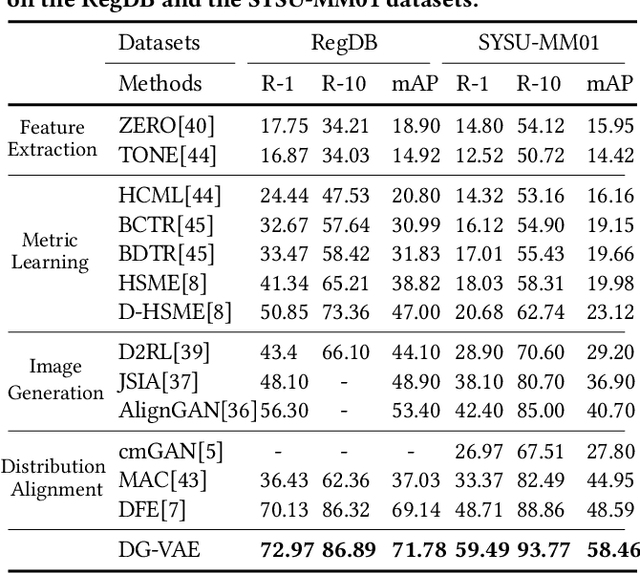
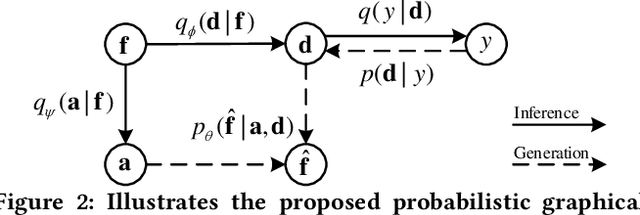
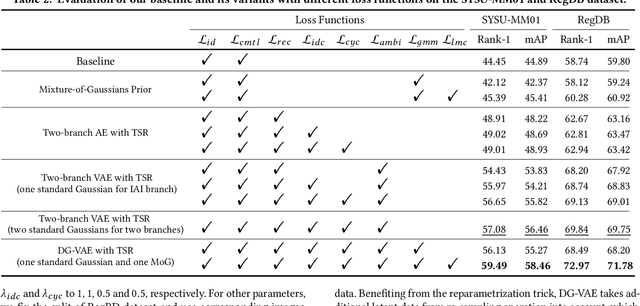
Visible-infrared person re-identification (VI-ReID) is a challenging and essential task in night-time intelligent surveillance systems. Except for the intra-modality variance that RGB-RGB person re-identification mainly overcomes, VI-ReID suffers from additional inter-modality variance caused by the inherent heterogeneous gap. To solve the problem, we present a carefully designed dual Gaussian-based variational auto-encoder (DG-VAE), which disentangles an identity-discriminable and an identity-ambiguous cross-modality feature subspace, following a mixture-of-Gaussians (MoG) prior and a standard Gaussian distribution prior, respectively. Disentangling cross-modality identity-discriminable features leads to more robust retrieval for VI-ReID. To achieve efficient optimization like conventional VAE, we theoretically derive two variational inference terms for the MoG prior under the supervised setting, which not only restricts the identity-discriminable subspace so that the model explicitly handles the cross-modality intra-identity variance, but also enables the MoG distribution to avoid posterior collapse. Furthermore, we propose a triplet swap reconstruction (TSR) strategy to promote the above disentangling process. Extensive experiments demonstrate that our method outperforms state-of-the-art methods on two VI-ReID datasets.
Alignment of Microtubule Imagery
May 30, 2011



This work discusses preliminary work aimed at simulating and visualizing the growth process of a tiny structure inside the cell---the microtubule. Difficulty of recording the process lies in the fact that the tissue preparation method for electronic microscopes is highly destructive to live cells. Here in this paper, our approach is to take pictures of microtubules at different time slots and then appropriately combine these images into a coherent video. Experimental results are given on real data.