 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSECNet: Accurate and Robust Normal Estimation for 3D Point Clouds by Multi-Scale Edge Conditioning
Aug 23, 2023



Estimating surface normals from 3D point clouds is critical for various applications, including surface reconstruction and rendering. While existing methods for normal estimation perform well in regions where normals change slowly, they tend to fail where normals vary rapidly. To address this issue, we propose a novel approach called MSECNet, which improves estimation in normal varying regions by treating normal variation modeling as an edge detection problem. MSECNet consists of a backbone network and a multi-scale edge conditioning (MSEC) stream. The MSEC stream achieves robust edge detection through multi-scale feature fusion and adaptive edge detection. The detected edges are then combined with the output of the backbone network using the edge conditioning module to produce edge-aware representations. Extensive experiments show that MSECNet outperforms existing methods on both synthetic (PCPNet) and real-world (SceneNN) datasets while running significantly faster. We also conduct various analyses to investigate the contribution of each component in the MSEC stream. Finally, we demonstrate the effectiveness of our approach in surface reconstruction.
Interpretable Edge Enhancement and Suppression Learning for 3D Point Cloud Segmentation
Sep 20, 2022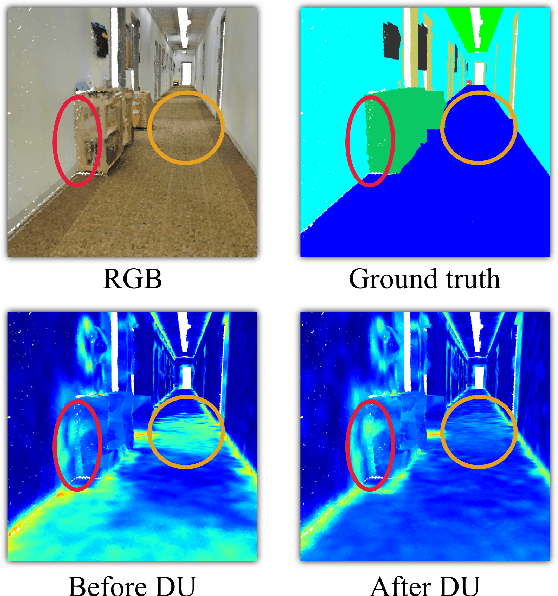
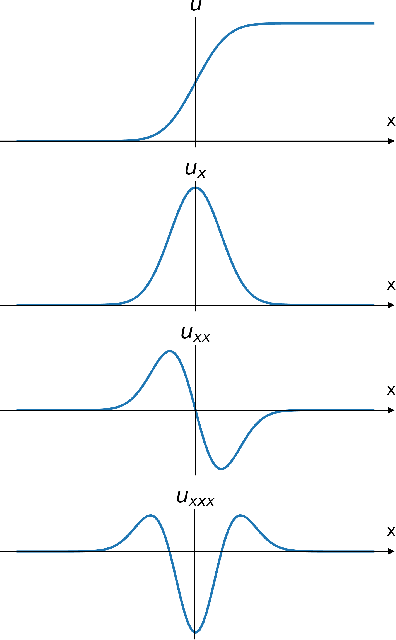
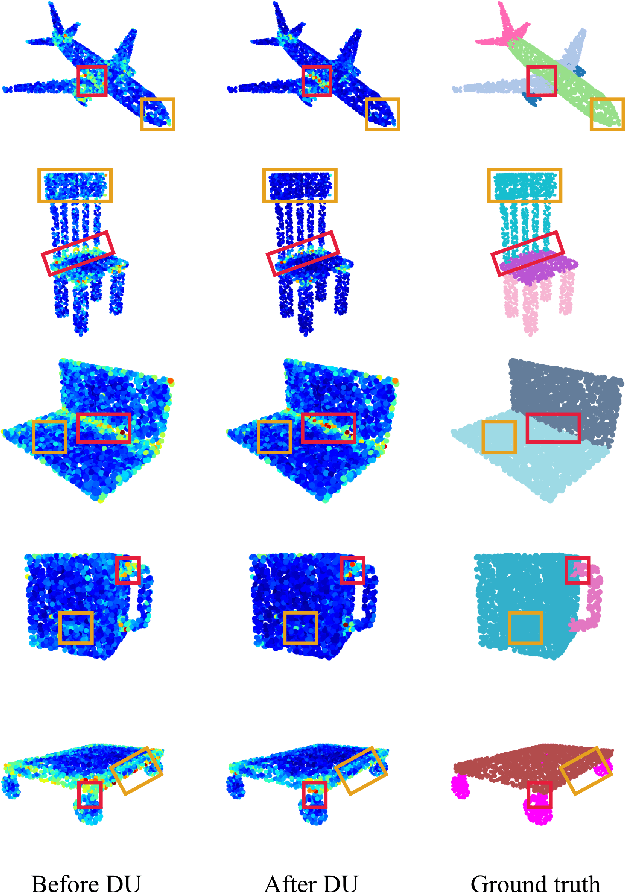
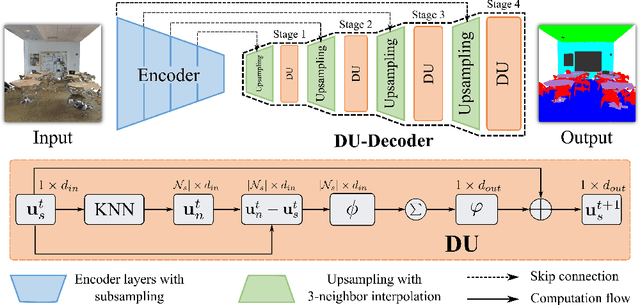
3D point clouds can flexibly represent continuous surfaces and can be used for various applications; however, the lack of structural information makes point cloud recognition challenging. Recent edge-aware methods mainly use edge information as an extra feature that describes local structures to facilitate learning. Although these methods show that incorporating edges into the network design is beneficial, they generally lack interpretability, making users wonder how exactly edges help. To shed light on this issue, in this study, we propose the Diffusion Unit (DU) that handles edges in an interpretable manner while providing decent improvement. Our method is interpretable in three ways. First, we theoretically show that DU learns to perform task-beneficial edge enhancement and suppression. Second, we experimentally observe and verify the edge enhancement and suppression behavior. Third, we empirically demonstrate that this behavior contributes to performance improvement. Extensive experiments performed on challenging benchmarks verify the superiority of DU in terms of both interpretability and performance gain. Specifically, our method achieves state-of-the-art performance in object part segmentation using ShapeNet part and scene segmentation using S3DIS. Our source code will be released at https://github.com/martianxiu/DiffusionUnit.
Enhancing Local Geometry Learning for 3D Point Cloud via Decoupling Convolution
Jul 04, 2022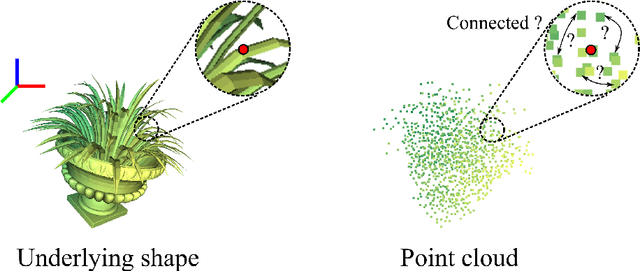
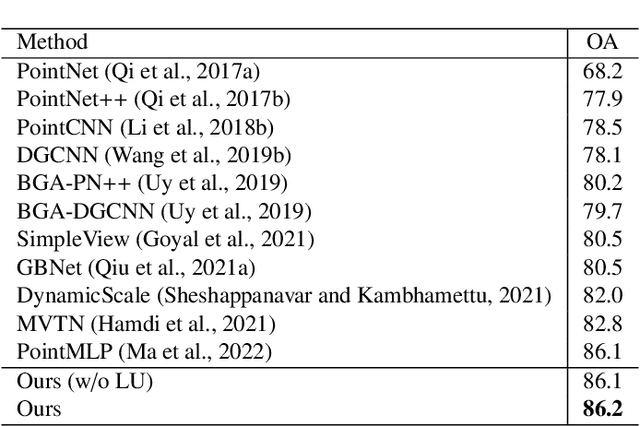
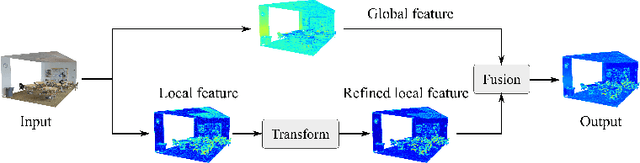
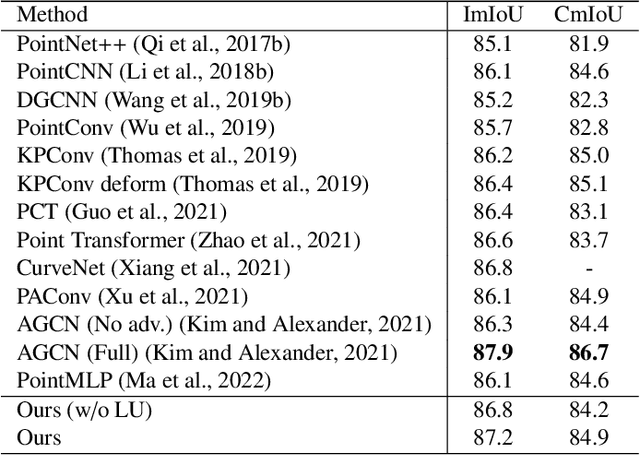
Modeling the local surface geometry is challenging in 3D point cloud understanding due to the lack of connectivity information. Most prior works model local geometry using various convolution operations. We observe that the convolution can be equivalently decomposed as a weighted combination of a local and a global component. With this observation, we explicitly decouple these two components so that the local one can be enhanced and facilitate the learning of local surface geometry. Specifically, we propose Laplacian Unit (LU), a simple yet effective architectural unit that can enhance the learning of local geometry. Extensive experiments demonstrate that networks equipped with LUs achieve competitive or superior performance on typical point cloud understanding tasks. Moreover, through establishing connections between the mean curvature flow, a further investigation of LU based on curvatures is made to interpret the adaptive smoothing and sharpening effect of LU. The code will be available.
Enhancing Local Feature Learning Using Diffusion for 3D Point Cloud Understanding
Jul 04, 2022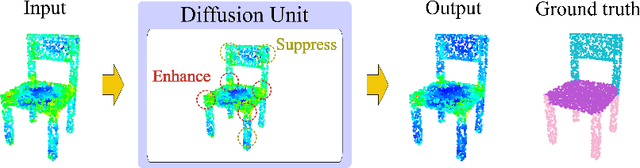
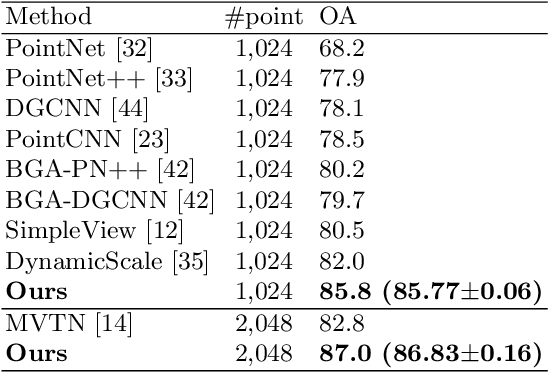
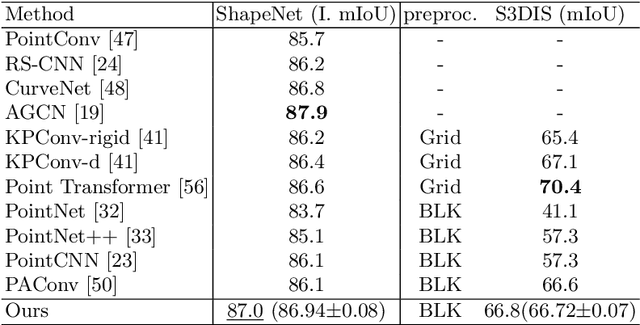

Learning point clouds is challenging due to the lack of connectivity information, i.e., edges. Although existing edge-aware methods can improve the performance by modeling edges, how edges contribute to the improvement is unclear. In this study, we propose a method that automatically learns to enhance/suppress edges while keeping the its working mechanism clear. First, we theoretically figure out how edge enhancement/suppression works. Second, we experimentally verify the edge enhancement/suppression behavior. Third, we empirically show that this behavior improves performance. In general, we observe that the proposed method achieves competitive performance in point cloud classification and segmentation tasks.
Enhancing Local Feature Learning for 3D Point Cloud Processing using Unary-Pairwise Attention
Mar 17, 2022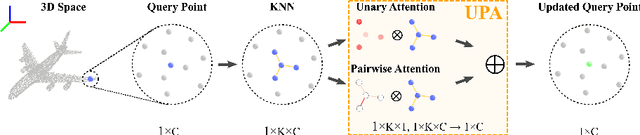
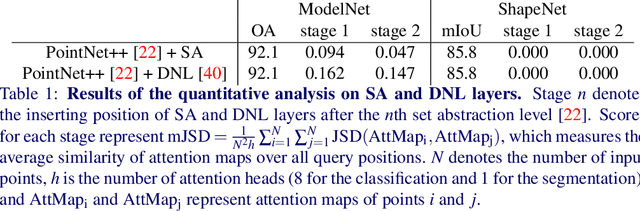
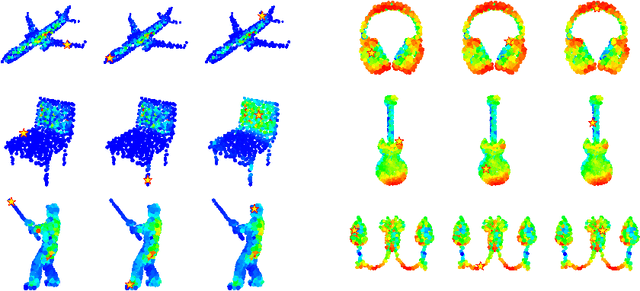
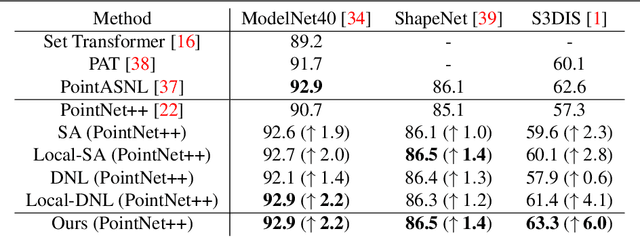
We present a simple but effective attention named the unary-pairwise attention (UPA) for modeling the relationship between 3D point clouds. Our idea is motivated by the analysis that the standard self-attention (SA) that operates globally tends to produce almost the same attention maps for different query positions, revealing difficulties for learning query-independent and query-dependent information jointly. Therefore, we reformulate the SA and propose query-independent (Unary) and query-dependent (Pairwise) components to facilitate the learning of both terms. In contrast to the SA, the UPA ensures query dependence via operating locally. Extensive experiments show that the UPA outperforms the SA consistently on various point cloud understanding tasks including shape classification, part segmentation, and scene segmentation. Moreover, simply equipping the popular PointNet++ method with the UPA even outperforms or is on par with the state-of-the-art attention-based approaches. In addition, the UPA systematically boosts the performance of both standard and modern networks when it is integrated into them as a compositional module.
Learning from Multimodal and Multitemporal Earth Observation Data for Building Damage Mapping
Sep 14, 2020Earth observation technologies, such as optical imaging and synthetic aperture radar (SAR), provide excellent means to monitor ever-growing urban environments continuously. Notably, in the case of large-scale disasters (e.g., tsunamis and earthquakes), in which a response is highly time-critical, images from both data modalities can complement each other to accurately convey the full damage condition in the disaster's aftermath. However, due to several factors, such as weather and satellite coverage, it is often uncertain which data modality will be the first available for rapid disaster response efforts. Hence, novel methodologies that can utilize all accessible EO datasets are essential for disaster management. In this study, we have developed a global multisensor and multitemporal dataset for building damage mapping. We included building damage characteristics from three disaster types, namely, earthquakes, tsunamis, and typhoons, and considered three building damage categories. The global dataset contains high-resolution optical imagery and high-to-moderate-resolution multiband SAR data acquired before and after each disaster. Using this comprehensive dataset, we analyzed five data modality scenarios for damage mapping: single-mode (optical and SAR datasets), cross-modal (pre-disaster optical and post-disaster SAR datasets), and mode fusion scenarios. We defined a damage mapping framework for the semantic segmentation of damaged buildings based on a deep convolutional neural network algorithm. We compare our approach to another state-of-the-art baseline model for damage mapping. The results indicated that our dataset, together with a deep learning network, enabled acceptable predictions for all the data modality scenarios.
Filmy Cloud Removal on Satellite Imagery with Multispectral Conditional Generative Adversarial Nets
Oct 13, 2017
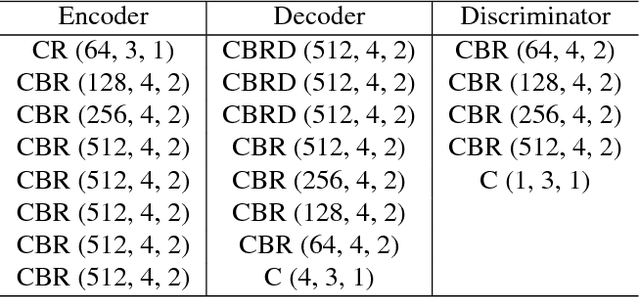


In this paper, we propose a method for cloud removal from visible light RGB satellite images by extending the conditional Generative Adversarial Networks (cGANs) from RGB images to multispectral images. Satellite images have been widely utilized for various purposes, such as natural environment monitoring (pollution, forest or rivers), transportation improvement and prompt emergency response to disasters. However, the obscurity caused by clouds makes it unstable to monitor the situation on the ground with the visible light camera. Images captured by a longer wavelength are introduced to reduce the effects of clouds. Synthetic Aperture Radar (SAR) is such an example that improves visibility even the clouds exist. On the other hand, the spatial resolution decreases as the wavelength increases. Furthermore, the images captured by long wavelengths differs considerably from those captured by visible light in terms of their appearance. Therefore, we propose a network that can remove clouds and generate visible light images from the multispectral images taken as inputs. This is achieved by extending the input channels of cGANs to be compatible with multispectral images. The networks are trained to output images that are close to the ground truth using the images synthesized with clouds over the ground truth as inputs. In the available dataset, the proportion of images of the forest or the sea is very high, which will introduce bias in the training dataset if uniformly sampled from the original dataset. Thus, we utilize the t-Distributed Stochastic Neighbor Embedding (t-SNE) to improve the problem of bias in the training dataset. Finally, we confirm the feasibility of the proposed network on the dataset of four bands images, which include three visible light bands and one near-infrared (NIR) band.