 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Optimal Stopping for Early Classification within Finite Horizons via Sequential Probability Ratio Test
Jan 29, 2025



Time-sensitive machine learning benefits from Sequential Probability Ratio Test (SPRT), which provides an optimal stopping time for early classification of time series. However, in finite horizon scenarios, where input lengths are finite, determining the optimal stopping rule becomes computationally intensive due to the need for backward induction, limiting practical applicability. We thus introduce FIRMBOUND, an SPRT-based framework that efficiently estimates the solution to backward induction from training data, bridging the gap between optimal stopping theory and real-world deployment. It employs density ratio estimation and convex function learning to provide statistically consistent estimators for sufficient statistic and conditional expectation, both essential for solving backward induction; consequently, FIRMBOUND minimizes Bayes risk to reach optimality. Additionally, we present a faster alternative using Gaussian process regression, which significantly reduces training time while retaining low deployment overhead, albeit with potential compromise in statistical consistency. Experiments across independent and identically distributed (i.i.d.), non-i.i.d., binary, multiclass, synthetic, and real-world datasets show that FIRMBOUND achieves optimalities in the sense of Bayes risk and speed-accuracy tradeoff. Furthermore, it advances the tradeoff boundary toward optimality when possible and reduces decision-time variance, ensuring reliable decision-making. Code is publicly available at https://github.com/Akinori-F-Ebihara/FIRMBOUND
U-FaceBP: Uncertainty-aware Bayesian Ensemble Deep Learning for Face Video-based Blood Pressure Measurement
Dec 14, 2024



Blood pressure (BP) measurement plays an essential role in assessing health on a daily basis. Remote photoplethysmography (rPPG), which extracts pulse waves from camera-captured face videos, has the potential to easily measure BP for daily health monitoring. However, there are many uncertainties in BP estimation using rPPG, resulting in limited estimation performance. In this paper, we propose U-FaceBP, an uncertainty-aware Bayesian ensemble deep learning method for face video-based BP measurement. U-FaceBP models three types of uncertainty, i.e., data, model, and ensemble uncertainties, in face video-based BP estimation with a Bayesian neural network (BNN). We also design U-FaceBP as an ensemble method, with which BP is estimated from rPPG signals, PPG signals estimated from face videos, and face images using multiple BNNs. A large-scale experiment with 786 subjects demonstrates that U-FaceBP outperforms state-of-the-art BP estimation methods. We also show that the uncertainties estimated from U-FaceBP are reasonable and useful for prediction confidence.
ComFace: Facial Representation Learning with Synthetic Data for Comparing Faces
May 25, 2024



Daily monitoring of intra-personal facial changes associated with health and emotional conditions has great potential to be useful for medical, healthcare, and emotion recognition fields. However, the approach for capturing intra-personal facial changes is relatively unexplored due to the difficulty of collecting temporally changing face images. In this paper, we propose a facial representation learning method using synthetic images for comparing faces, called ComFace, which is designed to capture intra-personal facial changes. For effective representation learning, ComFace aims to acquire two feature representations, i.e., inter-personal facial differences and intra-personal facial changes. The key point of our method is the use of synthetic face images to overcome the limitations of collecting real intra-personal face images. Facial representations learned by ComFace are transferred to three extensive downstream tasks for comparing faces: estimating facial expression changes, weight changes, and age changes from two face images of the same individual. Our ComFace, trained using only synthetic data, achieves comparable to or better transfer performance than general pre-training and state-of-the-art representation learning methods trained using real images.
CalibrationPhys: Self-supervised Video-based Heart and Respiratory Rate Measurements by Calibrating Between Multiple Cameras
Oct 23, 2023



Video-based heart and respiratory rate measurements using facial videos are more useful and user-friendly than traditional contact-based sensors. However, most of the current deep learning approaches require ground-truth pulse and respiratory waves for model training, which are expensive to collect. In this paper, we propose CalibrationPhys, a self-supervised video-based heart and respiratory rate measurement method that calibrates between multiple cameras. CalibrationPhys trains deep learning models without supervised labels by using facial videos captured simultaneously by multiple cameras. Contrastive learning is performed so that the pulse and respiratory waves predicted from the synchronized videos using multiple cameras are positive and those from different videos are negative. CalibrationPhys also improves the robustness of the models by means of a data augmentation technique and successfully leverages a pre-trained model for a particular camera. Experimental results utilizing two datasets demonstrate that CalibrationPhys outperforms state-of-the-art heart and respiratory rate measurement methods. Since we optimize camera-specific models using only videos from multiple cameras, our approach makes it easy to use arbitrary cameras for heart and respiratory rate measurements.
Toward Asymptotic Optimality: Sequential Unsupervised Regression of Density Ratio for Early Classification
Feb 20, 2023



Theoretically-inspired sequential density ratio estimation (SDRE) algorithms are proposed for the early classification of time series. Conventional SDRE algorithms can fail to estimate DRs precisely due to the internal overnormalization problem, which prevents the DR-based sequential algorithm, Sequential Probability Ratio Test (SPRT), from reaching its asymptotic Bayes optimality. Two novel SPRT-based algorithms, B2Bsqrt-TANDEM and TANDEMformer, are designed to avoid the overnormalization problem for precise unsupervised regression of SDRs. The two algorithms statistically significantly reduce DR estimation errors and classification errors on an artificial sequential Gaussian dataset and real datasets (SiW, UCF101, and HMDB51), respectively. The code is available at: https://github.com/Akinori-F-Ebihara/LLR_saturation_problem.
Edema Estimation From Facial Images Taken Before and After Dialysis via Contrastive Multi-Patient Pre-Training
Dec 15, 2022



Edema is a common symptom of kidney disease, and quantitative measurement of edema is desired. This paper presents a method to estimate the degree of edema from facial images taken before and after dialysis of renal failure patients. As tasks to estimate the degree of edema, we perform pre- and post-dialysis classification and body weight prediction. We develop a multi-patient pre-training framework for acquiring knowledge of edema and transfer the pre-trained model to a model for each patient. For effective pre-training, we propose a novel contrastive representation learning, called weight-aware supervised momentum contrast (WeightSupMoCo). WeightSupMoCo aims to make feature representations of facial images closer in similarity of patient weight when the pre- and post-dialysis labels are the same. Experimental results show that our pre-training approach improves the accuracy of pre- and post-dialysis classification by 15.1% and reduces the mean absolute error of weight prediction by 0.243 kg compared with training from scratch. The proposed method accurately estimate the degree of edema from facial images; our edema estimation system could thus be beneficial to dialysis patients.
* Published in IEEE Journal of Biomedical and Health Informatics (J-BHI)
Blood Oxygen Saturation Estimation from Facial Video via DC and AC components of Spatio-temporal Map
Dec 14, 2022



Peripheral blood oxygen saturation (SpO2), an indicator of oxygen levels in the blood, is one of the most important physiological parameters. Although SpO2 is usually measured using a pulse oximeter, non-contact SpO2 estimation methods from facial or hand videos have been attracting attention in recent years. In this paper, we propose an SpO2 estimation method from facial videos based on convolutional neural networks (CNN). Our method constructs CNN models that consider the direct current (DC) and alternating current (AC) components extracted from the RGB signals of facial videos, which are important in the principle of SpO2 estimation. Specifically, we extract the DC and AC components from the spatio-temporal map using filtering processes and train CNN models to predict SpO2 from these components. We also propose an end-to-end model that predicts SpO2 directly from the spatio-temporal map by extracting the DC and AC components via convolutional layers. Experiments using facial videos and SpO2 data from 50 subjects demonstrate that the proposed method achieves a better estimation performance than current state-of-the-art SpO2 estimation methods.
Joint Feature Distribution Alignment Learning for NIR-VIS and VIS-VIS Face Recognition
Apr 25, 2022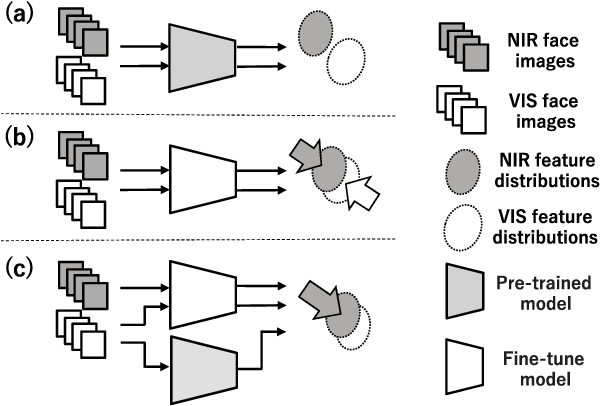



Face recognition for visible light (VIS) images achieve high accuracy thanks to the recent development of deep learning. However, heterogeneous face recognition (HFR), which is a face matching in different domains, is still a difficult task due to the domain discrepancy and lack of large HFR dataset. Several methods have attempted to reduce the domain discrepancy by means of fine-tuning, which causes significant degradation of the performance in the VIS domain because it loses the highly discriminative VIS representation. To overcome this problem, we propose joint feature distribution alignment learning (JFDAL) which is a joint learning approach utilizing knowledge distillation. It enables us to achieve high HFR performance with retaining the original performance for the VIS domain. Extensive experiments demonstrate that our proposed method delivers statistically significantly better performances compared with the conventional fine-tuning approach on a public HFR dataset Oulu-CASIA NIR&VIS and popular verification datasets in VIS domain such as FLW, CFP, AgeDB. Furthermore, comparative experiments with existing state-of-the-art HFR methods show that our method achieves a comparable HFR performance on the Oulu-CASIA NIR&VIS dataset with less degradation of VIS performance.
* 8 pages, 5 figures. Accepted at IJCB 2021
Deep Neural Networks for the Sequential Probability Ratio Test on Non-i.i.d. Data Series
Jun 17, 2020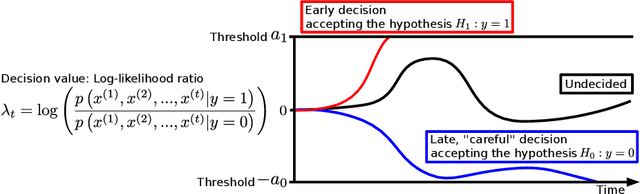
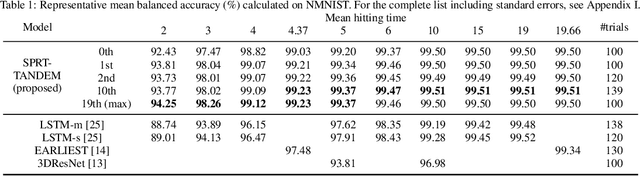

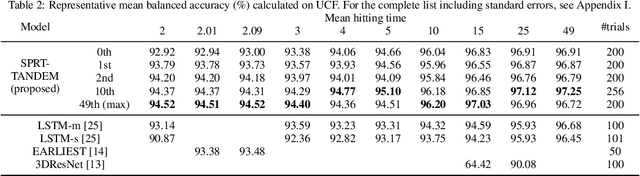
Classifying sequential data as early as and as accurately as possible is a challenging yet critical problem, especially when a sampling cost is high. One algorithm that achieves this goal is the sequential probability ratio test (SPRT), which is known as Bayes-optimal: it can keep the expected number of data samples as small as possible, given the desired error upper-bound. The SPRT has recently been found to be the best model that explains the activities of the neurons in the primate parietal cortex that are thought to mediate our complex decision-making processes. However, the original SPRT makes two critical assumptions that limit its application in real-world scenarios: (i) samples are independently and identically distributed, and (ii) the likelihood of the data being derived from each class can be calculated precisely. Here, we propose the SPRT-TANDEM, a deep neural network-based SPRT algorithm that overcomes the above two obstacles. The SPRT-TANDEM estimates the log-likelihood ratio of two alternative hypotheses by leveraging a novel Loss function for Log-Likelihood Ratio estimation (LLLR), while allowing for correlations up to $N (\in \mathbb{N})$ preceding samples. In tests on one original and two public video databases, Nosaic MNIST, UCF101, and SiW, the SPRT-TANDEM achieves statistically significantly better classification accuracy than other baseline classifiers, with a smaller number of data samples. The code and Nosaic MNIST are publicly available at https://github.com/TaikiMiyagawa/SPRT-TANDEM.
An Efficient Method of Training Small Models for Regression Problems with Knowledge Distillation
Feb 28, 2020


Compressing deep neural network (DNN) models becomes a very important and necessary technique for real-world applications, such as deploying those models on mobile devices. Knowledge distillation is one of the most popular methods for model compression, and many studies have been made on developing this technique. However, those studies mainly focused on classification problems, and very few attempts have been made on regression problems, although there are many application of DNNs on regression problems. In this paper, we propose a new formalism of knowledge distillation for regression problems. First, we propose a new loss function, teacher outlier rejection loss, which rejects outliers in training samples using teacher model predictions. Second, we consider a multi-task network with two outputs: one estimates training labels which is in general contaminated by noisy labels; And the other estimates teacher model's output which is expected to modify the noise labels following the memorization effects. By considering the multi-task network, training of the feature extraction of student models becomes more effective, and it allows us to obtain a better student model than one trained from scratch. We performed comprehensive evaluation with one simple toy model: sinusoidal function, and two open datasets: MPIIGaze, and Multi-PIE. Our results show consistent improvement in accuracy regardless of the annotation error level in the datasets.