 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Tracking as Attention Mechanism
Jul 12, 2023



We propose a conceptually simple and thus fast multi-object tracking (MOT) model that does not require any attached modules, such as the Kalman filter, Hungarian algorithm, transformer blocks, or graph networks. Conventional MOT models are built upon the multi-step modules listed above, and thus the computational cost is high. Our proposed end-to-end MOT model, \textit{TicrossNet}, is composed of a base detector and a cross-attention module only. As a result, the overhead of tracking does not increase significantly even when the number of instances ($N_t$) increases. We show that TicrossNet runs \textit{in real-time}; specifically, it achieves 32.6 FPS on MOT17 and 31.0 FPS on MOT20 (Tesla V100), which includes as many as $>$100 instances per frame. We also demonstrate that TicrossNet is robust to $N_t$; thus, it does not have to change the size of the base detector, depending on $N_t$, as is often done by other models for real-time processing.
Visual Explanation of Deep Q-Network for Robot Navigation by Fine-tuning Attention Branch
Aug 18, 2022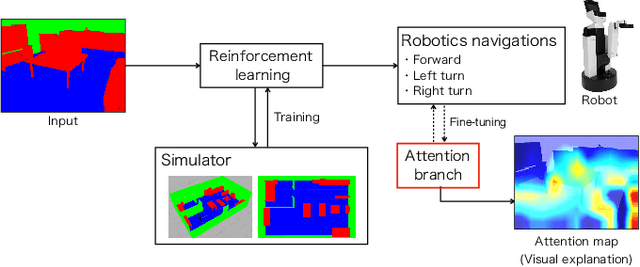
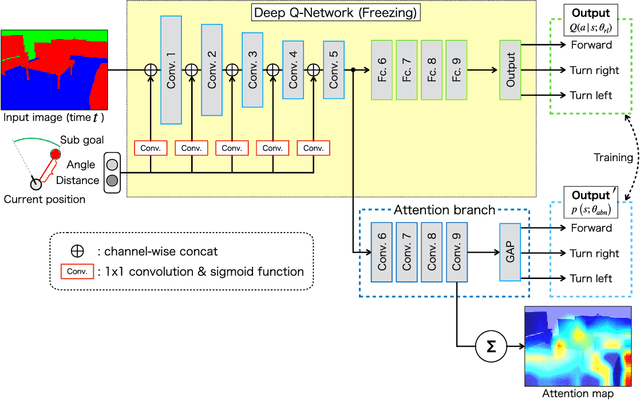
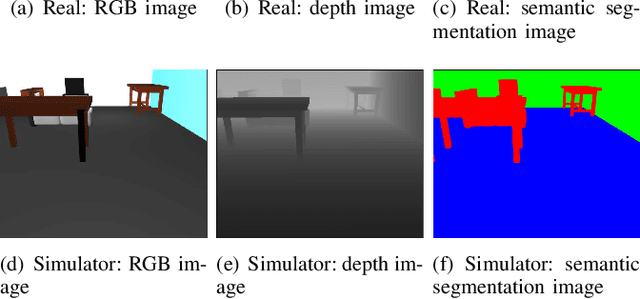

Robot navigation with deep reinforcement learning (RL) achieves higher performance and performs well under complex environment. Meanwhile, the interpretation of the decision-making of deep RL models becomes a critical problem for more safety and reliability of autonomous robots. In this paper, we propose a visual explanation method based on an attention branch for deep RL models. We connect attention branch with pre-trained deep RL model and the attention branch is trained by using the selected action by the trained deep RL model as a correct label in a supervised learning manner. Because the attention branch is trained to output the same result as the deep RL model, the obtained attention maps are corresponding to the agent action with higher interpretability. Experimental results with robot navigation task show that the proposed method can generate interpretable attention maps for a visual explanation.
Embedding Human Knowledge in Deep Neural Network via Attention Map
May 09, 2019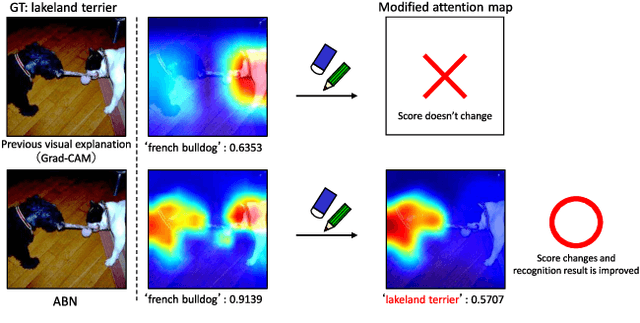
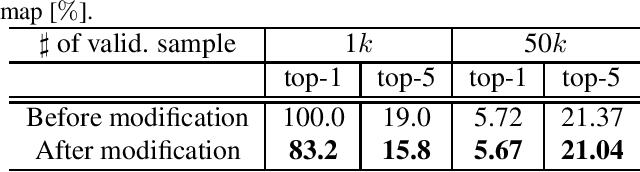
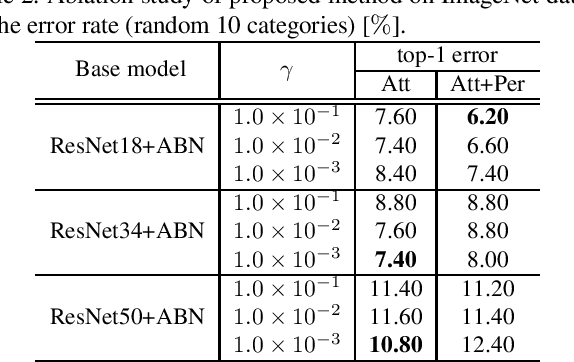
Human-in-the-loop (HITL), which introduces human knowledge to machine learning, has been used in fine-grained recognition to estimate categories from the difference of local features. The conventional HITL approach has been successfully applied in non-deep machine learning, but it is difficult to use it with deep learning due to the enormous number of model parameters. To tackle this problem, in this paper, we propose using the Attention Branch Network (ABN) which is a visual explanation model. ABN applies an attention map for visual explanation to an attention mechanism. First, we manually modify the attention map obtained from ABN on the basis of human knowledge. Then, we use the modified attention map to an attention mechanism that enables ABN to adjust the recognition score. Second, for applying HITL to deep learning, we propose a fine-tuning approach that uses the modified attention map. Our fine-tuning updates the attention and perception branches of the ABN by using the training loss calculated from the attention map output from the ABN along with the modified attention map. This fine-tuning enables the ABN to output an attention map corresponding to human knowledge. Additionally, we use the updated attention map with its embedded human knowledge as an attention mechanism and inference at the perception branch, which improves the performance of ABN. Experimental results with the ImageNet dataset, CUB-200-2010 dataset, and IDRiD demonstrate that our approach clarifies the attention map in terms of visual explanation and improves the classification performance.
Attention Branch Network: Learning of Attention Mechanism for Visual Explanation
Dec 25, 2018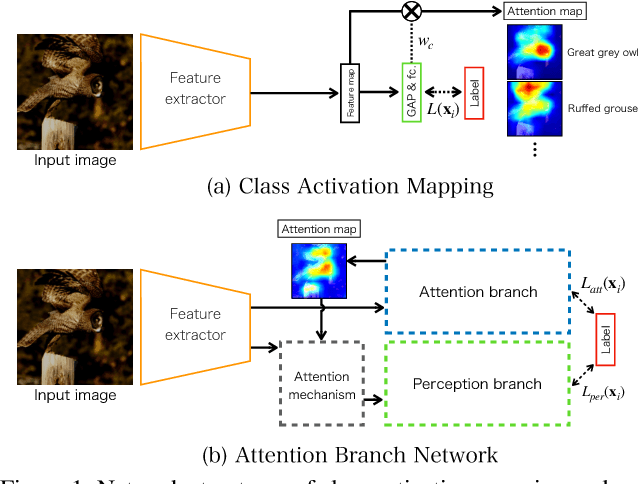
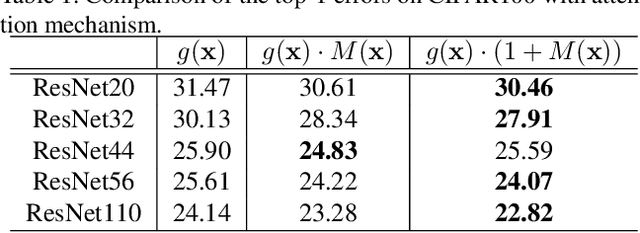
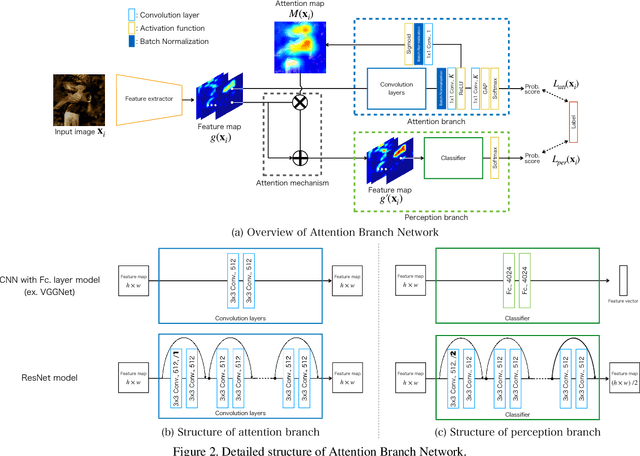
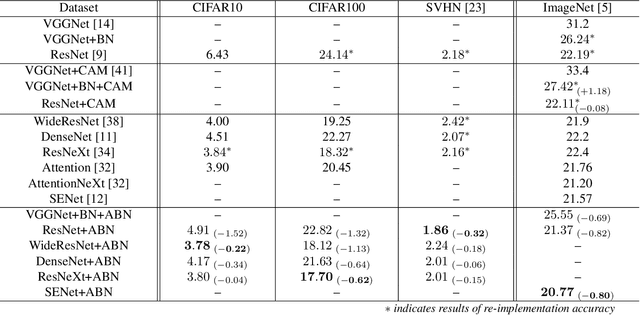
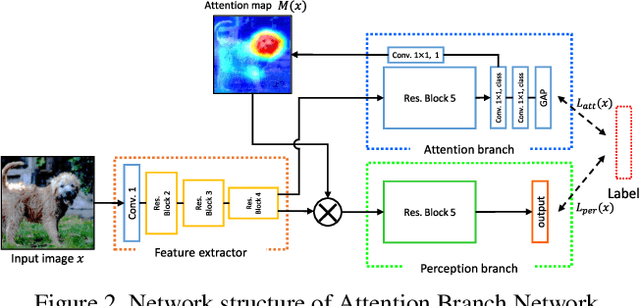
Visual explanation enables human to understand the decision making of Deep Convolutional Neural Network~(CNN), but it is insufficient to contribute the performance improvement. In this paper, we focus on the attention map for visual explanation, which represents high response value as the important region in image recognition. This region significantly improves the performance of CNN by introducing an attention mechanism that focuses on a specific region in an image. In this work, we propose Attention Branch Network~(ABN), which extends the top-down visual explanation model by introducing a branch structure with an attention mechanism. ABN can be applicable to several image recognition tasks by introducing a branch for attention mechanism and is trainable for the visual explanation and image recognition in end-to-end manner. We evaluate ABN on several image recognition tasks such as image classification, fine-grained recognition, and multiple facial attributes recognition. Experimental results show that ABN can outperform the accuracy of baseline models on these image recognition tasks while generating an attention map for visual explanation. Our code is availablehttps://github.com/machine-perception-robotics-group/attention_branch_network.
Filmy Cloud Removal on Satellite Imagery with Multispectral Conditional Generative Adversarial Nets
Oct 13, 2017
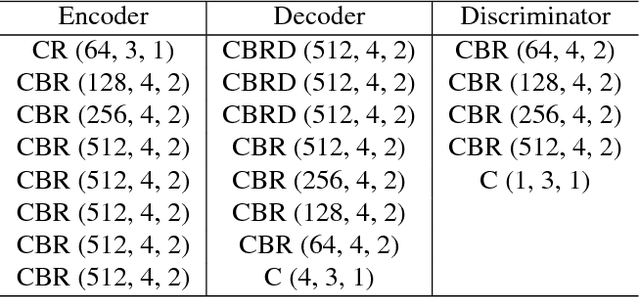


In this paper, we propose a method for cloud removal from visible light RGB satellite images by extending the conditional Generative Adversarial Networks (cGANs) from RGB images to multispectral images. Satellite images have been widely utilized for various purposes, such as natural environment monitoring (pollution, forest or rivers), transportation improvement and prompt emergency response to disasters. However, the obscurity caused by clouds makes it unstable to monitor the situation on the ground with the visible light camera. Images captured by a longer wavelength are introduced to reduce the effects of clouds. Synthetic Aperture Radar (SAR) is such an example that improves visibility even the clouds exist. On the other hand, the spatial resolution decreases as the wavelength increases. Furthermore, the images captured by long wavelengths differs considerably from those captured by visible light in terms of their appearance. Therefore, we propose a network that can remove clouds and generate visible light images from the multispectral images taken as inputs. This is achieved by extending the input channels of cGANs to be compatible with multispectral images. The networks are trained to output images that are close to the ground truth using the images synthesized with clouds over the ground truth as inputs. In the available dataset, the proportion of images of the forest or the sea is very high, which will introduce bias in the training dataset if uniformly sampled from the original dataset. Thus, we utilize the t-Distributed Stochastic Neighbor Embedding (t-SNE) to improve the problem of bias in the training dataset. Finally, we confirm the feasibility of the proposed network on the dataset of four bands images, which include three visible light bands and one near-infrared (NIR) band.