 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Backbone in Class Imbalanced Federated Source Free Domain Adaptation: The Utility of Vision Foundation Models
Sep 10, 2025Federated Learning (FL) offers a framework for training models collaboratively while preserving data privacy of each client. Recently, research has focused on Federated Source-Free Domain Adaptation (FFREEDA), a more realistic scenario wherein client-held target domain data remains unlabeled, and the server can access source domain data only during pre-training. We extend this framework to a more complex and realistic setting: Class Imbalanced FFREEDA (CI-FFREEDA), which takes into account class imbalances in both the source and target domains, as well as label shifts between source and target and among target clients. The replication of existing methods in our experimental setup lead us to rethink the focus from enhancing aggregation and domain adaptation methods to improving the feature extractors within the network itself. We propose replacing the FFREEDA backbone with a frozen vision foundation model (VFM), thereby improving overall accuracy without extensive parameter tuning and reducing computational and communication costs in federated learning. Our experimental results demonstrate that VFMs effectively mitigate the effects of domain gaps, class imbalances, and even non-IID-ness among target clients, suggesting that strong feature extractors, not complex adaptation or FL methods, are key to success in the real-world FL.
Robust Deepfake Detection for Electronic Know Your Customer Systems Using Registered Images
Jul 30, 2025In this paper, we present a deepfake detection algorithm specifically designed for electronic Know Your Customer (eKYC) systems. To ensure the reliability of eKYC systems against deepfake attacks, it is essential to develop a robust deepfake detector capable of identifying both face swapping and face reenactment, while also being robust to image degradation. We address these challenges through three key contributions: (1)~Our approach evaluates the video's authenticity by detecting temporal inconsistencies in identity vectors extracted by face recognition models, leading to comprehensive detection of both face swapping and face reenactment. (2)~In addition to processing video input, the algorithm utilizes a registered image (assumed to be genuine) to calculate identity discrepancies between the input video and the registered image, significantly improving detection accuracy. (3)~We find that employing a face feature extractor trained on a larger dataset enhances both detection performance and robustness against image degradation. Our experimental results show that our proposed method accurately detects both face swapping and face reenactment comprehensively and is robust against various forms of unseen image degradation. Our source code is publicly available https://github.com/TaikiMiyagawa/DeepfakeDetection4eKYC.
Learning the Optimal Stopping for Early Classification within Finite Horizons via Sequential Probability Ratio Test
Jan 29, 2025



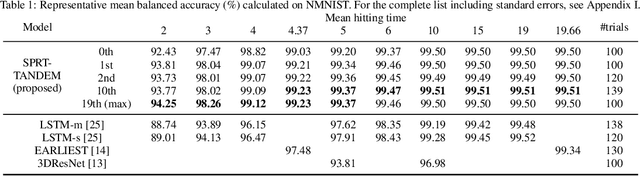
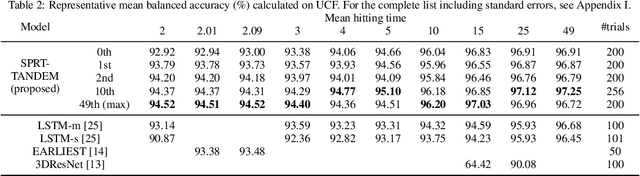
Time-sensitive machine learning benefits from Sequential Probability Ratio Test (SPRT), which provides an optimal stopping time for early classification of time series. However, in finite horizon scenarios, where input lengths are finite, determining the optimal stopping rule becomes computationally intensive due to the need for backward induction, limiting practical applicability. We thus introduce FIRMBOUND, an SPRT-based framework that efficiently estimates the solution to backward induction from training data, bridging the gap between optimal stopping theory and real-world deployment. It employs density ratio estimation and convex function learning to provide statistically consistent estimators for sufficient statistic and conditional expectation, both essential for solving backward induction; consequently, FIRMBOUND minimizes Bayes risk to reach optimality. Additionally, we present a faster alternative using Gaussian process regression, which significantly reduces training time while retaining low deployment overhead, albeit with potential compromise in statistical consistency. Experiments across independent and identically distributed (i.i.d.), non-i.i.d., binary, multiclass, synthetic, and real-world datasets show that FIRMBOUND achieves optimalities in the sense of Bayes risk and speed-accuracy tradeoff. Furthermore, it advances the tradeoff boundary toward optimality when possible and reduces decision-time variance, ensuring reliable decision-making. Code is publicly available at https://github.com/Akinori-F-Ebihara/FIRMBOUND
Federated Source-free Domain Adaptation for Classification: Weighted Cluster Aggregation for Unlabeled Data
Dec 18, 2024



Federated learning (FL) commonly assumes that the server or some clients have labeled data, which is often impractical due to annotation costs and privacy concerns. Addressing this problem, we focus on a source-free domain adaptation task, where (1) the server holds a pre-trained model on labeled source domain data, (2) clients possess only unlabeled data from various target domains, and (3) the server and clients cannot access the source data in the adaptation phase. This task is known as Federated source-Free Domain Adaptation (FFREEDA). Specifically, we focus on classification tasks, while the previous work solely studies semantic segmentation. Our contribution is the novel Federated learning with Weighted Cluster Aggregation (FedWCA) method, designed to mitigate both domain shifts and privacy concerns with only unlabeled data. FedWCA comprises three phases: private and parameter-free clustering of clients to obtain domain-specific global models on the server, weighted aggregation of the global models for the clustered clients, and local domain adaptation with pseudo-labeling. Experimental results show that FedWCA surpasses several existing methods and baselines in FFREEDA, establishing its effectiveness and practicality.
Toward Asymptotic Optimality: Sequential Unsupervised Regression of Density Ratio for Early Classification
Feb 20, 2023



Theoretically-inspired sequential density ratio estimation (SDRE) algorithms are proposed for the early classification of time series. Conventional SDRE algorithms can fail to estimate DRs precisely due to the internal overnormalization problem, which prevents the DR-based sequential algorithm, Sequential Probability Ratio Test (SPRT), from reaching its asymptotic Bayes optimality. Two novel SPRT-based algorithms, B2Bsqrt-TANDEM and TANDEMformer, are designed to avoid the overnormalization problem for precise unsupervised regression of SDRs. The two algorithms statistically significantly reduce DR estimation errors and classification errors on an artificial sequential Gaussian dataset and real datasets (SiW, UCF101, and HMDB51), respectively. The code is available at: https://github.com/Akinori-F-Ebihara/LLR_saturation_problem.
Convolutional Neural Networks for Time-dependent Classification of Variable-length Time Series
Jul 13, 2022
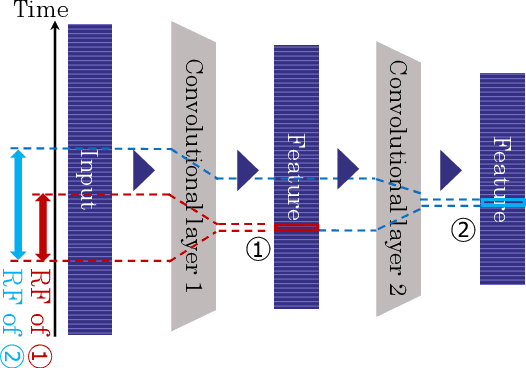
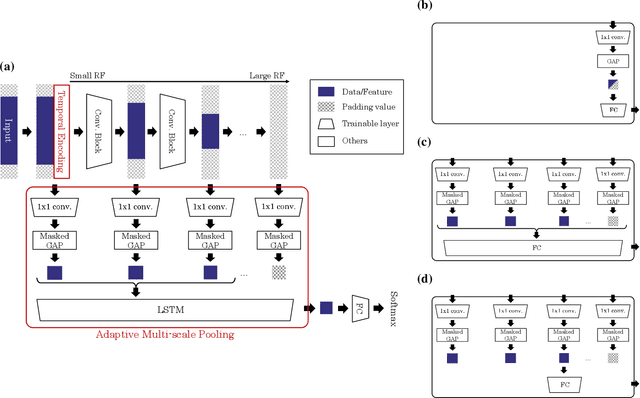
Time series data are often obtained only within a limited time range due to interruptions during observation process. To classify such partial time series, we need to account for 1) the variable-length data drawn from 2) different timestamps. To address the first problem, existing convolutional neural networks use global pooling after convolutional layers to cancel the length differences. This architecture suffers from the trade-off between incorporating entire temporal correlations in long data and avoiding feature collapse for short data. To resolve this tradeoff, we propose Adaptive Multi-scale Pooling, which aggregates features from an adaptive number of layers, i.e., only the first few layers for short data and more layers for long data. Furthermore, to address the second problem, we introduce Temporal Encoding, which embeds the observation timestamps into the intermediate features. Experiments on our private dataset and the UCR/UEA time series archive show that our modules improve classification accuracy especially on short data obtained as partial time series.
Joint Feature Distribution Alignment Learning for NIR-VIS and VIS-VIS Face Recognition
Apr 25, 2022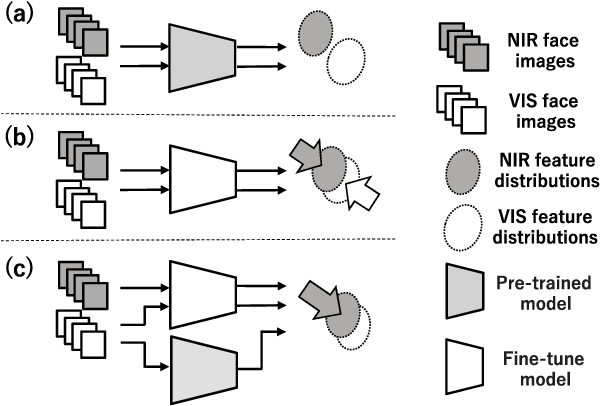



Face recognition for visible light (VIS) images achieve high accuracy thanks to the recent development of deep learning. However, heterogeneous face recognition (HFR), which is a face matching in different domains, is still a difficult task due to the domain discrepancy and lack of large HFR dataset. Several methods have attempted to reduce the domain discrepancy by means of fine-tuning, which causes significant degradation of the performance in the VIS domain because it loses the highly discriminative VIS representation. To overcome this problem, we propose joint feature distribution alignment learning (JFDAL) which is a joint learning approach utilizing knowledge distillation. It enables us to achieve high HFR performance with retaining the original performance for the VIS domain. Extensive experiments demonstrate that our proposed method delivers statistically significantly better performances compared with the conventional fine-tuning approach on a public HFR dataset Oulu-CASIA NIR&VIS and popular verification datasets in VIS domain such as FLW, CFP, AgeDB. Furthermore, comparative experiments with existing state-of-the-art HFR methods show that our method achieves a comparable HFR performance on the Oulu-CASIA NIR&VIS dataset with less degradation of VIS performance.
* 8 pages, 5 figures. Accepted at IJCB 2021
The Power of Log-Sum-Exp: Sequential Density Ratio Matrix Estimation for Speed-Accuracy Optimization
May 31, 2021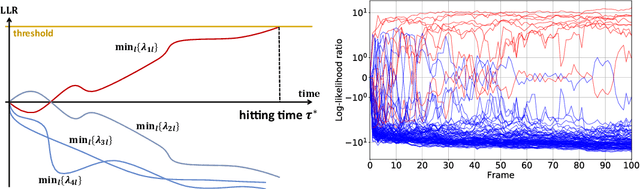



We propose a model for multiclass classification of time series to make a prediction as early and as accurate as possible. The matrix sequential probability ratio test (MSPRT) is known to be asymptotically optimal for this setting, but contains a critical assumption that hinders broad real-world applications; the MSPRT requires the underlying probability density. To address this problem, we propose to solve density ratio matrix estimation (DRME), a novel type of density ratio estimation that consists of estimating matrices of multiple density ratios with constraints and thus is more challenging than the conventional density ratio estimation. We propose a log-sum-exp-type loss function (LSEL) for solving DRME and prove the following: (i) the LSEL provides the true density ratio matrix as the sample size of the training set increases (consistency); (ii) it assigns larger gradients to harder classes (hard class weighting effect); and (iii) it provides discriminative scores even on class-imbalanced datasets (guess-aversion). Our overall architecture for early classification, MSPRT-TANDEM, statistically significantly outperforms baseline models on four datasets including action recognition, especially in the early stage of sequential observations. Our code and datasets are publicly available at: https://github.com/TaikiMiyagawa/MSPRT-TANDEM.
Deep Neural Networks for the Sequential Probability Ratio Test on Non-i.i.d. Data Series
Jun 17, 2020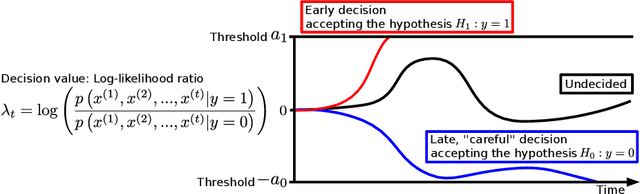

Classifying sequential data as early as and as accurately as possible is a challenging yet critical problem, especially when a sampling cost is high. One algorithm that achieves this goal is the sequential probability ratio test (SPRT), which is known as Bayes-optimal: it can keep the expected number of data samples as small as possible, given the desired error upper-bound. The SPRT has recently been found to be the best model that explains the activities of the neurons in the primate parietal cortex that are thought to mediate our complex decision-making processes. However, the original SPRT makes two critical assumptions that limit its application in real-world scenarios: (i) samples are independently and identically distributed, and (ii) the likelihood of the data being derived from each class can be calculated precisely. Here, we propose the SPRT-TANDEM, a deep neural network-based SPRT algorithm that overcomes the above two obstacles. The SPRT-TANDEM estimates the log-likelihood ratio of two alternative hypotheses by leveraging a novel Loss function for Log-Likelihood Ratio estimation (LLLR), while allowing for correlations up to $N (\in \mathbb{N})$ preceding samples. In tests on one original and two public video databases, Nosaic MNIST, UCF101, and SiW, the SPRT-TANDEM achieves statistically significantly better classification accuracy than other baseline classifiers, with a smaller number of data samples. The code and Nosaic MNIST are publicly available at https://github.com/TaikiMiyagawa/SPRT-TANDEM.
Specular- and Diffuse-reflection-based Face Liveness Detection for Mobile Devices
Jul 29, 2019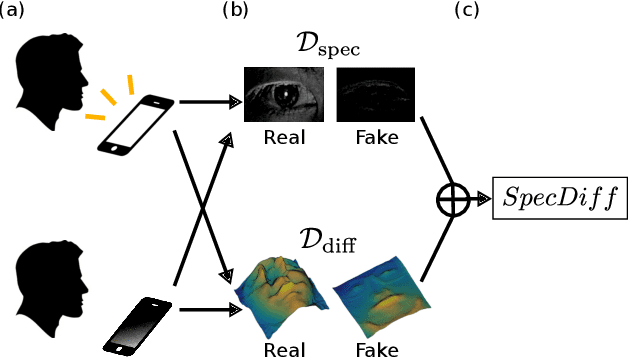
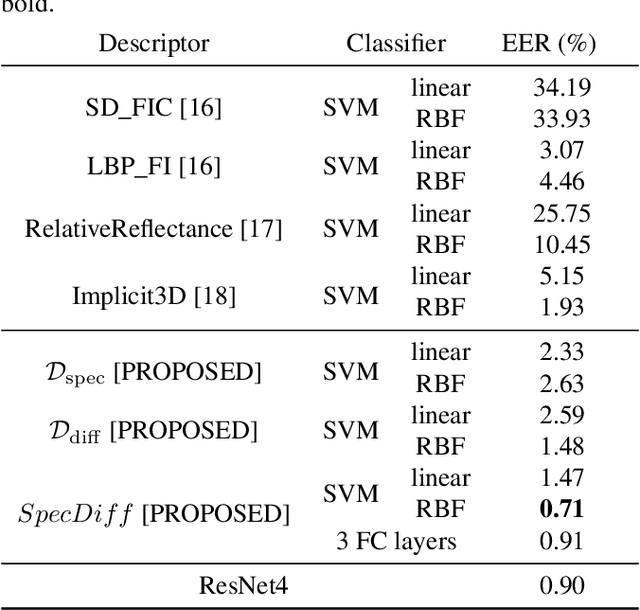
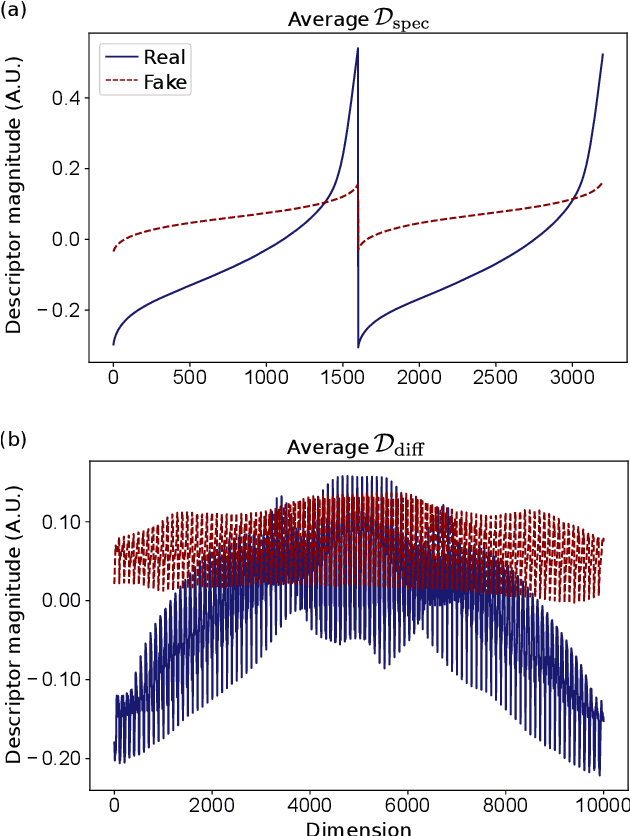
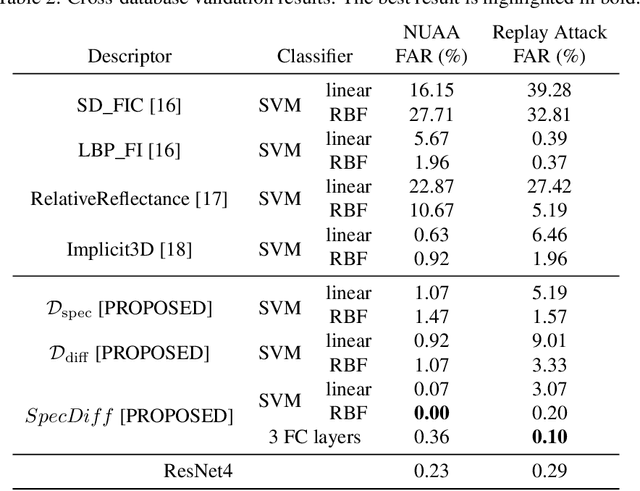
In light of the rising demand for biometric-authentication systems, preventing face spoofing attacks is a critical issue for the safe deployment of face recognition systems. Here, we propose an efficient liveness detection algorithm that requires minimal hardware and only a small database, making it suitable for resource-constrained devices such as mobile phones. Utilizing one monocular visible light camera, the proposed algorithm takes two facial photos, one taken with a flash, the other without a flash. The proposed $SpecDiff$ descriptor is constructed by leveraging two types of reflection: (i) specular reflections from the iris region that have a specific intensity distribution depending on liveness, and (ii) diffuse reflections from the entire face region that represents the 3D structure of a subject's face. Classifiers trained with $SpecDiff$ descriptor outperforms other flash-based liveness detection algorithms on both an in-house database and on publicly available NUAA and Replay-Attack databases. Moreover, the proposed algorithm achieves comparable accuracy to that of an end-to-end, deep neural network classifier, while being approximately ten-times faster execution speed.