 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadiusFPS: Efficient Farthest Point Sampling on CPUs and GPUs via Spherical Voxel Pruning
Jun 04, 2026Point clouds are a primary sensory representation for robotic perception, underpinning LiDAR-based autonomous driving, simultaneous localization and mapping (SLAM), and navigation. Within these pipelines, Farthest Point Sampling (FPS) is the most well-known downsampling operator, as its uniform coverage preserves the geometric structure on which downstream perception relies. However, the large time complexity of classical FPS scales poorly with the million-point-per-second rates of modern 3D sensors, making it a dominant latency bottleneck that conflicts with the real-time and limited onboard compute budgets of robotic systems. Therefore, we propose RadiusFPS, an FPS acceleration framework based on spherical voxel pruning that preserves the standard FPS update rule under the same initialization and tie-breaking policy. By indexing the point cloud with spherical voxels, RadiusFPS derives a conservative geometric bound that prunes redundant distance computations in each iteration, complemented by a coordinate-wise point-skip test that removes residual updates. We further introduce RadiusFPS-G, a warp-level GPU implementation that fuses voxel selection, pruning, and distance update into memory-coalesced kernels, eliminating costly global-memory round-trips. On indoor (S3DIS, ScanNet) and outdoor LiDAR (SemanticKITTI) benchmarks, RadiusFPS-G attains up to 2.5x speedup over GPU-based FPS and matches or exceeds QuickFPS among the evaluated methods while using roughly half its GPU memory, with comparable segmentation accuracy. When coupled with the learning-based FastPoint sampler, the resulting pipeline achieves the fastest End-to-End inference among all evaluated configurations. These properties make high-quality FPS-style sampling practical for latency- and memory-constrained robotic vision.
Faster than Fast: Accelerating Oriented FAST Feature Detection on Low-end Embedded GPUs
Jun 08, 2025The visual-based SLAM (Simultaneous Localization and Mapping) is a technology widely used in applications such as robotic navigation and virtual reality, which primarily focuses on detecting feature points from visual images to construct an unknown environmental map and simultaneously determines its own location. It usually imposes stringent requirements on hardware power consumption, processing speed and accuracy. Currently, the ORB (Oriented FAST and Rotated BRIEF)-based SLAM systems have exhibited superior performance in terms of processing speed and robustness. However, they still fall short of meeting the demands for real-time processing on mobile platforms. This limitation is primarily due to the time-consuming Oriented FAST calculations accounting for approximately half of the entire SLAM system. This paper presents two methods to accelerate the Oriented FAST feature detection on low-end embedded GPUs. These methods optimize the most time-consuming steps in Oriented FAST feature detection: FAST feature point detection and Harris corner detection, which is achieved by implementing a binary-level encoding strategy to determine candidate points quickly and a separable Harris detection strategy with efficient low-level GPU hardware-specific instructions. Extensive experiments on a Jetson TX2 embedded GPU demonstrate an average speedup of over 7.3 times compared to widely used OpenCV with GPU support. This significant improvement highlights its effectiveness and potential for real-time applications in mobile and resource-constrained environments.
StereoVAE: A lightweight stereo matching system through embedded GPUs
May 25, 2023We present a lightweight system for stereo matching through embedded GPUs. It breaks the trade-off between accuracy and processing speed in stereo matching, enabling our embedded system to further improve the matching accuracy while ensuring real-time processing. The main idea of our method is to construct a tiny neural network based on variational auto-encoder (VAE) to upsample and refinement a small size of coarse disparity map, which is first generated by a traditional matching method. The proposed hybrid structure cannot only bring the advantage of traditional methods in terms of computational complexity, but also ensure the matching accuracy under the impact of neural network. Extensive experiments on the KITTI 2015 benchmark demonstrate that our tiny system exhibits high robustness in improving the accuracy of the coarse disparity maps generated by different algorithms, while also running in real-time on embedded GPUs.
Efficient stereo matching on embedded GPUs with zero-means cross correlation
Dec 01, 2022


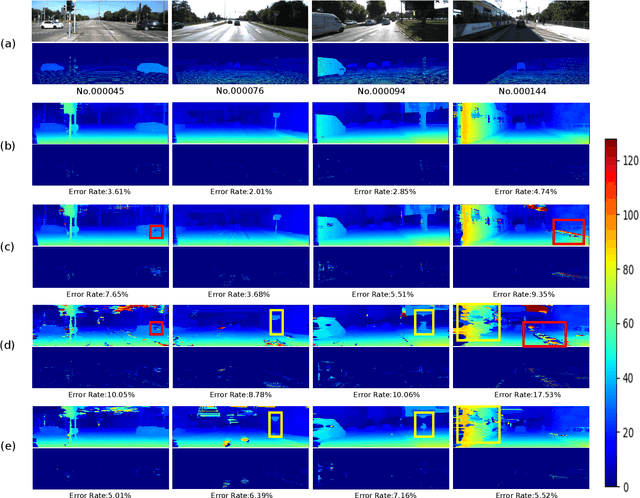
Mobile stereo-matching systems have become an important part of many applications, such as automated-driving vehicles and autonomous robots. Accurate stereo-matching methods usually lead to high computational complexity; however, mobile platforms have only limited hardware resources to keep their power consumption low; this makes it difficult to maintain both an acceptable processing speed and accuracy on mobile platforms. To resolve this trade-off, we herein propose a novel acceleration approach for the well-known zero-means normalized cross correlation (ZNCC) matching cost calculation algorithm on a Jetson Tx2 embedded GPU. In our method for accelerating ZNCC, target images are scanned in a zigzag fashion to efficiently reuse one pixel's computation for its neighboring pixels; this reduces the amount of data transmission and increases the utilization of on-chip registers, thus increasing the processing speed. As a result, our method is 2X faster than the traditional image scanning method, and 26% faster than the latest NCC method. By combining this technique with the domain transformation (DT) algorithm, our system show real-time processing speed of 32 fps, on a Jetson Tx2 GPU for 1,280x384 pixel images with a maximum disparity of 128. Additionally, the evaluation results on the KITTI 2015 benchmark show that our combined system is more accurate than the same algorithm combined with census by 7.26%, while maintaining almost the same processing speed.
Real-Time High-Quality Stereo Matching System on a GPU
Dec 01, 2022In this paper, we propose a low error rate and real-time stereo vision system on GPU. Many stereo vision systems on GPU have been proposed to date. In those systems, the error rates and the processing speed are in trade-off relationship. We propose a real-time stereo vision system on GPU for the high resolution images. This system also maintains a low error rate compared to other fast systems. In our approach, we have implemented the cost aggregation (CA), cross-checking and median filter on GPU in order to realize the real-time processing. Its processing speed is 40 fps for 1436x992 pixels images when the maximum disparity is 145, and its error rate is the lowest among the GPU systems which are faster than 30 fps.
Interpretable Edge Enhancement and Suppression Learning for 3D Point Cloud Segmentation
Sep 20, 2022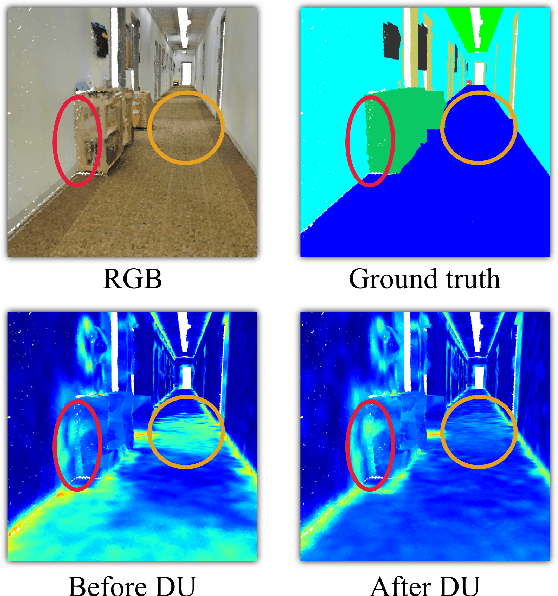
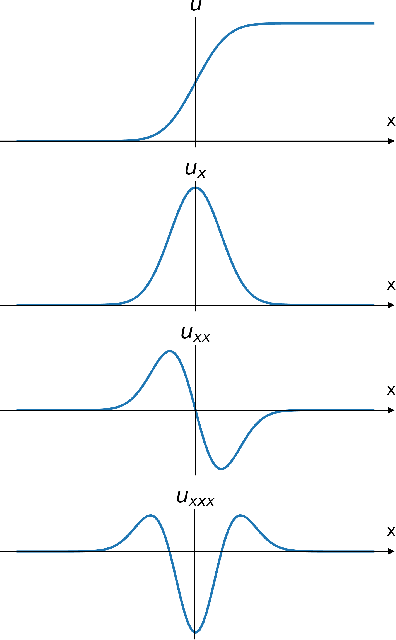
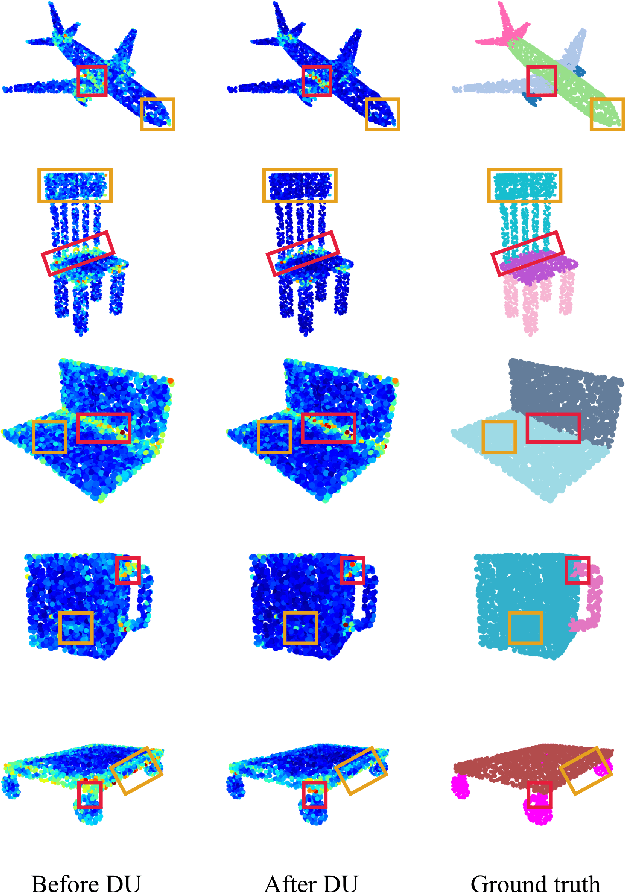
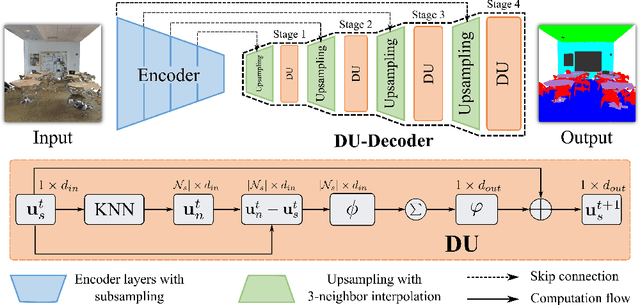
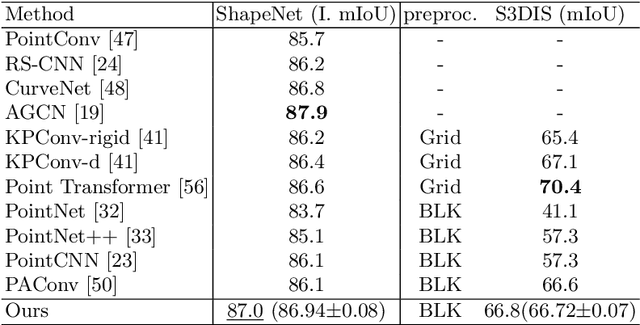
3D point clouds can flexibly represent continuous surfaces and can be used for various applications; however, the lack of structural information makes point cloud recognition challenging. Recent edge-aware methods mainly use edge information as an extra feature that describes local structures to facilitate learning. Although these methods show that incorporating edges into the network design is beneficial, they generally lack interpretability, making users wonder how exactly edges help. To shed light on this issue, in this study, we propose the Diffusion Unit (DU) that handles edges in an interpretable manner while providing decent improvement. Our method is interpretable in three ways. First, we theoretically show that DU learns to perform task-beneficial edge enhancement and suppression. Second, we experimentally observe and verify the edge enhancement and suppression behavior. Third, we empirically demonstrate that this behavior contributes to performance improvement. Extensive experiments performed on challenging benchmarks verify the superiority of DU in terms of both interpretability and performance gain. Specifically, our method achieves state-of-the-art performance in object part segmentation using ShapeNet part and scene segmentation using S3DIS. Our source code will be released at https://github.com/martianxiu/DiffusionUnit.
Enhancing Local Geometry Learning for 3D Point Cloud via Decoupling Convolution
Jul 04, 2022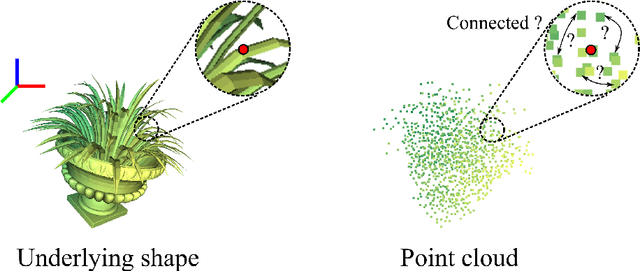
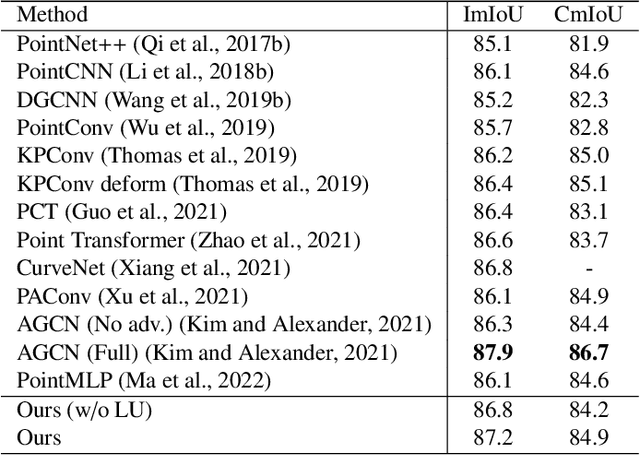
Modeling the local surface geometry is challenging in 3D point cloud understanding due to the lack of connectivity information. Most prior works model local geometry using various convolution operations. We observe that the convolution can be equivalently decomposed as a weighted combination of a local and a global component. With this observation, we explicitly decouple these two components so that the local one can be enhanced and facilitate the learning of local surface geometry. Specifically, we propose Laplacian Unit (LU), a simple yet effective architectural unit that can enhance the learning of local geometry. Extensive experiments demonstrate that networks equipped with LUs achieve competitive or superior performance on typical point cloud understanding tasks. Moreover, through establishing connections between the mean curvature flow, a further investigation of LU based on curvatures is made to interpret the adaptive smoothing and sharpening effect of LU. The code will be available.
Enhancing Local Feature Learning Using Diffusion for 3D Point Cloud Understanding
Jul 04, 2022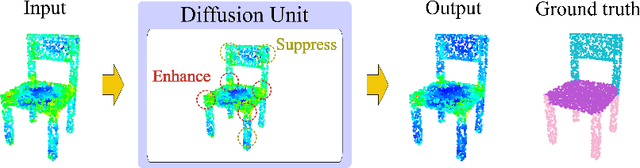

Learning point clouds is challenging due to the lack of connectivity information, i.e., edges. Although existing edge-aware methods can improve the performance by modeling edges, how edges contribute to the improvement is unclear. In this study, we propose a method that automatically learns to enhance/suppress edges while keeping the its working mechanism clear. First, we theoretically figure out how edge enhancement/suppression works. Second, we experimentally verify the edge enhancement/suppression behavior. Third, we empirically show that this behavior improves performance. In general, we observe that the proposed method achieves competitive performance in point cloud classification and segmentation tasks.
Enhancing Local Feature Learning for 3D Point Cloud Processing using Unary-Pairwise Attention
Mar 17, 2022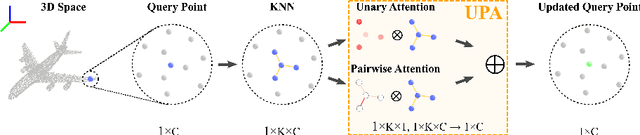
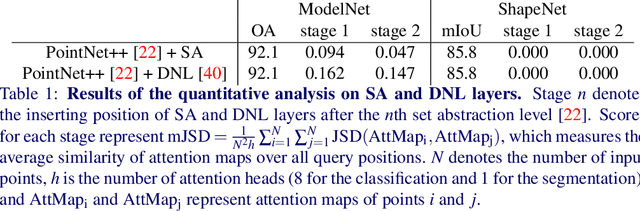
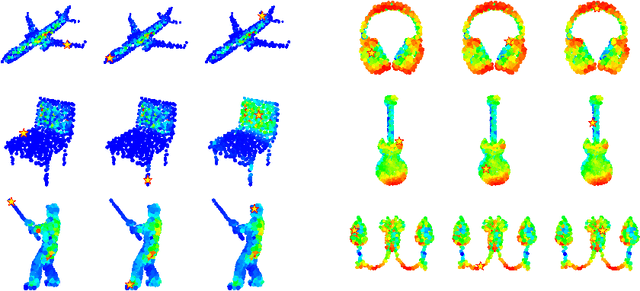
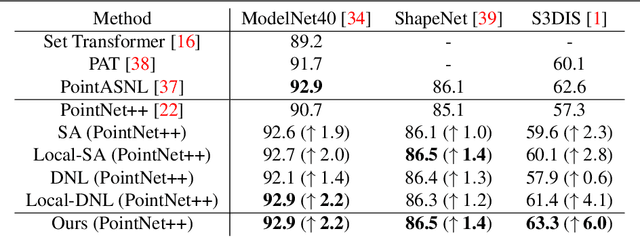
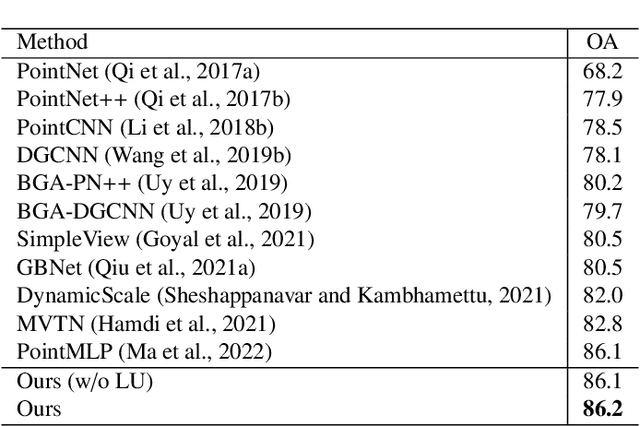
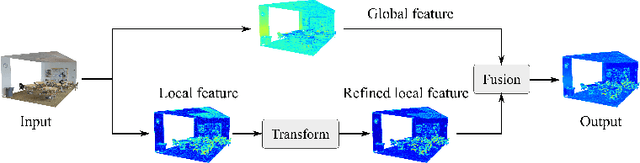
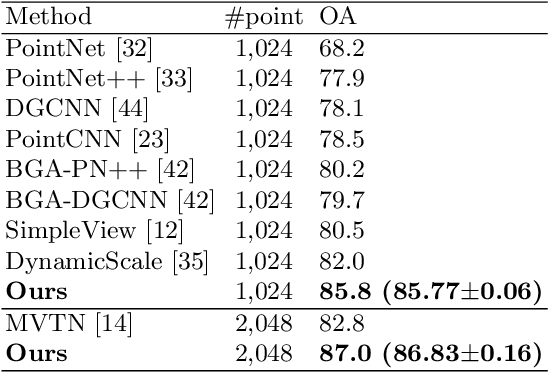
We present a simple but effective attention named the unary-pairwise attention (UPA) for modeling the relationship between 3D point clouds. Our idea is motivated by the analysis that the standard self-attention (SA) that operates globally tends to produce almost the same attention maps for different query positions, revealing difficulties for learning query-independent and query-dependent information jointly. Therefore, we reformulate the SA and propose query-independent (Unary) and query-dependent (Pairwise) components to facilitate the learning of both terms. In contrast to the SA, the UPA ensures query dependence via operating locally. Extensive experiments show that the UPA outperforms the SA consistently on various point cloud understanding tasks including shape classification, part segmentation, and scene segmentation. Moreover, simply equipping the popular PointNet++ method with the UPA even outperforms or is on par with the state-of-the-art attention-based approaches. In addition, the UPA systematically boosts the performance of both standard and modern networks when it is integrated into them as a compositional module.