 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Tracking as Attention Mechanism
Jul 12, 2023



We propose a conceptually simple and thus fast multi-object tracking (MOT) model that does not require any attached modules, such as the Kalman filter, Hungarian algorithm, transformer blocks, or graph networks. Conventional MOT models are built upon the multi-step modules listed above, and thus the computational cost is high. Our proposed end-to-end MOT model, \textit{TicrossNet}, is composed of a base detector and a cross-attention module only. As a result, the overhead of tracking does not increase significantly even when the number of instances ($N_t$) increases. We show that TicrossNet runs \textit{in real-time}; specifically, it achieves 32.6 FPS on MOT17 and 31.0 FPS on MOT20 (Tesla V100), which includes as many as $>$100 instances per frame. We also demonstrate that TicrossNet is robust to $N_t$; thus, it does not have to change the size of the base detector, depending on $N_t$, as is often done by other models for real-time processing.
An Empirical Study of the Effects of Sample-Mixing Methods for Efficient Training of Generative Adversarial Networks
Apr 08, 2021
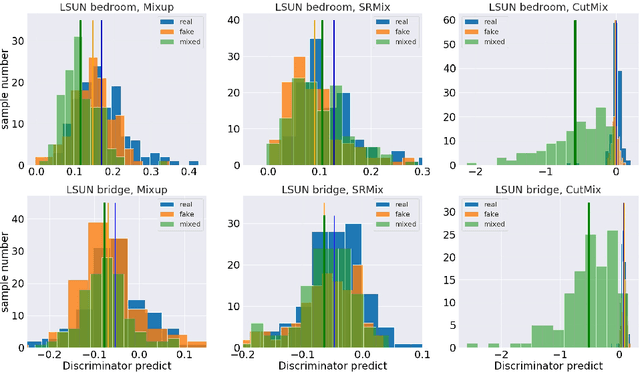
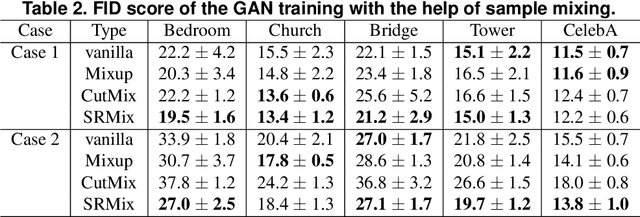
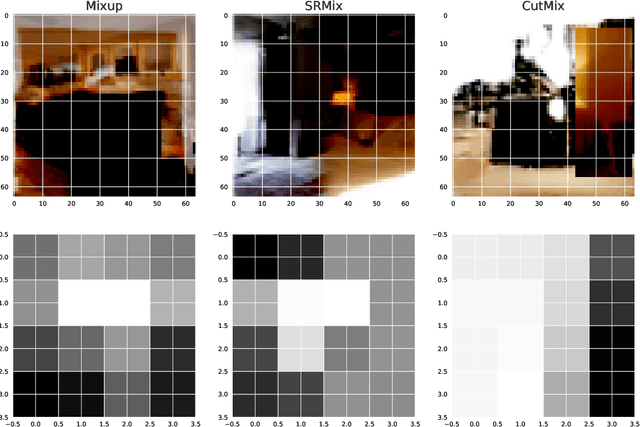
It is well-known that training of generative adversarial networks (GANs) requires huge iterations before the generator's providing good-quality samples. Although there are several studies to tackle this problem, there is still no universal solution. In this paper, we investigated the effect of sample mixing methods, that is, Mixup, CutMix, and newly proposed Smoothed Regional Mix (SRMix), to alleviate this problem. The sample-mixing methods are known to enhance the accuracy and robustness in the wide range of classification problems, and can naturally be applicable to GANs because the role of the discriminator can be interpreted as the classification between real and fake samples. We also proposed a new formalism applying the sample-mixing methods to GANs with the saturated losses which do not have a clear "label" of real and fake. We performed a vast amount of numerical experiments using LSUN and CelebA datasets. The results showed that Mixup and SRMix improved the quality of the generated images in terms of FID in most cases, in particular, SRMix showed the best improvement in most cases. Our analysis indicates that the mixed-samples can provide different properties from the vanilla fake samples, and the mixing pattern strongly affects the decision of the discriminators. The generated images of Mixup have good high-level feature but low-level feature is not so impressible. On the other hand, CutMix showed the opposite tendency. Our SRMix showed the middle tendency, that is, showed good high and low level features. We believe that our finding provides a new perspective to accelerate the GANs convergence and improve the quality of generated samples.
An Efficient Method of Training Small Models for Regression Problems with Knowledge Distillation
Feb 28, 2020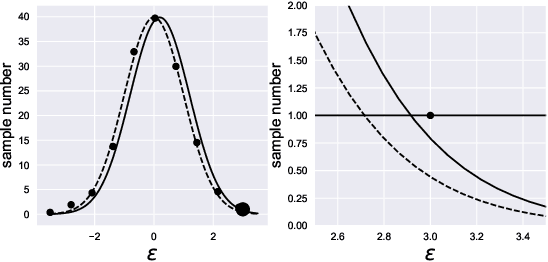

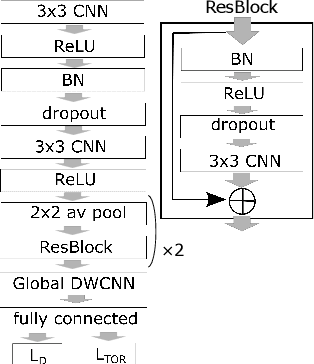

Compressing deep neural network (DNN) models becomes a very important and necessary technique for real-world applications, such as deploying those models on mobile devices. Knowledge distillation is one of the most popular methods for model compression, and many studies have been made on developing this technique. However, those studies mainly focused on classification problems, and very few attempts have been made on regression problems, although there are many application of DNNs on regression problems. In this paper, we propose a new formalism of knowledge distillation for regression problems. First, we propose a new loss function, teacher outlier rejection loss, which rejects outliers in training samples using teacher model predictions. Second, we consider a multi-task network with two outputs: one estimates training labels which is in general contaminated by noisy labels; And the other estimates teacher model's output which is expected to modify the noise labels following the memorization effects. By considering the multi-task network, training of the feature extraction of student models becomes more effective, and it allows us to obtain a better student model than one trained from scratch. We performed comprehensive evaluation with one simple toy model: sinusoidal function, and two open datasets: MPIIGaze, and Multi-PIE. Our results show consistent improvement in accuracy regardless of the annotation error level in the datasets.