 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorVS: Person Identification via Video Trajectory-Sensor Correspondence in a Real-World Warehouse
Oct 30, 2025Worker location data is key to higher productivity in industrial sites. Cameras are a promising tool for localization in logistics warehouses since they also offer valuable environmental contexts such as package status. However, identifying individuals with only visual data is often impractical. Accordingly, several prior studies identified people in videos by comparing their trajectories and wearable sensor measurements. While this approach has advantages such as independence from appearance, the existing methods may break down under real-world conditions. To overcome this challenge, we propose CorVS, a novel data-driven person identification method based on correspondence between visual tracking trajectories and sensor measurements. Firstly, our deep learning model predicts correspondence probabilities and reliabilities for every pair of a trajectory and sensor measurements. Secondly, our algorithm matches the trajectories and sensor measurements over time using the predicted probabilities and reliabilities. We developed a dataset with actual warehouse operations and demonstrated the method's effectiveness for real-world applications.
OpenUAS: Embeddings of Cities in Japan with Anchor Data for Cross-city Analysis of Area Usage Patterns
Jul 29, 2024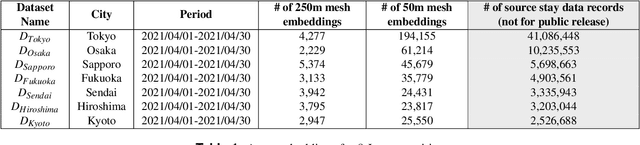
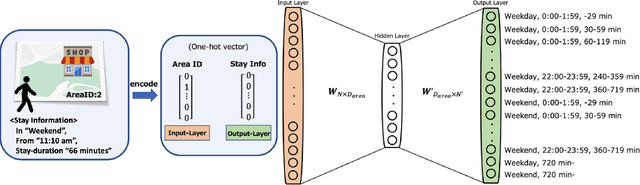
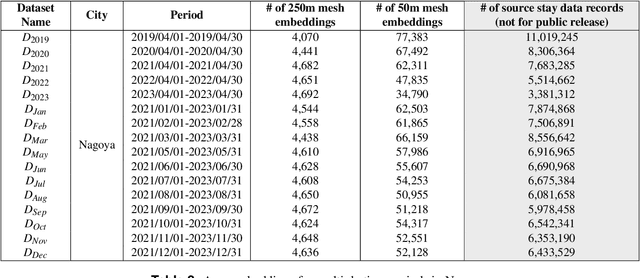
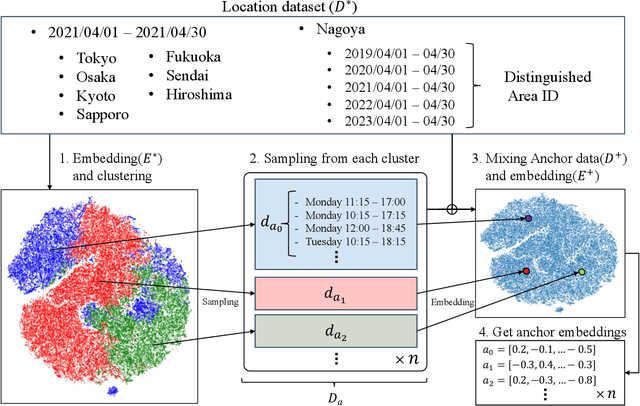
We publicly release OpenUAS, a dataset of area embeddings based on urban usage patterns, including embeddings for over 1.3 million 50-meter square meshes covering a total area of 3,300 square kilometers. This dataset is valuable for analyzing area functions in fields such as market analysis, urban planning, transportation infrastructure, and infection prediction. It captures the characteristics of each area in the city, such as office districts and residential areas, by employing an area embedding technique that utilizes location information typically obtained by GPS. Numerous area embedding techniques have been proposed, and while the public release of such embedding datasets is technically feasible, it has not been realized. One of the obstacles has been the integration of data from different cities and periods into a unified space without sharing raw location data. We address this issue by developing an anchoring method that establishes anchors within a shared embedding space. We publicly release this anchor dataset along with area embedding datasets from several periods in eight major Japanese cities. This dataset allows users to analyze urban usage patterns in Japanese cities and embed their urban dataset into the same embedding space using the anchoring method. Our key contributions include the development of the anchoring method, releasing area embedding datasets for Japanese cities, and providing tools for effective data utilization.
Area Modeling using Stay Information for Large-Scale Users and Analysis for Influence of COVID-19
Jan 19, 2024Understanding how people use area in a city can be a valuable information in a wide range of fields, from marketing to urban planning. Area usage is subject to change over time due to various events including seasonal shifts and pandemics. Before the spread of smartphones, this data had been collected through questionnaire survey. However, this is not a sustainable approach in terms of time to results and cost. There are many existing studies on area modeling, which characterize an area with some kind of information, using Point of Interest (POI) or inter-area movement data. However, since POI is data that is statically tied to space, and inter-area movement data ignores the behavior of people within an area, existing methods are not sufficient in terms of capturing area usage changes. In this paper, we propose a novel area modeling method named Area2Vec, inspired by Word2Vec, which models areas based on people's location data. This method is based on the discovery that it is possible to characterize an area based on its usage by using people's stay information in the area. And it is a novel method that can reflect the dynamically changing people's behavior in an area in the modeling results. We validated Area2vec by performing a functional classification of areas in a district of Japan. The results show that Area2Vec can be usable in general area analysis. We also investigated area usage changes due to COVID-19 in two districts in Japan. We could find that COVID-19 made people refrain from unnecessary going out, such as visiting entertainment areas.
IRIS: Interpretable Rubric-Informed Segmentation for Action Quality Assessment
Mar 16, 2023


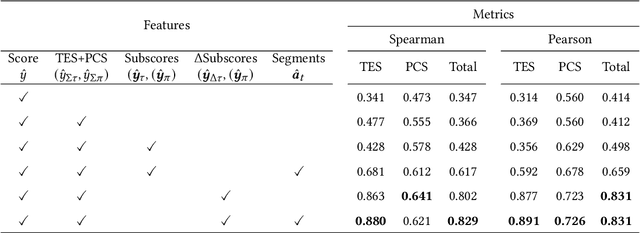
AI-driven Action Quality Assessment (AQA) of sports videos can mimic Olympic judges to help score performances as a second opinion or for training. However, these AI methods are uninterpretable and do not justify their scores, which is important for algorithmic accountability. Indeed, to account for their decisions, instead of scoring subjectively, sports judges use a consistent set of criteria - rubric - on multiple actions in each performance sequence. Therefore, we propose IRIS to perform Interpretable Rubric-Informed Segmentation on action sequences for AQA. We investigated IRIS for scoring videos of figure skating performance. IRIS predicts (1) action segments, (2) technical element score differences of each segment relative to base scores, (3) multiple program component scores, and (4) the summed final score. In a modeling study, we found that IRIS performs better than non-interpretable, state-of-the-art models. In a formative user study, practicing figure skaters agreed with the rubric-informed explanations, found them useful, and trusted AI judgments more. This work highlights the importance of using judgment rubrics to account for AI decisions.
Scale Estimation of Monocular SfM for a Multi-modal Stereo Camera
Oct 28, 2018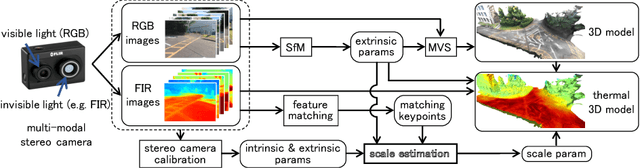
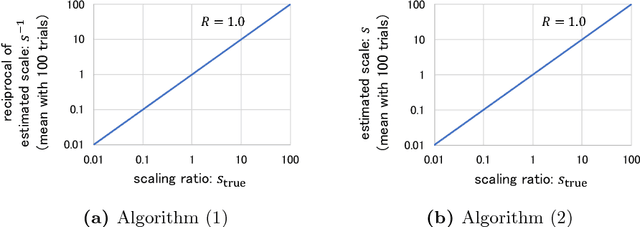
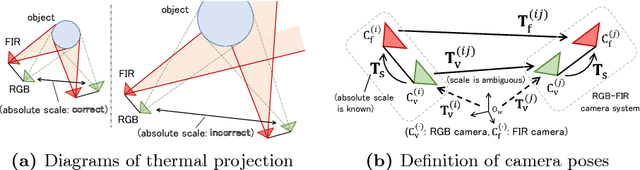
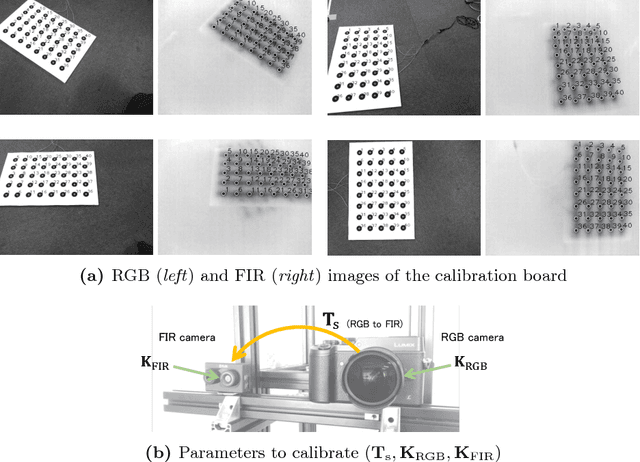
This paper proposes a novel method of estimating the absolute scale of monocular SfM for a multi-modal stereo camera. In the fields of computer vision and robotics, scale estimation for monocular SfM has been widely investigated in order to simplify systems. This paper addresses the scale estimation problem for a stereo camera system in which two cameras capture different spectral images (e.g., RGB and FIR), whose feature points are difficult to directly match using descriptors. Furthermore, the number of matching points between FIR images can be comparatively small, owing to the low resolution and lack of thermal scene texture. To cope with these difficulties, the proposed method estimates the scale parameter using batch optimization, based on the epipolar constraint of a small number of feature correspondences between the invisible light images. The accuracy and numerical stability of the proposed method are verified by synthetic and real image experiments.
Dense Optical Flow based Change Detection Network Robust to Difference of Camera Viewpoints
Dec 08, 2017


This paper presents a novel method for detecting scene changes from a pair of images with a difference of camera viewpoints using a dense optical flow based change detection network. In the case that camera poses of input images are fixed or known, such as with surveillance and satellite cameras, the pixel correspondence between the images captured at different times can be known. Hence, it is possible to comparatively accurately detect scene changes between the images by modeling the appearance of the scene. On the other hand, in case of cameras mounted on a moving object, such as ground and aerial vehicles, we must consider the spatial correspondence between the images captured at different times. However, it can be difficult to accurately estimate the camera pose or 3D model of a scene, owing to the scene changes or lack of imagery. To solve this problem, we propose a change detection convolutional neural network utilizing dense optical flow between input images to improve the robustness to the difference between camera viewpoints. Our evaluation based on the panoramic change detection dataset shows that the proposed method outperforms state-of-the-art change detection algorithms.
Filmy Cloud Removal on Satellite Imagery with Multispectral Conditional Generative Adversarial Nets
Oct 13, 2017


In this paper, we propose a method for cloud removal from visible light RGB satellite images by extending the conditional Generative Adversarial Networks (cGANs) from RGB images to multispectral images. Satellite images have been widely utilized for various purposes, such as natural environment monitoring (pollution, forest or rivers), transportation improvement and prompt emergency response to disasters. However, the obscurity caused by clouds makes it unstable to monitor the situation on the ground with the visible light camera. Images captured by a longer wavelength are introduced to reduce the effects of clouds. Synthetic Aperture Radar (SAR) is such an example that improves visibility even the clouds exist. On the other hand, the spatial resolution decreases as the wavelength increases. Furthermore, the images captured by long wavelengths differs considerably from those captured by visible light in terms of their appearance. Therefore, we propose a network that can remove clouds and generate visible light images from the multispectral images taken as inputs. This is achieved by extending the input channels of cGANs to be compatible with multispectral images. The networks are trained to output images that are close to the ground truth using the images synthesized with clouds over the ground truth as inputs. In the available dataset, the proportion of images of the forest or the sea is very high, which will introduce bias in the training dataset if uniformly sampled from the original dataset. Thus, we utilize the t-Distributed Stochastic Neighbor Embedding (t-SNE) to improve the problem of bias in the training dataset. Finally, we confirm the feasibility of the proposed network on the dataset of four bands images, which include three visible light bands and one near-infrared (NIR) band.
Reflectance Intensity Assisted Automatic and Accurate Extrinsic Calibration of 3D LiDAR and Panoramic Camera Using a Printed Chessboard
Aug 18, 2017

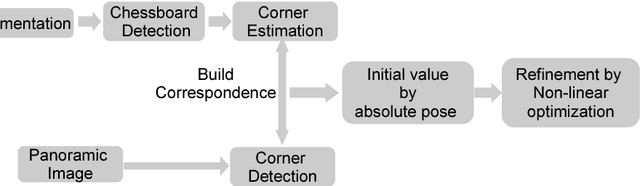

This paper presents a novel method for fully automatic and convenient extrinsic calibration of a 3D LiDAR and a panoramic camera with a normally printed chessboard. The proposed method is based on the 3D corner estimation of the chessboard from the sparse point cloud generated by one frame scan of the LiDAR. To estimate the corners, we formulate a full-scale model of the chessboard and fit it to the segmented 3D points of the chessboard. The model is fitted by optimizing the cost function under constraints of correlation between the reflectance intensity of laser and the color of the chessboard's patterns. Powell's method is introduced for resolving the discontinuity problem in optimization. The corners of the fitted model are considered as the 3D corners of the chessboard. Once the corners of the chessboard in the 3D point cloud are estimated, the extrinsic calibration of the two sensors is converted to a 3D-2D matching problem. The corresponding 3D-2D points are used to calculate the absolute pose of the two sensors with Unified Perspective-n-Point (UPnP). Further, the calculated parameters are regarded as initial values and are refined using the Levenberg-Marquardt method. The performance of the proposed corner detection method from the 3D point cloud is evaluated using simulations. The results of experiments, conducted on a Velodyne HDL-32e LiDAR and a Ladybug3 camera under the proposed re-projection error metric, qualitatively and quantitatively demonstrate the accuracy and stability of the final extrinsic calibration parameters.
* 20 pages, submitted to the journal of Remote Sensing